python,初步
Posted FocusTa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python,初步相关的知识,希望对你有一定的参考价值。
- 变量,包,模块,类的命名规范
#3:项目名包名模块名变量名函数名都是小写字母,不同的字母之间用下划线隔开 # class_basic 1 (推荐) classbasic1 (不推荐) #4: 类名首字母大写驼峰命名StudentInfo HttpRequest
- 注释:
注释: 【#】 表示单行注释 快捷键 ctr1 + / 【\'\'\' \'\'\'】 成对的三个单引号括起来的内容就是多行注释
- 多行链接符:

如果是字符串:也可以这样
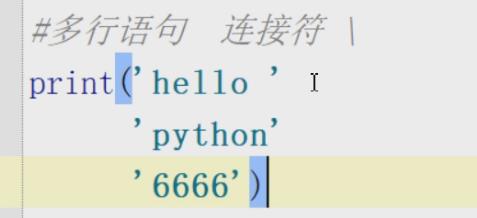
- 单引号,双引号,三引号,都是字符串:

【\\n】:换行的意思 【\\\\n】:就是:\\n本身 - 字符串中的:r R --- 把特殊字符变成普通字符
print(R"这是第一-行\\n这是第二行") print(r"这是第一-行\\n这是第二行")
- 标准输入
#Python文件里面的输入和输出 print(\' hello\' )#输出内容到控制台 a=input("请输入你心目中最好的课程机构”)#从控制台获取个数据I print (a) 备注:标准输入对象是个:字符串
- 字符串:
字符串 w e l c m 正序 0 1 2 3 4 反序 -5 -4 -3 -2 -1
+ 拼接 * 重复次数 str() 转成字符串 in str1 在 str2 内部? 返回: true \\ false
切片: # 字符串的切片:字符串名[m:n:k] # m索引开始的地方n索引结束的地方k步长根据k来计算索引 然后根据索引去取值 # res=a[0:5:1]#k=1 01234取左不取右n-1就结束了取值 # res=a[0:5:2]#k=2 02 4 # res=a[0:5]#如果不输入k那么k就取默认值k=1 0123 4 # res=a[:]#从头取到尾 res=a[0:]#默认取完所有的值
格式化输出【%方式】: 方式一:print (name+”,今年",age,\'岁\' ) 备注:age 的左右有空格 方式二: print(" %s今年%s岁,数学考了%s(或者%.2f) "% (name, age, score) ) #按顺序取值、 #%d必须放一个整数;%f可以放一个整数也可以放一个浮点数;%s可以放任意值
格式化输出【format{}方式】 print(" {0}今年数学考了{1}".format (name, score)) #按顺序取值 #{}里面不指定数值就会按顺序取值 #{}里面指定数值就会根据你设置的去取值 #format.里面的数据也是有索引的从0开始标记数据 更多知识,参照:https://www.cnblogs.com/lovejh/p/9201219.html
- 字符串,函数
#1: 字符串的大小写切换 upper() lower() res =str_ 1.upper () res =str 2.lower () print(\'转换后的结果:{}’\'.format (res))#2: 字符串的查找 find()函数 # res=str_ 1. find(\' 666\') # print(\'查找的结果: {}\'. format (res)) #单个字符 如果能够找到就返回单个字符在字符串里面的索引值 #子字符串 如果能够找到就返回子字符串的第一 个元素在原来字符串里面的索引值 #没找到返回-1#3:字符串的替换replace ()函数内建, 可以指定替换次数 # res=str_ 1. replace(\'o\',’你好’,1) #你要替换的目标字符 你要换上去的新值 # print(\'替换后的结果: {}\'.format (res))#4: 字符串的切割split() # res=str 1. split(\'o\')#返回列表类型的数据但是元素类型还是字符串 # print(\'切割后的结果: {}\'. format (res))#5:字符串头尾的处理strip() #只处理头和尾 res=str_ 1. strip(\'@\' ) print(\'处理后的结果:{}’. format (res)) - 元组
****数据类型是元组 #1.元组的标志() 关键字tuple #2.元组只有一个数据的时候,请加逗号在数据后面不然就不是 元组类型的数据 #3.元组里面的数据可以是任何类型?数字字符串元组列表字典 #4.元组取值是根据索引取值也分为正序和反序(操作同字符串)元组名[索引值] #5. 元组切片: 也是同字符串一 样的操作tuple_ 1[1::2] #6.元组的值一旦确定就无法在更改!
#7.判断元素in not in - 列表
#2:a=[]空列表 #3:里面数据元素可以是任何类型 #4: 列表的取值:也是根据索引来取值列表名[索引值] 正序反序 #5: 列表的切片:操作同字符串列表名[m:n:k] #6:.判断元素in not in成员运算符
****新增操作: #1)列表名. append() 加元素到列表的最后面 每次只能添加一 个元素 # a. append(\'你好’) # a. append(\'中国’) # print(a) #2)列表名. insert() 加元素到列表的指定位置 # a. insert(0, \'中国’) # print (a)
**** 修改列表的元素值 重新赋值 = 赋值运算符 # a[-1]=\'热爱学习的我’ # print (a) **** 删除元素 #1)列表名. pop()删除列表的最后面一 个元素
#2)列表名. pop(index)删除列表指定尾椎的元素
a. pop (2)**** 其他操作 c=[7, 12, 5, 60,3, 22, 56] #c. sort()排序 # C. reverse() 倒置 # C. clear () 清空
- 字典:
**** 字典 #1:标志{}关键字dict #2:a={}空字典 #3:字典的数据存储格式是key:value键值对 #4:字典里面value可以是任何类型的数据
#5:取值方式:根据key取值字典 名[key]
a={’name’:\'中国人’,age\' :18, money\' :99.99,score’:[100, 100, 80]}
#1)新增一个元素字典名[new _key]=value new__key不存在当前字典里面a[\'sex\']=\' girl\'
#2)修改一个元素的值字典名[oId key]=value o1d key存在当前字典里面a[\' money\']=1000
print (a)
#3)删除操作
#a. clear() # 清空
#a. pop( score) # 删除
#del a[\' money\']# del 字典名[key] #删除3
# a. popitem()#随机删除- -组数据*** 取值的方法
items() :以列表返回可遍历的(键,值)元组数组 keys() :以列表返回一个字典所有的键 values() :以列表返回一个字典所有的值
*** set
setdeault (key, value) :如果key存在则返回value值,否则加入key-value A.update(B字典):把A字典与B字典合并,如果key重复,则选择B中的内容。
以上是关于python,初步的主要内容,如果未能解决你的问题,请参考以下文章