Prometheus+grafana
Posted 袁邦臣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus+grafana相关的知识,希望对你有一定的参考价值。
一、Prometheus简介、 容器监控的实现方对比虚拟机或者物理机来说比大的区别,比如容器在k8s环境中可以任意横向扩容与缩容,那么就需要监控服务能够自动对新创建的容器进行监控, 当容器删除后又能够及时的从监控服务中删除,而传统的zabbix的监控方式需要在每一个容器中安装启动agent,并且在容器自动发现注册及模板关联方面并没有比较好的实现方式。 k8s的早期版本基于组件heapster实现对pod和node节点的监控功能,但是从k8s 1.8版本开始使用metrics API的方式监控,并在1.11版本 正式将heapster替换, 后期的k8s监控主要是通过metrics Server提供核心监控指标,比如Node节点的CPU和内存使用率,其他的监控交由另外一个组件Prometheus 完成。 https://prometheus.io/docs/ #官方文档 https://github.com/prometheus #github地址 Prometheus是基于go语言开发的一套开源的监控、报警和时间序列数据库的组合,是由SoundCloud公司开发的开源监控系统, Prometheus是CNCF(Cloud Native Computing Foundation,云原生计算基金会)继kubernetes 之后毕业的第二个项目, prometheus在容器和微服务领域中得到了广泛的应用,其特点主要如下: 使用key-value的多维度格式保存数据 数据不使用MySQL这样的传统数据库,而是使用时序数据库,目前是使用的TSDB 支持第三方dashboard实现更高的图形界面,如grafana(Grafana 2.5.0版本及以上) 功能组件化 不需要依赖存储,数据可以本地保存也可以远程保存 服务自动化发现 强大的数据查询语句功(PromQL,Prometheus Query Language) prometheus系统架构图 prometheus server:主服务,接受外部http请求,收集、存储与查询数据等 prometheus targets: 静态收集的目标服务数据 service discovery:动态发现服务 prometheus alerting:报警通知 pushgateway:数据收集代理服务器(类似于zabbix proxy) data visualization and export: 数据可视化与数据导出(访问客户端)

组件名称和监听端口: prometheus:9090 #主服务,接受外部http请求,收集、存储与查询数据等 node_expoter:9100 #安装在master和node节点上的,主要收集各节点的数据信息 grafana:3000 #可视化展示收集到的数据 cadvisor: 8080 #主要收集各node节点上pod的数据信息工具 alertmanager:9093 #报警服务器,prometheus收到负载信息,转发给alerting,alerting发送邮件,微信 手机等。 haproxy_exporter: 9091 # 相关命令参数 /usr/local/prometheus/prometheus -h --config.file="prometheus.yml" #指定配置文件 --web.listen-address="0.0.0.0:9090" #监听端口 --web.max-connections=512 #默认最大连接数:512 --storage.tsdb.path="data/" #默认的存储路径:data目录下 --storage.tsdb.retention.time=15d #默认的数据保留时间:15天。原有的 --alertmanager.timeout=10s #把报警发送给alertmanager的超时限制 10s --query.timeout=2m #查询超时时间限制默认为2min,超过自动被kill掉。可以结合grafana的限时配置如60s --query.max-concurrency=20 #并发查询数 prometheus的默认采集指标中有一项prometheus_engine_queries_concurrent_max可以拿到最大查询并发数及查询情况
二、prometheus 安装方式几种方式: https://prometheus.io/download/ #官方二进制下载及安装 https://prometheus.io/docs/prometheus/latest/installation/ docker镜像直接启动 https://github.com/coreos/kube-prometheus # operator部署 1、docker镜像直接启动 docker run -p 9090:9090 -v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus docker run -p 9090:9090 prom/prometheus ---------------------------------------------------- 2、官方二进制下载及安装 [root@localhost7I prometheus]# tar xvf prometheus-2.11.1.linux-amd64.tar.gz [root@localhost7I prometheus]# ln -sv /usr/local/src/prometheus-2.11.1.linux-amd64 /usr/local/prometheus #创建prometheus启动脚本: [root@localhost7I prometheus]# cat /etc/systemd/system/prometheus.service [Unit] Description=Prometheus Server Documentation=https://prometheus.io/docs/introduction/overview/ After=network.target [Service] Restart=on-failure WorkingDirectory=/usr/local/prometheus/ ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml [Install] WantedBy=multi-user.target #prometheus配置文件说明 [root@localhost7I prometheus]# vim prometheus.yml global: scrape_interval: 15s #默认情况下抓取目标的频率 evaluation_interval: 15s #评估规则的频率 # 报警配置 alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 #报警服务器地址。 #报警条件,设置告警规则,基于设定什么指标进行报警(类似触发器trigger) rule_files: # - "first_rules.yml" # - "second_rules.yml" 被收集指标的服务器列表。 scrape_configs: - job_name: \'prometheus\' static_configs: - targets: [\'localhost:9090\'] 访问prometheus web界面查看中status-targets

