Python生成随机数的一个标准库-random
Posted Python学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python生成随机数的一个标准库-random相关的知识,希望对你有一定的参考价值。
1.介绍
Random库Python中用于生成随机数的一个标准库。计算机没有办法产生真正的随机数,但它可以产生伪随机数。
伪随机数是计算机按照一定的运算规则产生的一些数据,只不过这些数据表现为随机数的形式。计算机中采用梅森旋转算法生成为随机序列,序列中的每一个元素就是伪随机数,由于计算机不能产生真正的随机数,所以伪随机数也就被称为随机数。
Random库包含两类函数,常用的有8个:
-
基本随机函数:seed(),random()
-
扩展随机函数:randint(),getrandbits(),uniform(),randrange(),choice(),shuffle()
2.基本随机数函数
Python中的随机数使用随机数种子来产生,随机数种子通过梅森旋转算法产生随机序列,这个随机序列是唯一并且确定的,随机序列中的每一个数就是随机数。换句话说,只要随机数种子相同,那么产生的随机序列无论是每一个数,还是数之间的关系都是相同的。
seed(a=None)
初始化给定的随机数种子,默认为当前时间
random()
生成一个[0.0,1.0)之间的随机小数(大于等于0,小于1)。
根据随机数种子产生随机序列,产生后第一次调用该函数,则返回序列的第0个元素;
第二次调用,则返回序列的第1个元素......以此类推。
实例1:
使用默认的随机数种子产生随机数
>>> import random
>>> random.seed()
>>> random.random()
0.4583742792868192
>>> random.random()
0.9905749191276231
>>> random.seed()
>>> random.random()
0.8846207230562237
>>> random.random()
0.13447072126096293
实例2:
使用固定的随机数种子产生随机数
>>> import random
>>> random.seed(10)
>>> random.random()
0.5714025946899135
>>> random.random()
0.4288890546751146
>>> random.seed(10)
>>> random.random()
0.5714025946899135
>>> random.random()
0.4288890546751146
3.扩展随机数函数
randint(a,b)
生成一个[a,b]之间的随机整数(大于等于a,小于等于b)。例如:
>>> import random
#Python小白学习交流群:725638078
>>> random.randint(1,9)
3
randrange(m,n[,k])
生成一个[m,n)之间以k为步长的随机整数(大于等于m,小于n)。例如:
>>> import random
>>> random.randrange(10,110,10)
20
getrandbits(k)
生成一个长度为k的二进制随机整数。例如:
>>> import random
>>> random.getrandbits(16)
17266
uniform(a,b)
生成一个[a,b]之间的随机小数(大于等于a,小于等于b)。例如:
>>> import random
>>> random.uniform(10,20)
12.484765001518227
choice(seq)
从序列seq中随机选择一个元素。例如:
>>> import random
>>> random.choice((1,2,3,4,5,6,7,8))
4
shuffle(seq)
将变量序列seq中元素随机排序,并返回给序列的变量。例如:
>>> import random
>>> seq=[1,2,3,4,5,6,7]
>>> random.shuffle(seq)
>>> print(seq)
[4, 3, 2, 1, 7, 6, 5]
Python 标准库之 random 生成伪随机数『详细』

Python 标准库之 random 生成伪随机数
文章目录
一、Python random介绍🤪
random 模块实现了各种分布的伪随机数生成器,对于整数,从范围中有统一的选择。 对于序列,存在随机元素的统一选择、用于生成列表的随机排列的函数、以及用于随机抽样而无需替换的函数。
本文章内容较多,如果需要查找某个特定的方法或属性,建议使用浏览器的 查找
ctrl + f功能
二、导入 random 库
在看下列内容前,别忘记导入random 标准库呀
import random
三、随机整数
1)、random.randrange(start, stop[, step]):
.randrange(start, stop[, step]) 相当于 .choice(range(start, stop, step)) ,也就是内置函数 range() 和方法 choice() 的结合,但实际上并没有构建一个 range 对象,位置参数模式匹配 range()
演示代码:
res1 = random.randrange(1, 11) # 1 - 10范围内的随机整数
res2 = random.randrange(1, 11, 2) # 1 - 10范围内每两个的随机整数
res3 = random.choice(range(1, 11, 2)) # 1 - 10范围内每两个的随机整数
print(res1, res2, res3)
2)、random.randint(a, b):「常用」
在 a <= N <= b 范围内返回整数N,此方法又相当于 .randrange(a, b+1) ,简单点理解范围即是 range(a, b+1) 然后再从里面随机抽出一个整数
与.randrange(start, stop[, step]) 的主要差别是有没有 步长 参数
演示代码:
res1 = random.randint(1, 10) # 1 - 10范围内的随机整数
res2 = random.randrange(1, 11) # 1 - 10范围内的随机整数
print(res1, res2)
四、序列用随机函数
1)、random.choice(seq)「常用」
从非空序列 seq 返回 一个 随机元素
演示代码:
res1 = random.choice(range(1, 11)) # 1 - 10范围内的随机整数
res2 = random.choice(["张三", "李四", "王五", "罗翔", "Alex", "Jone"])
print(res1, res2)
如果 seq 为空,则引发 IndexError
2)、random.choices(population, weights=None, cum_weights=None, k=1)
用于有重复的随机抽样,因此不能用作于类似抽奖的用途,返回包含来自 population 序列中元素组成的新列表,新列表的长度以 K 决定,如果需要无重复的随机抽样,参考 .sample() 方法
参数如下:
-
population: population(总体),从population中选择抽取,返回大小为 k 的元素列表
-
weights:如果给出了 weight 序列,则根据相对权重进行选择,如:
[10, 5, 30, 5],在进行选择之前相对权重会转化为累计权重 -
cum_weights:如果给出了 cum_weights 序列,则根据绝对权重进行选择,相对权重
[10, 5, 30, 5]相当于累积权重[10, 15, 45, 50],直接提供累计权重可以减少 内部代码的工作量 -
k: 随机选取的元素 长度、数量
如果既未指定 weight 也未指定 cum_weights ,则以相等的概率进行选择。 如果提供了权重序列,则它必须与 population 序列的长度相同。
演示代码:
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone"]
# 随机选取列表中三元素
res1 = random.choices(arr, k=3)
# 随机选取列表中三元素, Jone 和 罗翔 被选取的概率最大
res2 = random.choices(arr, weights=[5, 10, 30, 25, 15, 30], k=3)
# 随机选取列表中三元素,累计权重概率与上面相对权重相等,Jone 和 罗翔 被选取的概率最大
res3 = random.choices(arr, cum_weights=[5, 15, 45, 70, 85, 115], k=3)
print(res1, res2, res3)
如果 population 为空,则引发 IndexError
3)、random.shuffle(x[, random])「常用」
shuffle 有着 洗牌 的意思,该方法主要作用是将一个序列中的元素打乱重新排列
源码:
def shuffle(self, x, random=None):
"""Shuffle list x in place, and return None.
Optional argument random is a 0-argument function returning a
random float in [0.0, 1.0); if it is the default None, the
standard random.random will be used.
"""
if random is None:
randbelow = self._randbelow
for i in reversed(range(1, len(x))):
# pick an element in x[:i+1] with which to exchange x[i]
j = randbelow(i+1)
x[i], x[j] = x[j], x[i]
else:
_int = int
for i in reversed(range(1, len(x))):
# pick an element in x[:i+1] with which to exchange x[i]
j = _int(random() * (i+1))
x[i], x[j] = x[j], x[i]
参数如下:
- x: 将序列 x 随机打乱位置
- random:可选参数 random 是一个函数,在 [0.0, 1.0) 中返回随机浮点数,如果不指定将默认使用
.random()方法
演示代码:
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone"]
print(arr) # 打印原数组
random.shuffle(arr)
print(arr) # 打印随机后数组
4)、random.sample(population, k) 「常用」
用于无重复的随机抽样,因此能用作于类似抽奖的用途,返回包含来自 population 序列中元素组成的新列表,新列表的长度以 K 决定,如果需要有重复的随机抽样,参考 .choices() 方法
参数如下:
- population: population(总体),从population中选择抽取,返回大小为 k 的元素列表
- k: 返回从总体序列或集合中选择的唯一元素的数量、长度
演示代码:
简易抽奖示例
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone"]
res = random.sample(arr, 3)
level = {1: "一等奖", 2: "二等级", 3: "三等奖"}
for i, k in enumerate(res, 1):
print(f"{level[i]}: {k}", end=" ")
如果样本大小大于总体大小,则引发 ValueError
五、实值分布
以下函数生成特定的实值分布。如常用数学实践中所使用的那样, 函数参数以分布方程中的相应变量命名;大多数这些方程都可以在任何统计学教材中找到
1)、random.random()
返回 [0.0, 1.0) 范围内的下一个随机浮点数,精确到小数点后16位
演示代码:
for i in range(10):
print(round(random.random(), 5)) # 四舍五入精确到后五位
2)、random.uniform(a, b)
返回一个随机浮点数 N ,当 a <= b 时 a <= N <= b ,当 b < a 时 b <= N <= a,精确到小数点后16位
简单来说就是返回 a 和 b 之间,包括a 和 b 的一个浮点数,最小范围是 a 和 b 中最小的,最大范围是 a 和 b 中最大的
源码:
源码其实很简单,算法就是公式 a + (b-a) * self.random()
def uniform(self, a, b):
"Get a random number in the range [a, b) or [a, b] depending on rounding."
return a + (b-a) * self.random()
演示代码:
res1 = random.uniform(10, 1) # 返回 1 <= N <= 10 之间的浮点数
res2 = random.uniform(1, 10) # 返回 1 <= N <= 10 之间的浮点数
res3 = 1 + (10-1) * random.random() # 返回 1 <= N <= 10 之间的浮点数
print(res1, res2, res3, sep=r" // ")
3)、random.triangular(low, high, mode)
返回一个随机浮点数 N ,使得 low <= N <= high 并在这些边界之间使用指定的 mode
源码:
def triangular(self, low=0.0, high=1.0, mode=None):
"""Triangular distribution.
Continuous distribution bounded by given lower and upper limits,
and having a given mode value in-between.
http://en.wikipedia.org/wiki/Triangular_distribution
"""
u = self.random()
try:
c = 0.5 if mode is None else (mode - low) / (high - low)
except ZeroDivisionError:
return low
if u > c:
u = 1.0 - u
c = 1.0 - c
low, high = high, low
return low + (high - low) * _sqrt(u * c)
参数如下:
- low: 返回随机浮点数 N 的最小值,默认值为 0
- high: 返回随机浮点数 N 的最大值,默认值为 1
- mode: 通过源码可以得知对 mode 的处理
0.5 if mode is None else (mode - low) / (high - low),默认值为 0.5 为边界之间的中点,给出对称分布
演示代码:
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone"]
low, high, mode = 0, 5, 5
c = (mode - low) / (high - low)
res1 = random.triangular(low, high)
res2 = random.triangular(low, high, mode=mode)
print(c, res1, res2, sep=r" // ")
4)、random.betavariate(alpha, beta) 「了解」
Beta 分布,又称贝塔分布,参数的条件是 alpha > 0 和 beta > 0, 返回值的范围介于 0 和 1 之间

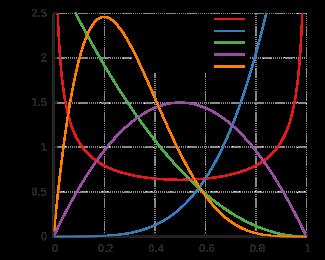
演示代码:
res1 = random.betavariate(2, 2)
res2 = random.betavariate(0.5, 0.5)
res3 = random.betavariate(5, 1)
print(res1, res2, res3, sep=r" // ")
5)、random.expovariate(lambd) 「了解」
指数分布,该参数本应命名为 lambda ,但这是 Python 中的保留字
如果 lambd 为正,则返回值的范围为 0 到正无穷大;如果 lambd 为负,则返回值从负无穷大到 0
演示代码:
res1 = random.expovariate(1)
res2 = random.expovariate(-1)
print(res1, res2, sep=r" // ")
6)、random.gammavariate(alpha, beta) 「了解」
Gamma 分布,参数的条件是 alpha > 0 和 beta > 0
概率分布公式是:👇🏻

演示代码:
res1 = random.gammavariate(5, 1)
res2 = random.gammavariate(1, 6)
res3 = random.gammavariate(6, 6)
print(res1, res2, res3, sep=r" // ")
7)、random.gauss(mu, sigma) 「了解」
高斯分布, mu 是平均值,sigma 是标准差,这比下面要讲的 normalvariate() 函数略快
正态分布(台湾作常态分布,英语:normal distribution)又名高斯分布(英语:Gaussian distribution)、正规分布,是一个非常常见的连续概率分布,正态分布在统计学上十分重要,经常用在自然和社会科学来代表一个不明的随机变量
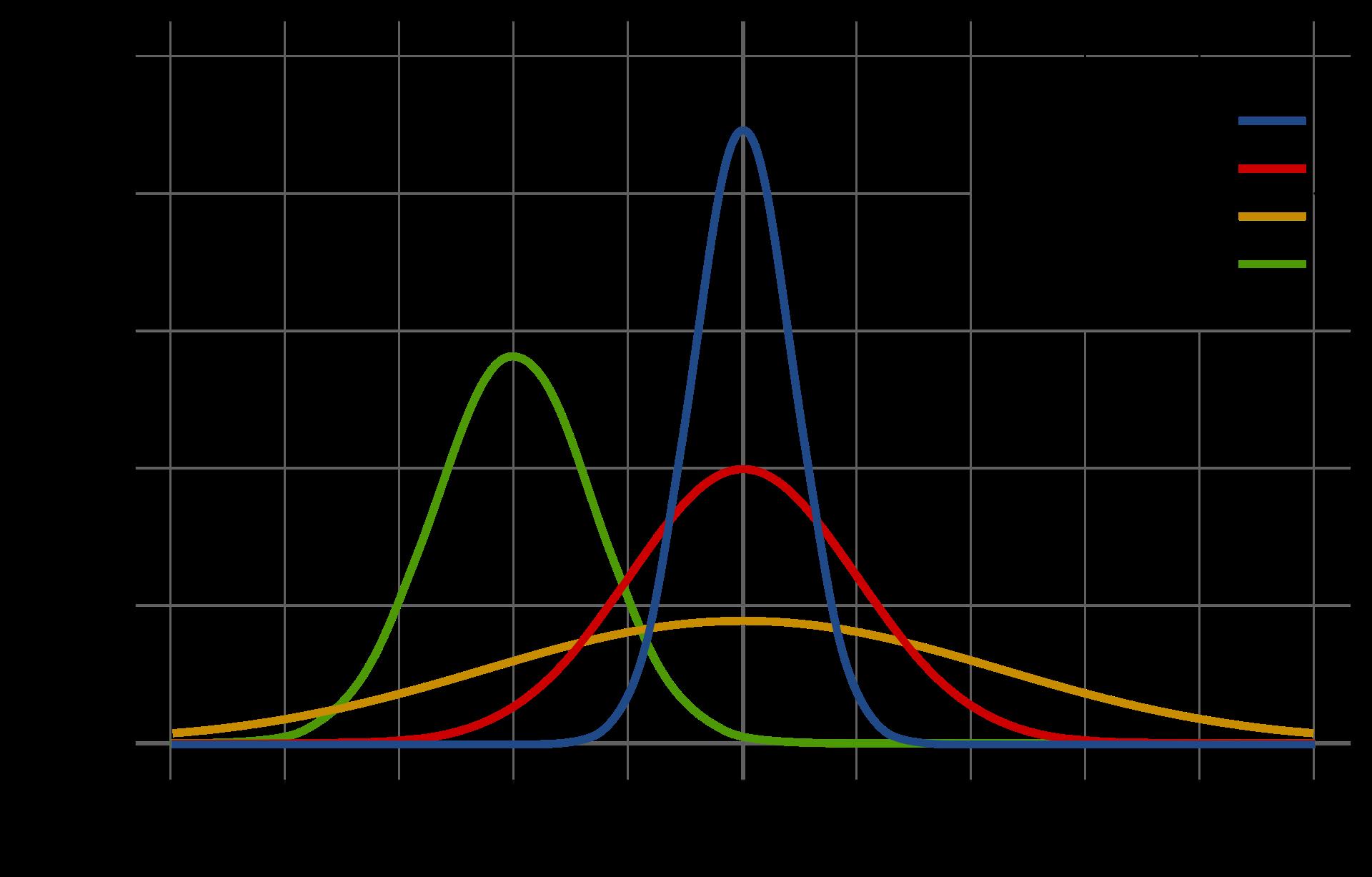
红线代表标准正态分配
演示代码:
res1 = random.gauss(0, 0.2)
res2 = random.gauss(0, 1)
res3 = random.gauss(0, 5)
res4 = random.gauss(-2, 0.5)
print(res1, res2, res3, res4, sep=r" \\\\ ")
8)、random.lognormvariate(mu, sigma) 「了解」
任意随机变量的对数服从正态分布,则这个随机变量服从的分布称为对数正态分布,如果你采用这个分布的自然对数,你将得到一个正态分布
平均值为 mu 和标准差为 sigma,mu 可以是任何值,sigma 必须大于零
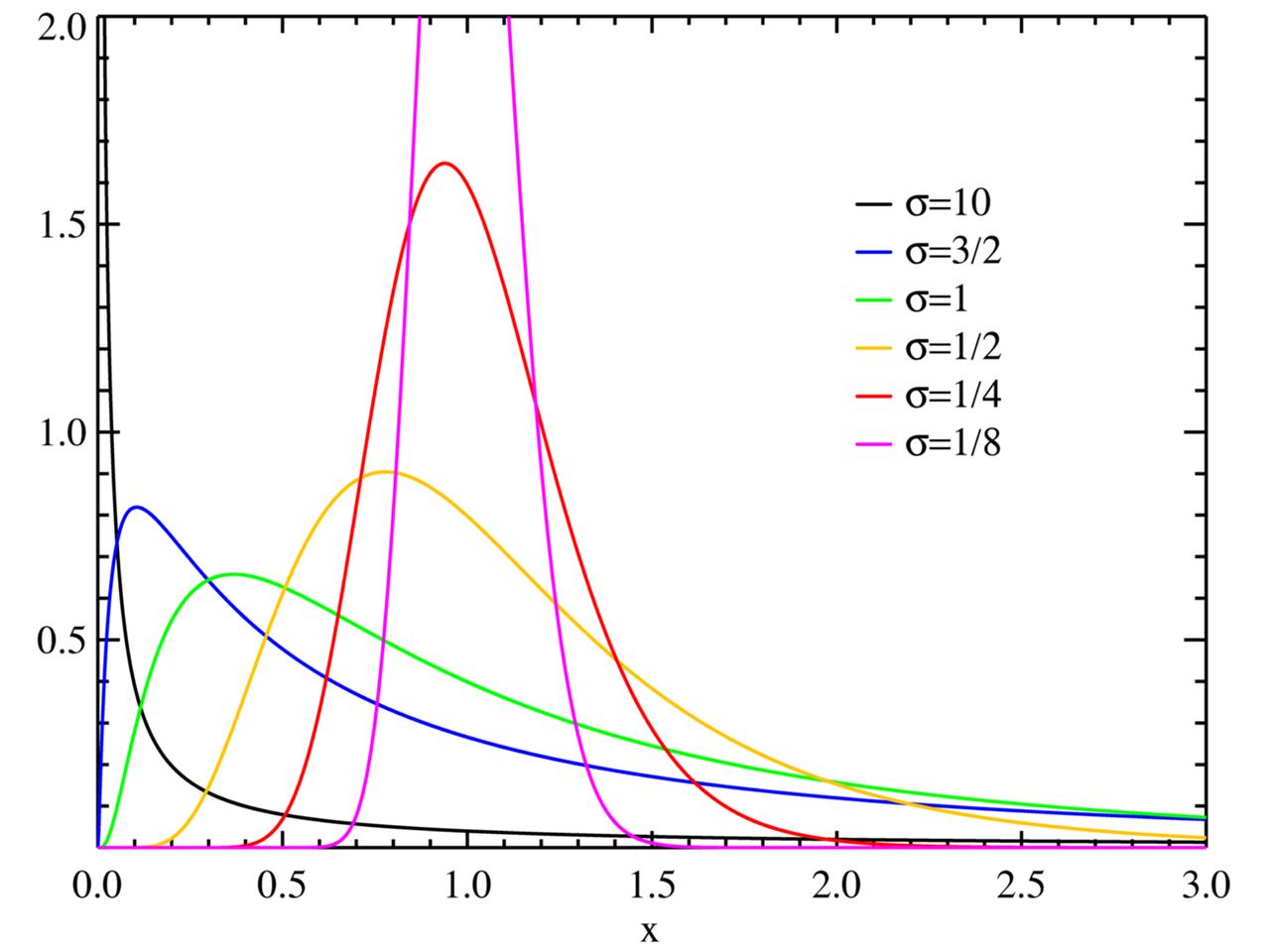
演示代码:
res1 = random.lognormvariate(0, 10)
res2 = random.lognormvariate(0, 1)
res3 = random.lognormvariate(0, 0.5)
res4 = random.lognormvariate(0, 0.25)
print(res1, res2, res3, res4, sep=r" \\\\ ")
9)、random.normalvariate(mu, sigma) 「了解」
正态分布,mu 是平均值,sigma 是标准差,具体参考 7)、random.gauss(mu, sigma)
演示代码:
res1 = random.normalvariate(0, 0.2)
res2 = random.normalvariate(0, 1)
res3 = random.normalvariate(0, 5)
res4 = random.normalvariate(-2, 0.5)
print(res1, res2, res3, res4, sep=r" \\\\ ")
10)、random.vonmisesvariate(mu, kappa) 「了解」
冯·米塞斯(von Mises)分布,mu 是平均角度,以弧度表示,介于0和 2*pi 之间,kappa 是浓度参数,必须大于或等于零
如果 kappa 等于零,则该分布在 0 到 2*pi 的范围内减小到均匀的随机角度
演示代码:
res1 = random.vonmisesvariate(6, 0)
res2 = random.vonmisesvariate(6, 1)
res3 = random.vonmisesvariate(6, 6)
res4 = random.vonmisesvariate(90, 0)
print(res1, res2, res3, res4, sep=r" \\\\ ")
11)、random.paretovariate(alpha) 「了解」
帕累托分布(Pareto distribution)是以意大利经济学家维尔弗雷多·帕累托命名的,alpha 是形状参数


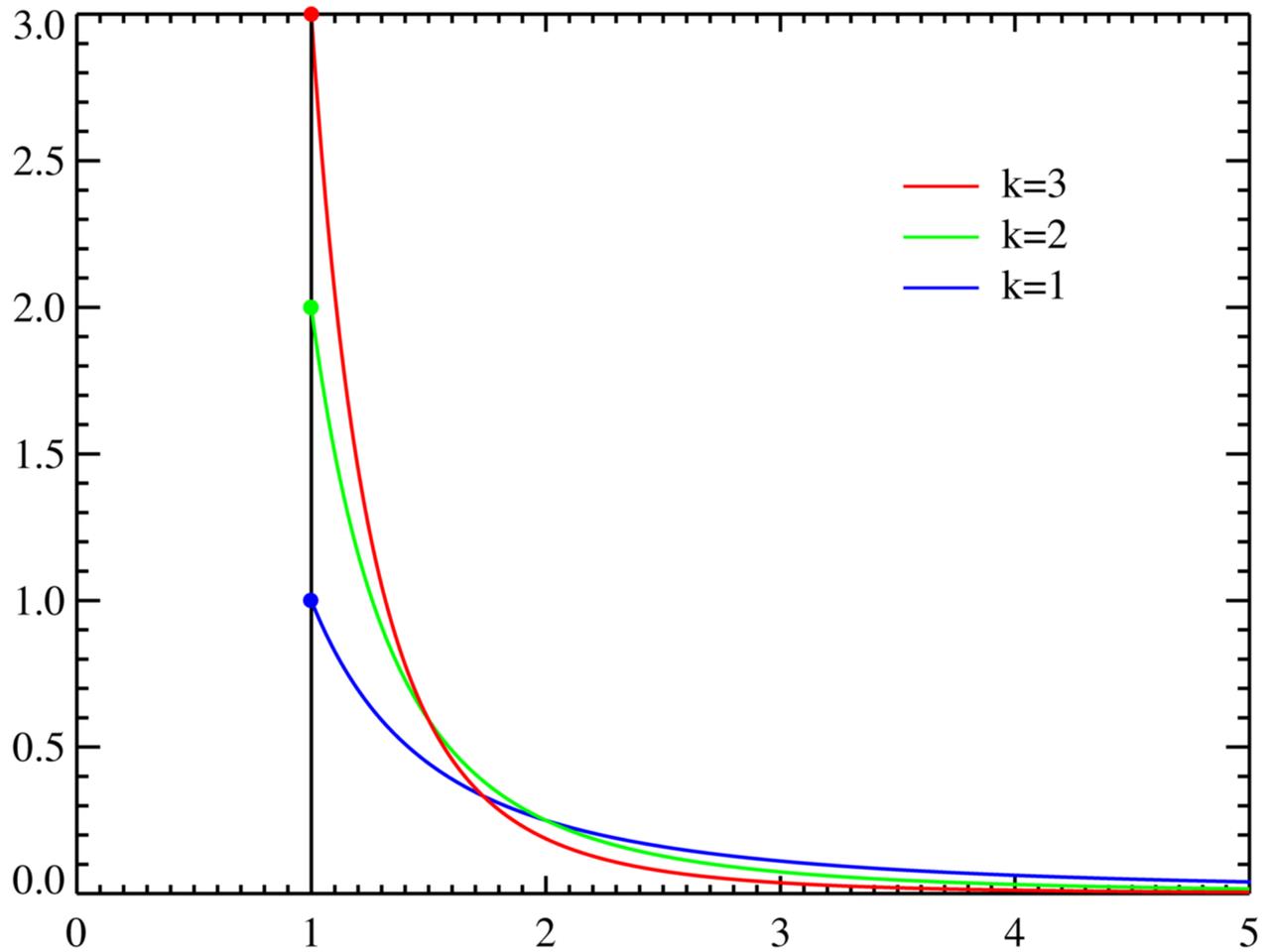
演示代码:
res1 = random.paretovariate(1)
res2 = random.paretovariate(2)
res3 = random.paretovariate(3)
print(res1, res2, res3, sep=r" \\\\ ")
12)、random.weibullvariate(alpha, beta) 「了解」
威布尔分布(Weibull distribution)是可靠性分析和寿命检验的理论基础,alpha 是比例参数,beta 是形状参数

演示代码:
res1 = random.weibullvariate(1, 0.5)
res2 = random.weibullvariate(1, 1)
res3 = random.weibullvariate(1, 1.5)
res4 = random.weibullvariate(1, 5)
print(res1, res2, res3, res4, sep=r" \\\\ ")
六、random 可以做什么?🤔
random 的中文释义是 随机的 意思,那顾名思义干的就是一些随机的活
1)、抽个奖压压惊
抽奖类问题是 随机 最常见的实际应用之一,在上面的方法演示中也提到过了抽奖
a. 先来看看常见思维的写法,循环需要的奖项,在每次循环中将其进行抽取各奖项的获奖者
def get_winners(items: list, level: dict):
"""
抽取获奖者传统思维写法
:param items: 参与人员列表
:param level: 获奖级别信息
:return: 获奖结果
"""
res = {}
for i in level.keys():
item = random.sample(arr, level[i]) # 随机选取指定数量的元素
for d in item: # 遍历选取结果并删除
items.remove(d)
res[i] = item # 添加到结果字典中
return res
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone", "Mark", "李华", "全蛋", "铁花"]
win_level = {"一等奖": 1, "二等奖": 3, "三等奖": 5}
print(get_winners(arr, win_level))
b. 在上面介绍过random.sample(population, k)方法,它是无重复随机抽样,运用这个无重复一次性把所有获奖抽出,再以前后顺序确定奖项即可
def get_winners(items: list, level: dict):
"""
抽取获奖者以索引取法
:param items: 参与人员列表
:param level: 获奖级别信息
:return: 获奖结果
"""
target = random.sample(items, sum(level.values()))
res, prev = {}, 0
for i in level.keys():
res[i] = target[prev: level[i] + prev]
prev += level[i]
return res
arr = ["张三", "李四", "王五", "罗翔", "Alex", "Jone", "Mark", "李华", "全蛋", "铁花"]
win_level = {"一等奖": 1, "二等奖": 3, "三等奖": 5}
print(get_winners(arr, win_level))
2)、猜号数
学习 Python 的同学很多都有接触过这个题目,猜号数问题算是最基础的 Python题目之一,这里咱就复习一下
a. 生成一个 1~100之间的随机数,判断用户输入的数值是否与生成的随机数想等,如果大于这个值或小于这个值,应当提醒用户
其中 c_print() 函数作用用于颜色打印,详情可以参考我关于 颜色打印 的文章
def fuess_the_number():
"""
猜数字小游戏, 无限制次数
"""
target = random.randint(1, 100) # 生成需要猜的目标值
while True:
enter = input("请输入需要您所猜的值:")
if not enter.isdigit(): # 判断是否为数字
c_print("请输入整数", color=31)
elif not (100 >= (enter := int(enter)) >= 1): # 判断范围是否在 1-100 之间
c_print("请输入100-1之间的值", color=31)
else:
if enter > target:
c_print("数值太大啦[再试试]", color=36)
elif enter < target:
c_print(以上是关于Python生成随机数的一个标准库-random的主要内容,如果未能解决你的问题,请参考以下文章