Python编程学习之利用selenium分辨出可访问的网页并获取网页内容
Posted liuzzzzzz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python编程学习之利用selenium分辨出可访问的网页并获取网页内容相关的知识,希望对你有一定的参考价值。
一、前言
笔者在前面的文章中收集到一些域名,在这些域名收集完后,并不是每一个域名都有作用,我们要过滤掉访问不了的网站,所以今天学习利用Python中的selenium模块启动Chromium来请求网站,下面记录一下自己的学习过程。
二、学习过程
1.开发工具:
Python版本:3.7.1
相关模块:
selenium模块 pymysql模块
2.原理简介
从数据库读取出需要访问的域名------利用selenium进行访问域名并获取网站标题、内容长度、截图------存入数据库
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
# 获取存活的域名
def run(cursor):
# 获取域名
domains = get_domains(cursor)
# Chrome的参数选项
chrome_options = Options()
# 无头操作
chrome_options.add_argument(‘--headless‘)
# 利用这个路径的Chromium来进行操作
chrome_options.binary_location = r‘%s‘%"/Applications/Chromium.app/Contents/MacOS/Chromium"
# 创建Chrome实例
driver = webdriver.Chrome(executable_path=(r‘/Users/hello/Desktop/chromedriver/chromedriver‘), options=chrome_options)
# 设置20秒的超时时间
driver.set_page_load_timeout(20)
success_list = []
for i in domains:
try:
# 请求网站
driver.get(‘https://‘+i[0])
#获取网站的信息
http_length = len(driver.page_source)
http_status = ‘响应成功‘
img_path = "/Users/hello/Desktop/py test/%s.png"%i[0]
screenshot = driver.get_screenshot_as_file(img_path)
if driver.title:
title = driver.title
else:
title = ‘‘
success_list.append([i[0], title, http_length, img_path, http_status])
except :
print(‘%s 响应失败‘%i[0])
return success_list
# 去数据库查询域名
def get_domains(cursor):
sql = "SELECT hostname FROM 数据库"
cursor.execute(sql)
domain_lists = cursor.fetchall()
return domain_lists
# 把可访问的域名插入数据库
def insert(cursor, list, db):
for i in list:
select_sql = "SELECT id FROM 数据库 WHERE hostname = ‘%s‘"%i[0]
cursor.execute(select_sql)
result = cursor.fetchone()
update_sql = "UPDATE 数据库 SET page_title = ‘%s‘, http_length = %d, page_jietu_path = ‘%s‘, http_status= ‘%s‘ WHERE id = %s" %(i[1], i[2], i[3], i[4], result[0])
cursor.execute(update_sql)
db.commit()
if __name__ == "__main__":
db = pymysql.connect(‘localhost‘, ‘账户‘, ‘密码‘, ‘test‘)
cursor = db.cursor()
list = run(cursor)
insert(cursor, list, db)
db.close()
三、效果展示
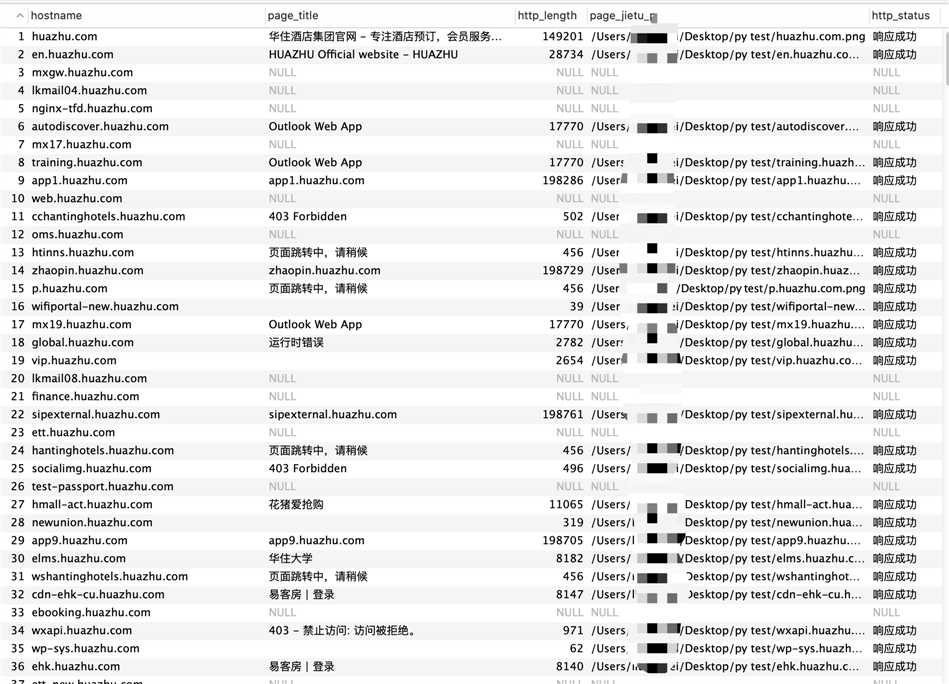
四、总结
程序速度较慢,程序编写能力有待加强。
以上是关于Python编程学习之利用selenium分辨出可访问的网页并获取网页内容的主要内容,如果未能解决你的问题,请参考以下文章