访问prometheus web界面查看中Graph选择相应指标查看

---------------------------------------------------- 3、operator部署 整个项目基本yaml一键部署, 1.下载项目:https://github.com/prometheus-operator [root@localhost7C k8s]# unzip kube-prometheus-release-0.4.zip [root@localhost7C k8s]# cd kube-prometheus-release-0.4/manifests/ [root@localhost7C manifests]# kubectl apply -f ./setup/ [root@localhost7C k8s]# -f manifests/ 设置server里的端口转发,也可以去yaml里添加server端口转发。prometheus-service.yaml grafana-service.yaml Prometheus命令添加端口转发 kubectl --namespace monitoring port-forward --address 0.0.0.0 svc/prometheus-k8s 9090:9090 #kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090 Grafana命令添加端口转发 #kubectl --namespace monitoring port-forward --address 0.0.0.0 svc/grafana 3000:3000 $ kubectl --namespace monitoring port-forward svc/grafana 3000 -----------------------------------------------------
三、各节点安装node expoter,收集各k8s node节点上的监控指标数据,监听端口为9100 1.1 方式一:rpm包 [root@localhost7C local]# tar xvf node_exporter-1.0.0-rc.0.linux-amd64.tar.gz [root@localhost7C local]# ln -sv node_exporter-1.0.0-rc.0.linux-amd64 node_exporter 创建node_exporter启动脚本: [root@localhost7C local]# cat /etc/systemd/system/node-exporter.service [Unit] Description=Prometheus Node Exporter After=network.target [Service] ExecStart=/usr/local/node_exporter/node_exporter [Install] WantedBy=multi-user.target 1.2 方式二:k8s apiVersion: apps/v1 kind: DaemonSet metadata: name: node-exporter namespace: monitor labels: k8s-app: node-exporter spec: selector: matchLabels: k8s-app: node-exporter template: metadata: labels: k8s-app: node-exporter spec: tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master containers: - image: prom/node-exporter:v1.3.1 imagePullPolicy: IfNotPresent name: prometheus-node-exporter ports: - containerPort: 9100 hostPort: 9100 protocol: TCP name: metrics volumeMounts: - mountPath: /host/proc name: proc - mountPath: /host/sys name: sys - mountPath: /host name: rootfs args: - --path.procfs=/host/proc - --path.sysfs=/host/sys - --path.rootfs=/host volumes: - name: proc hostPath: path: /proc - name: sys hostPath: path: /sys - name: rootfs hostPath: path: / hostNetwork: true hostPID: true --- apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" labels: k8s-app: node-exporter name: node-exporter namespace: monitor spec: type: NodePort ports: - name: http port: 9100 nodePort: 39100 protocol: TCP selector: k8s-app: node-exporter 2.prometheus采集node 指标数据:配置prometheus通过node exporter采集 监控指标数据 [root@localhost7I prometheus]# cat prometheus.yml global: scrape_interval: 15s #默认情况下抓取目标的频率 evaluation_interval: 15s #评估规则的频率 # 报警配置 alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 #报警服务器地址。 #报警条件,设置告警规则,基于设定什么指标进行报警(类似触发器trigger) rule_files: # - "first_rules.yml" # - "second_rules.yml" 被收集指标的服务器列表。 scrape_configs: - job_name: \'prometheus\' static_configs: - targets: [\'localhost:9090\'] - job_name: \'promethues-master\' #通过node exporter采集master static_configs: - targets: [\'192.168.80.120:9100\',\'192.168.80.130:9100\'] - job_name: \'promethues-node\' #通过node exporter采集node static_configs: - targets: [\'192.168.80.150:9100\',\'192.168.80.160:9100\'] 3.访问prometheus web界面中status-targets 4.访问prometheus web界面查看中Graph选择相应指标查看

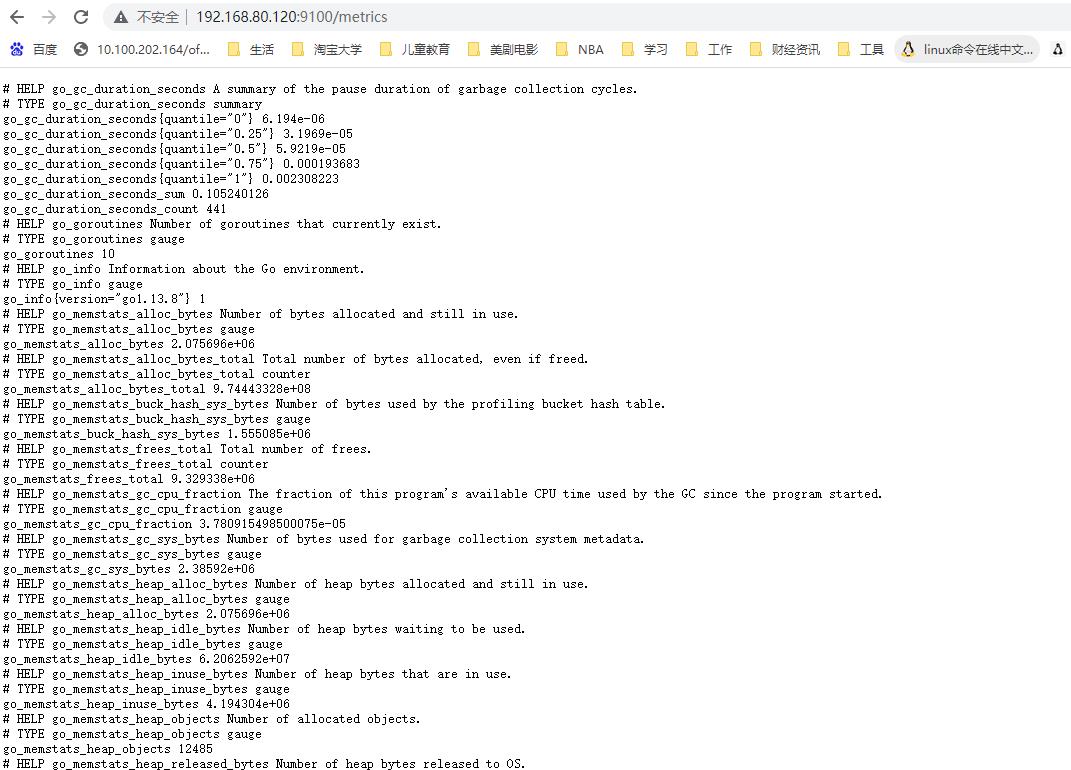
5.访问node exporter web界面中http://IP:9100/metrics
四、安装grafana:调用prometheus的数据,进行更专业的可视化 1.rpm方式安装grafana [root@localhost7J ~]# yum install grafana-6.7.2-1.x86_64.rpm 1.2 k8s方式: apiVersion: apps/v1 kind: Deployment metadata: name: grafana-enterprise namespace: monitor spec: replicas: 1 selector: matchLabels: app: grafana-enterprise template: metadata: labels: app: grafana-enterprise spec: containers: - image: grafana/grafana imagePullPolicy: Always #command: # - "tail" # - "-f" # - "/dev/null" securityContext: allowPrivilegeEscalation: false runAsUser: 0 name: grafana ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: "/var/lib/grafana" name: data resources: requests: cpu: 100m memory: 100Mi limits: cpu: 500m memory: 2500Mi volumes: - name: data emptyDir: --- apiVersion: v1 kind: Service metadata: name: grafana namespace: monitor spec: type: NodePort ports: - port: 80 targetPort: 3000 nodePort: 31000 selector: app: grafana-enterprise 2.配置文件 vim /etc/grafana/grafana.ini [server] # Protocol (http, https, socket) protocol = http # The ip address to bind to, empty will bind to all interfaces http_addr = 0.0.0.0 # The http port to use http_port = 3000 3.grafana web界面 默认账号和密码都是: admin

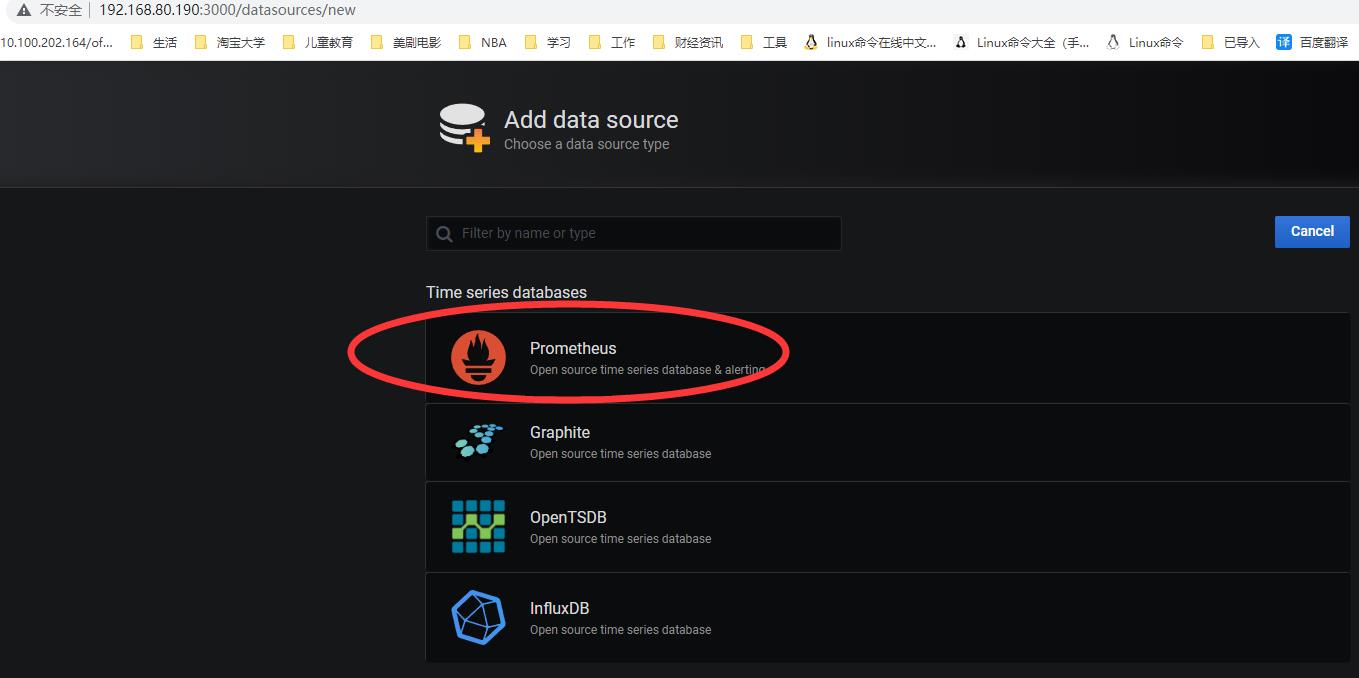
4.有后台的configuration中添加 data_sources,选择prometheus, 填写name和URL即可。


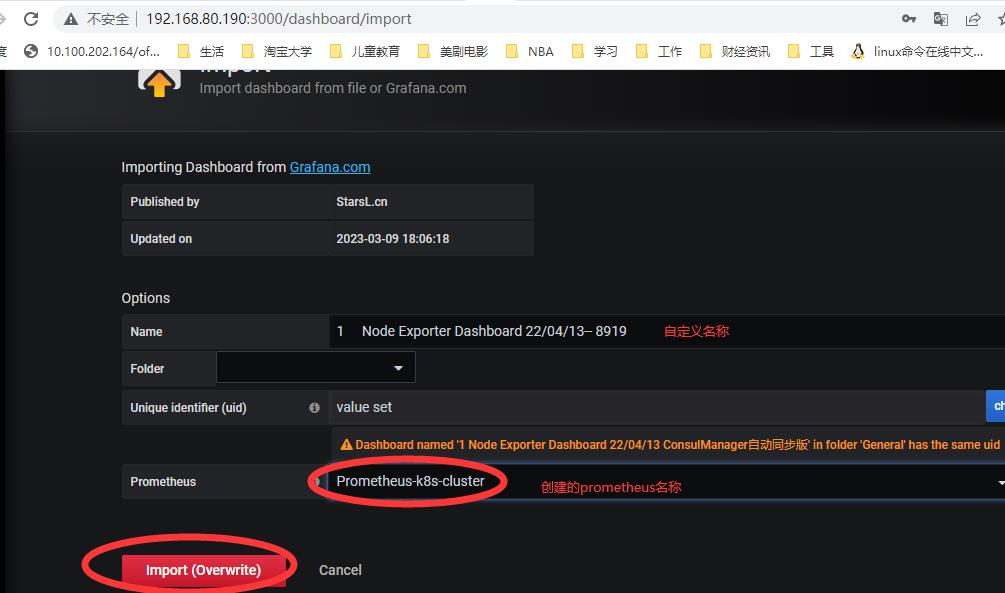
5.grafana添加节点监控模板,在create --import 输入模板号或json文件,关联data_sources名称即可展示. 注意模板是否跟grafana版本和node_expoter的版本兼容。
本例ID:9894


6.插件和模板说明 插件下载地址https://grafana.com/grafana/plugins/ 模板下载地址https://grafana.com/grafana/dashboards/

Grafana CLI插件命令 [root@localhost7J ~]# /usr/share/grafana/bin/grafana-cli plugins -h install 安装<插件id><插件版本(可选)> list-remote 列出远程可用插件 list-versions 列表版本<plugin id> update, upgrade 升级更新<插件id> update-all, upgrade-all 更新所有已安装的插件 ls 列出所有已安装的插件 uninstall, remove 卸载<插件id> 6.1在线安装:饼图插件 # grafana-cli plugins install grafana-piechart-panel 6.2 离线安装: # cd /var/lib/grafana/plugins # unzip grafana-piechart-panel-v1.3.8-0-g4f34110.zip # mv grafana-piechart-panel-4f34110 grafana-piechart-panel # systemctl restart grafana-server
五、Prometheus通过node expoter监控node节点pod资源 cadvisor由谷歌开源,cadvisor不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取, cAdvisor可以对节点机器上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。 k8s 1.12之前cadvisor集成在node节点的上kubelet服务中,从1.12版本开始分离为两个组件,因此需要在node节点单独部署cadvisor。 1.cadvisor镜像准备 docker load -i cadvisor_v0.36.0.tar.gz docker tag 5b1fcda7d310 harbor.zzhz.com/baseimage/cadvisor:v0.36.0 docker push harbor.zzhz.com/baseimage/cadvisor:v0.36.0 2.1.docker方式 docker run \\ --volume=/:/rootfs:ro \\ --volume=/var/run:/var/run:ro \\ --volume=/sys:/sys:ro \\ --volume=/var/lib/docker/:/var/lib/docker:ro \\ --volume=/dev/disk/:/dev/disk:ro \\ --publish=8080:8080 \\ --detach=true \\ --name=cadvisor \\ harbor.zzhz.com/baseimage/cadvisor:v0.36.0 验证cadvisor web界面: 访问node节点的cadvisor监听端口:http://192.168.80.150:8080/

2.2 k8s方式:部署cadvisor的DaemonSet资源,DaemonSet资源可以保证集群内的每一个节点运行同一组相同的pod,即使是新加入的节点也会自动创建对应的pod。 [root@localhost7C prometheus]# cat cadvisor.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: cadvisor # namespace: monitor spec: selector: matchLabels: app: cAdvisor template: metadata: labels: app: cAdvisor spec: tolerations: #污点容忍,忽略master的NoSchedule - effect: NoSchedule key: node-role.kubernetes.io/master hostNetwork: true restartPolicy: Always # 重启策略 containers: - name: cadvisor image: harbor.zzhz.com/baseimage/cadvisor:v0.36.0 imagePullPolicy: IfNotPresent # 镜像策略 ports: - containerPort: 8080 volumeMounts: - name: root mountPath: /rootfs - name: run mountPath: /var/run - name: sys mountPath: /sys - name: docker mountPath: /var/lib/containerd volumes: - name: root hostPath: path: / - name: run hostPath: path: /var/run - name: sys hostPath: path: /sys - name: docker hostPath: path: /var/lib/containerd 3.配置prometheus通过cadvisor 8080端口采集node节点上的监控指标数据 [root@localhost7I prometheus]# cat prometheus.yml global: scrape_interval: 15s #默认情况下抓取目标的频率 evaluation_interval: 15s #评估规则的频率 # 报警配置 alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 #报警服务器地址。 #报警条件,设置告警规则,基于设定什么指标进行报警(类似触发器trigger) rule_files: # - "first_rules.yml" # - "second_rules.yml" 被收集指标的服务器列表。 scrape_configs: - job_name: \'prometheus\' static_configs: - targets: [\'localhost:9090\'] - job_name: \'promethues-master\' #通过node exporter采集master static_configs: - targets: [\'192.168.80.120:9100\',\'192.168.80.130:9100\'] - job_name: \'promethues-node\' #通过node exporter采集node static_configs: - targets: [\'192.168.80.150:9100\',\'192.168.80.160:9100\'] #配置prometheus通过cadvisor 8080端口采集node节点上的监控指标数据 - job_name: \'k8s-node-pod-cadvisor\' static_configs: - targets: [\'192.168.80.150:8080\',\'192.168.80.160:8080\'] 4.有后台的configuration中添加 data_sources,选择prometheus, 填写name和URL即可。 5.grafana添加pod监控模板,在create --import 输入模板号或json文件,关联data_sources名称即可展示.
(ID 395)测试中启动几个POD。

