爬虫(Spider),反爬虫(Anti-Spider),反反爬虫(Anti-Anti-Spider) 之间恢宏壮阔的斗争...
小莫想要某站上所有的电影,写了标准的爬虫(基于HttpClient库),不断地遍历某站的电影列表页面,根据 Html 分析电影名字存进自己的数据库。
这个站点的运维小黎发现某个时间段请求量陡增,分析日志发现都是 IP(xxx.xxx.xxx.xxx)这个用户,并且 user-agent 还是 Python-urllib/2.7 ,基于这两点判断非人类后直接在服务器上封杀。
小莫电影只爬了一半,于是也针对性的变换了下策略:1. user-agent 模仿百度("Baiduspider..."),2. IP每爬半个小时就换一个IP代理。
小黎也发现了对应的变化,于是在服务器上设置了一个频率限制,每分钟超过120次请求的再屏蔽IP。 同时考虑到百度家的爬虫有可能会被误伤,想想市场部门每月几十万的投放,于是写了个脚本,通过 hostname 检查下这个 ip 是不是真的百度家的,对这些 ip 设置一个白名单。
小莫发现了新的限制后,想着我也不急着要这些数据,留给服务器慢慢爬吧,于是修改了代码,随机1-3秒爬一次,爬10次休息10秒,每天只在8-12,18-20点爬,隔几天还休息一下。
小黎看着新的日志头都大了,再设定规则不小心会误伤真实用户,于是准备换了一个思路,当3个小时的总请求超过50次的时候弹出一个验证码弹框,没有正确输入的话就把 IP 记录进黑名单。
小莫看到验证码有些傻脸了,不过也不是没有办法,先去学习了图像识别(关键词 PIL,tesseract),再对验证码进行了二值化,分词,模式训练之后,总之最后识别了小黎的验证码(关于验证码,验证码的识别,验证码的反识别也是一个恢弘壮丽的斗争史...),之后爬虫又跑了起来。
小黎是个不折不挠的好同学,看到验证码被攻破后,和开发同学商量了变化下开发模式,数据并不再直接渲染,而是由前端同学异步获取,并且通过 JavaScript 的加密库生成动态的 token,同时加密库再进行混淆。
混淆过的加密库就没有办法了么?当然不是,可以慢慢调试,找到加密原理,不过小莫不准备用这么耗时耗力的方法,他放弃了基于 HttpClient的爬虫,选择了内置浏览器引擎的爬虫(关键词:PhantomJS,Selenium),在浏览器引擎运行页面,直接获取了正确的结果,又一次拿到了对方的数据。
小黎:.....
Selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用.
先下载selenium webdriver ‘geckodriver.exe’,下载好后放到python目录里面
firefox的目录也要添加到环境变量中
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
selenium快速入门
#!/usr/bin/env python # -*- coding:utf-8 -*- from selenium import webdriver # 要想调用键盘按键操作需要引入keys包 from selenium.webdriver.common.keys import Keys #创建浏览器对象 driver = webdriver.Firefox() driver.get("http://www.baidu.com") #打印页面标题“百度一下你就知道” print driver.title #生成当前页面快照 driver.save_screenshot("baidu.png") # id="kw"是百度搜索框,输入字符串“微博”,跳转到搜索中国页面 driver.find_element_by_id("kw").send_keys(u"微博") # id="su"是百度搜索按钮,click() 是模拟点击 driver.find_element_by_id("su").click() # 获取新的页面快照 driver.save_screenshot(u"微博.png") # 打印网页渲染后的源代码 print driver.page_source # 获取当前页面Cookie print driver.get_cookies() # ctrl+a 全选输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,\'a\') # ctrl+x 剪切输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,\'x\') # 输入框重新输入内容 driver.find_element_by_id("kw").send_keys("test") # 模拟Enter回车键 driver.find_element_by_id("su").send_keys(Keys.RETURN) # 清除输入框内容 driver.find_element_by_id("kw").clear() # 生成新的页面快照 driver.save_screenshot("test.png") # 获取当前url print driver.current_url # 关闭当前页面,如果只有一个页面,会关闭浏览器 # driver.close() # 关闭浏览器 driver.quit()
1.页面操作
假如有下面的输入框
<input type="text" name="user-name" id="passwd-id" />
寻找方法
# 获取id标签值
element = driver.find_element_by_id("passwd-id")
# 获取name标签值
element = driver.find_element_by_name("user-name")
# 获取标签名值
element = driver.find_elements_by_tag_name("input")
# 也可以通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id=\'passwd-id\']")
2.定位元素的方法
find_element_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
3.鼠标动作