六、prometheus报警设置 ,监控pod资源及实现通知报警 prometheus触发一条告警的过程: prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--->邮件|钉钉|微信等。 分组(group): 将类似性质的警报合并为单个通知。 静默(silences): 是一种简单的特定时间静音的机制,例如:服务器要升级维护可以先设置这个时间段告警静默。 抑制(inhibition): 当警报发出后,停止重复发送由此警报引发的其他警报即合并一个故障引起的多个报警事件,可以消除冗余告警

1.alertmanager服务器 [root@localhost7I local]# tar xvf alertmanager-0.18.0.linux-amd64.tar.gz [root@localhost7I local]# ln -sv /usr/local/src/alertmanager-0.18.0.linux-amd64 /usr/local/alertmanager 2.#配置文件 [root@localhost7I local]# cat alertmanager/alertmanager.yml global: #发送邮件信息 resolve_timeout: 5m smtp_smarthost: \'smtp.qq.com:465\' smtp_from: \'348987564@qq.com\' smtp_auth_username: \'348987564@qq.com\' smtp_auth_password: \'cszrwuylffhybjea\' smtp_hello: \'@qq.com\' smtp_require_tls: false route: #route用来设置报警的分发策略 group_by: [\'alertname\'] #采用哪个标签来作为分组依据 group_wait: 10s #组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出 group_interval: 10s #两组告警的间隔时间 repeat_interval: 2m #重复告警的间隔时间,减少相同邮件的发送频率 receiver: \'web.hook\' #设置接收人(同下) receivers: #设置接收人方式 - name: \'web.hook\' #接收人(同上) #webhook_configs: #API方式 # - url: \'http://127.0.0.1:5001/\' email_configs: #邮件方式 - to: \'348987564@qq.com\' inhibit_rules: #禁止的规则 - source_match: #源匹配级别 severity: \'critical\' target_match: severity: \'warning\' equal: [\'alertname\', \'dev\', \'instance\'] 3.1 #命令启动方式 ./alertmanager --config.file=./alertmanager.yml 3.2 #脚本启动方式 [root@localhost7I local]# cat /etc/systemd/system/alertmanager.service [Unit] Description=Prometheus Server Documentation=https://prometheus.io/docs/introduction/overview/ After=network.target [Service] Restart=on-failure ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml 4 验证alertmanager的9093端口已经监听 [root@localhost7I local]# lsof -i:9093 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME alertmana 54974 root 6u IPv6 5627301 0t0 TCP *:copycat (LISTEN) 5. web验证 http://192.168.80.180:9093/#/alerts


6. 配置prometheus报警规则 [root@localhost7I prometheus]# cat prometheus.yml # my global config global: scrape_interval: 15s evaluation_interval: 15s # # 报警配置 alerting: alertmanagers: - static_configs: - targets: - 192.168.80.180:9093 #报警服务器地址。 #报警条件,设置告警规则,基于设定什么指标进行报警(类似触发器trigger) rule_files: - "/usr/local/prometheus/rule-linux36.yml" scrape_configs: - job_name: \'prometheus\' static_configs: - targets: [\'localhost:9090\'] - job_name: \'promethues-master\' static_configs: - targets: [\'192.168.80.120:9100\',\'192.168.80.130:9100\'] - job_name: \'promethues-node\' static_configs: - targets: [\'192.168.80.150:9100\',\'192.168.80.160:9100\'] - job_name: \'k8s-node-pod-cadvisor\' static_configs: - targets: [\'192.168.80.150:8080\',\'192.168.80.160:8080\'] 7. #pod资源报警条件指标 [root@localhost7I prometheus]# cat rule-linux36.yml groups: - name: linux37_pod.rules rules: - alert: Pod_all_cpu_usage expr: (sum by(name)(rate(container_cpu_usage_seconds_totalimage!=""[5m]))*100) >2 for: 1m labels: severity: critical service: pods annotations: description: 容器 $labels.name CPU 资源利用率大于 2% , (current value is $value ) summary: Dev CPU 负载告警 - alert: Pod_all_memory_usage expr: sort_desc(avg by(name)(irate(container_memory_usage_bytesname!=""[5m]))*100) > 1024*10^3*2 for: 1m labels: severity: critical annotations: description: 容器 $labels.name Memory 资源利用率大于 2G , (current value is $value ) summary: Dev Memory 负载告警 - alert: Pod_all_network_receive_usage expr: sum by (name)(irate(container_network_receive_bytes_totalcontainer_name="POD"[1m])) > 1024*1024*50 for: 10m labels: severity: critical annotations: description: 容器 $labels.name network_receive 资源利用率大于 50M , (current value is $value ) 7.1#验证报警规则设置: [root@localhost7I prometheus]# ./promtool check rules rule-linux36.yml Checking rule-linux36.yml SUCCESS: 3 rules found 7.2验证报警规则匹配 [root@localhost7I alertmanager]# ./amtool alert --alertmanager.url=http://192.168.80.180:9093 Alertname Starts At Summary Pod_all_cpu_usage 2023-04-26 16:51:34 CST Dev CPU 负载告警 Pod_all_cpu_usage 2023-04-26 16:51:34 CST Dev CPU 负载告警 Pod_all_memory_usage 2023-04-26 17:04:34 CST Dev Memory 负载告警 8. prometheus web界面验证报警规则状态

七、prometheus监控haproxy 1.部署haproxy_exporter: # pwd /usr/local/src # tar xvf haproxy_exporter-0.9.0.linux-amd64.tar.gz # ln -sv /usr/local/src/haproxy_exporter-0.9.0.linux-amd64 /usr/local/haproxy_exporter # cd /usr/local/haproxy_exporter 2.1 方法一 使用sock方式 # ./haproxy_exporter --haproxy.scrape-uri=unix:/var/lib/haproxy/haproxy.sock 2.2 方法二 使用状态页方式 # ./haproxy_exporter --haproxy.scrape-uri="http://haadmin:12345@127.0.0.1:9999/haproxy-status;csv" & 启动脚本: # cat /etc/systemd/system/haproxy-exporter.service [Unit] Description=Prometheus haproxy-exporter After=network.target [Service] ExecStart=/usr/local/haproxy_exporter/haproxy_exporter --haproxy.scrape-uri=unix:/var/lib/haproxy/haproxy.sock [Install] WantedBy=multi-user.target 3.验证web界面数据 http://192.168.80.110:9101/metrics

4. prometheus server端添加haproxy数据采集 [root@localhost7I prometheus]# cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - 192.168.80.180:9093 # Load rules once and periodically evaluate them according to the global \'evaluation_interval\'. rule_files: - "/usr/local/prometheus/rule-linux36.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it\'s Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: \'prometheus\' static_configs: - targets: [\'localhost:9090\'] - job_name: \'promethues-master\' static_configs: - targets: [\'192.168.80.120:9100\',\'192.168.80.130:9100\'] - job_name: \'promethues-node\' static_configs: - targets: [\'192.168.80.150:9100\',\'192.168.80.160:9100\'] - job_name: \'k8s-node-pod-cadvisor\' static_configs: - targets: [\'192.168.80.150:8080\',\'192.168.80.160:8080\'] - job_name: \'prometheus-haproxy\' #添加数据采集 static_configs: - targets: ["192.168.80.110:9101"]
5.haproxy+keepalived 设置
[root@localhost7B haproxy_exporter]# cat /etc/keepalived/keepalived.conf
global_defs
notification_email
root@localhost
notification_email_from root@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id localhost7B
vrrp_iptables
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_mcast_group4 224.0.0.18
vrrp_instance zzhz
state MASTER
interface eth0
virtual_router_id 51
priority 95
advert_int 2
authentication
auth_type PASS
auth_pass centos
virtual_ipaddress
192.168.80.222/24 dev eth0 label eth0:1
[root@localhost7B haproxy_exporter]# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/haproxy.sock
defaults
mode http
option httplog
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen stats
mode http
bind 0.0.0.0:9999
stats enable
log global
stats uri /haproxy-status
stats auth haadmin:12345
listen k8s-nginx
bind 192.168.80.222:80
mode tcp
balance roundrobin
server 192.168.80.150 192.168.80.150:30003 check inter 2s fall 3 rise 5
server 192.168.80.160 192.168.80.160:30003 check inter 2s fall 3 rise 5
server 192.168.80.170 192.168.80.170:30003 check inter 2s fall 3 rise 5
6.有后台的configuration中添加 data_sources,选择prometheus, 填写name和URL即可。
7.grafana添加pod监控模板,在create --import 输入模板号或json文件,关联data_sources名称即可展示. ID 367 2428

五分钟搭建基于 Prometheus + Grafana 实时监控系统
文章目录

Prometheus + Grafana 实时监控系统
云原生技术的飞速发展,使基础组件的易用性得到大幅度提升。利用基于 Docker 的 Prometheus、Grafana,五分钟就可以完搞定!
Prometheus + Grafana 实时监控系统
在新一代基于云原生的微服务架构中,不管是业务还是基础设施,服务的可观测性至关重要!
今天聊一下如何搭建基于 Prometheus & Grafana 的单节点监控系统。
依赖镜像包
docker pull prom/node-exporter # 监控指标的采集
docker pull prom/prometheus # 数据采集、聚合、存储
docker pull grafana/grafana # 数据可视化展示组件
启动 node-exporter
sudo docker run -d -p 9100:9100 --net=host prom/node-exporter
执行容器启动指令,启动 node-exporter。
check 端口
netstat -tln | grep 9100
检查 node-exporter 服务端口是否正常启用。
node_exporter 采集服务
node_exporter 通过 Http 接口为 Promeehtus 提供节点性能监控指标,可以做为验证node_exporter是否正常工作的方式之一。
地址默认为:http://IP:9100/metrics,
启动 prom/prometheus
sudo docker run --net=host --name myprometheus -p 9090:9090 -d prom/prometheus
执行容器启动指令,启动 prom/prometheus 。
端口 check
netstat -tln | grep 9090
检查 prom/prometheus 服务端口是否正常启用。
Prometheus 原生可视化服务
Prometheus 自身提供了数据的可视化效果,相对 Grafana 能力稍微逊色。但也可做为验证 Prometheus 是否正常工作的方式之一。
数据源地址为:http://IP:9090/graph
其中可观测到相关配置及数据 Rule 等数据信息…
启动 grafana/grafana
sudo docker run --net=host --name mygrafana -p 3000:3000 -d grafana/grafana
执行容器启动指令,启动 grafana/grafana 。
端口 check
netstat -tln | grep 3000
检查 grafana/grafana 服务端口是否正常启用。
Grafana 可视化服务
Grafana 作为强大的数据可视化工具,具备独立的视图服务,可以做为验证node_exporter是否正常工作的方式之一
地址默认为:http://IP:3000/,默认账号为:admin 密码:admin

配置 prometheus 参数
在本机启动服务需在 /etc/prometheus/prometheus.yml 中配置服务的ip/port、刮擦间隔等信息。
- job_name:test
static_configs:
- targets: ['10.182.29.28:9999']
labels:
instance: localhost-test
由于 docker 容器化之后,此配置文件在 docker 内,如果想更方便的修改调整,可以把此目录挂载出来,挂载载宿主机目录。
挂载prometheus.yml配置
有两种方法,一种是修改 prom/prometheus 配置;一种是命令行启动参数化;
这里介绍简单有效的命令行:
- 首先停掉现服务
- myprometheus: sudo docker stop myprometheus
- 重新启动:
- sudo docker run -d --net=host --name myprometheus -p 9090:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
这样就把配置文件挂载至宿主机 /opt/prometheus/prometheus.yml 目录中了,两者内容始终一致。
Q&A
1、sudo XXX
安装\\执行指令基于 Linux root 权限,故使用sudo ;也可以直接 sudo root 进入 root 角色进行操作。
附录
产品服务最终走多远取决于你对市场的破坏力,走多快取决于你的增长策略创造力。
以上是关于Prometheus+grafana的主要内容,如果未能解决你的问题,请参考以下文章