#!/usr/bin/env python # -*- coding:utf-8 -*- from selenium import webdriver # 要想调用键盘按键操作需要引入keys包 from selenium.webdriver.common.keys import Keys from selenium.webdriver import ActionChains #创建浏览器对象 driver = webdriver.Firefox() driver.get("http://www.baidu.com") #鼠标移动到某处 action1 = driver.find_element_by_id("su") ActionChains(driver).move_to_element(action1).perform() #鼠标移动到某处单击 action2 = driver.find_element_by_id("su") ActionChains(driver).move_to_element(action2).click(action2).perform() #鼠标移动到某处双击 action3 = driver.find_element_by_id("su") ActionChains(driver).move_to_element(action3).double_click(action3).perform() # 鼠标移动到某处右击 action4 = driver.find_element_by_id("su") ActionChains(driver).move_to_element(action4).context_click(action4).perform()
4.Select表单
遇到下来框需要选择操作时,Selenium专门提供了Select类来处理下拉框
# 导入 Select 类 from selenium.webdriver.support.ui import Select # 找到 name 的选项卡 select = Select(driver.find_element_by_name(\'status\')) # select.select_by_index(1) select.select_by_value("0") select.select_by_visible_text(u"xxx")
以上是三种选择下拉框的方式,它可以根据索引来选择,可以根据值来选择,可以根据文字来选择。注意:
- index 索引从 0 开始
- value是option标签的一个属性值,并不是显示在下拉框中的值
- visible_text是在option标签文本的值,是显示在下拉框的值
全部取消方法
select.deselect_all()
5.弹窗处理
当页面出现了弹窗提示
alert = driver.switch_to_alert()
6.页面切换
一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下:
driver.switch_to.window("this is window name")
7.页面前进和后退
操作页面的前进和后退功能:
driver.forward() #前进 driver.back() # 后退
实例 模拟登陆douban网站
#!/usr/bin/env python # -*- coding:utf-8 -*- from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Firefox() driver.get("http://www.douban.com") # 输入账号密码 driver.find_element_by_name("form_email").send_keys("158xxxxxxxx") driver.find_element_by_name("form_password").send_keys("zhxxxxxxxx") # 模拟点击登录 driver.find_element_by_xpath("//input[@class=\'bn-submit\']").click() # 等待3秒 time.sleep(3) # 生成登陆后快照 driver.save_screenshot(u"douban.png") driver.quit()
动态页面模拟点击--->>>爬取斗鱼所有房间名,观众人数
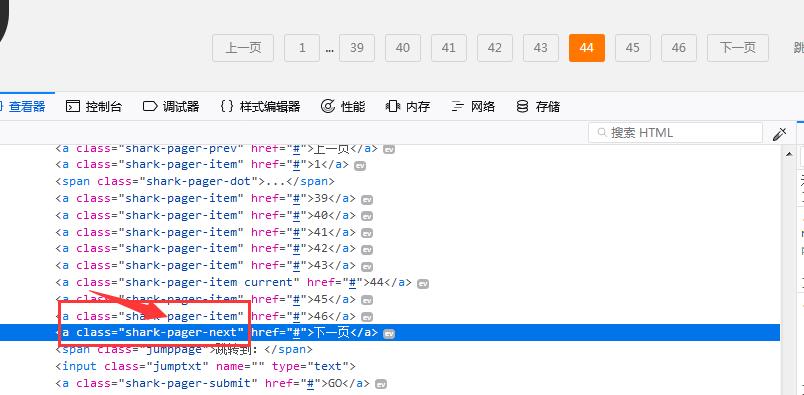
(1)首先分析‘’下一页‘’的class变化,如果不是最后一页的时候,‘下一页’的class如下
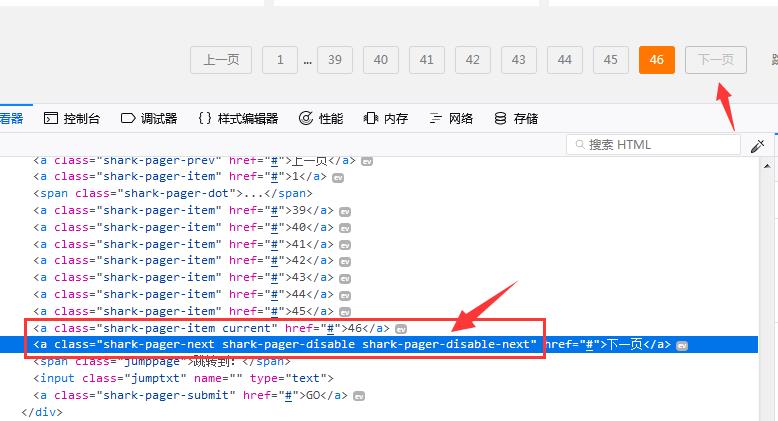
(2)如果到了最后一页,‘下一页’变为隐藏,点击不了,class变为如下
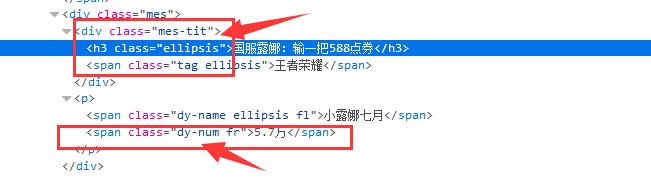
(3)找到个房间的名字和观众人数的class
(4)代码
#!/usr/bin/env python # -*- coding:utf-8 -*- import unittest from selenium import webdriver from bs4 import BeautifulSoup as bs class douyu(unittest.TestCase): # 初始化方法,必须是setUp() def setUp(self): self.driver = webdriver.Firefox() self.num = 0 self.count = 0 # 测试方法必须有test字样开头 def testDouyu(self): self.driver.get("https://www.douyu.com/directory/all") while True: soup = bs(self.driver.page_source, "lxml") # 房间名, 返回列表 names = soup.find_all("h3", {"class" : "ellipsis"}) # 观众人数, 返回列表 numbers = soup.find_all("span", {"class" :"dy-num fr"}) # zip(names, numbers) 将name和number这两个列表合并为一个元组 : [(1, 2), (3, 4)...] for name, number in zip(names, numbers): print u"观众人数: -" + number.get_text().strip() + u"-\\t房间名: " + name.get_text().strip() self.num += 1 #self.count += int(number.get_text().strip()) # 如果在页面源码里找到"下一页"为隐藏的标签,就退出循环 if self.driver.page_source.find("shark-pager-disable-next") != -1: break # 一直点击下一页 self.driver.find_element_by_class_name("shark-pager-next").click() # 测试结束执行的方法 def tearDown(self): # 退出Firefox()浏览器 print "当前网站直播人数" + str(self.num) print "当前网站观众人数" + str(self.count) self.driver.quit() if __name__ == "__main__": # 启动测试模块 unittest.main()
爬取的结果: