Java基础之String字符串的底层原理,面试常见问题
Posted qian-fen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基础之String字符串的底层原理,面试常见问题相关的知识,希望对你有一定的参考价值。
前言
在之前的两篇文章中,给大家介绍了String字符串及其常用的API方法、常用编码、正则表达式等内容,但这些内容都是停留在”如何用“的阶段,没有涉及到”为什么“的层面。实际上,我们在求职时,面试官很喜欢问我们关于String的一些原理性知识,比如String的不可变性、字符串的内存分配等。为了让大家更好地应对面试,并理解String的底层设计,接下来会给大家聊聊String的一些原理,比如String为什么具有不可变性?
全文大约 【4000】字,不说废话,只讲可以让你学到技术、明白原理的纯干货!本文带有丰富的案例及配图,让你更好地理解和运用文中的技术概念,并可以给你带来具有足够启迪的思考......
一. Spring源码中的final关键词
为了弄清楚String为什么具有不可变性,我们先来看看String的源码,尤其是源码中带有final关键词的地方。
1. final的特点
为了更好地理解String相关的内容,在阅读String源码之前,我们先来复习一下final关键词有哪些特点,因为在String中会涉及到很多final相关的内容。
1.final关键词修饰的类不可以被其他类继承,但是该类本身可以继承其他类,通俗的说就是这个类可以有父类,但是不能有子类;
2.final关键词修饰的方法不可以被覆盖重写,但是可以被继承使用;
3.final关键词修饰的基本数据类型变量称为常量,只能被赋值一次;
4.final关键词修饰的引用数据类型的变量值为地址值,地址值不能改变,但是地址内的数据对象可以被改变;
5.final关键词修饰的成员变量,需要在创建对象前赋值,否则会报错(即需要在定义时直接赋值,如果是在构造方法中赋值,则多个构造方法均需赋值)。
复习了final的特点之后,接下来我们就可以阅读String的源码了。
2. String源码解读
接下来就请大家请跟着我们来看看String源码中关于不可变性的内容吧。
2.1 final修饰的String类
/**
* ......其他略......
*
* Strings are constant; their values cannot be changed after they
* are created. String buffers support mutable strings.
* Because String objects are immutable they can be shared. For example:
*
* ......其他略......
*
*/
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
......
我们先对上面的源码及其注释进行简单的解释:
● final:请参考第1小节对final特点的介绍;
● Serializable:用于序列化;
● Comparable
:默认的比较器; ● CharSequence: 提供对字符序列进行统一、只读的操作。
从这一段源码及注释中,我们可以得出如下结论:
● String类用final关键字修饰,说明String不可被继承;
● String字符串是常量,字符串的值一旦被创建,就不能被改变;
● String字符串缓冲区支持可变字符串;
● 因为String对象是不可变的,所以它们是可以被共享的。
2.2 final修饰的value[]属性
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
/** The value is used for character storage. */
private final char value[];
......
从源码中可以看出,value[]是一个私有的字符数组,String类其实就是通过这个char数组来保存字符串内容的。简单的说,我们定义的字符串会被拆成一个一个的字符,这些字符都被存放在这个value字符数组里面。
这里的value[]数组被final修饰,初始化之后就不能再被更改。但是大家注意,我们这里说的value[]不可变,指的是value的引用地址不可变,但是value数组里面的数据元素其实是可变的! 这是因为value是数组类型,根据我们之前学过的知识,value的引用地址会分配在栈中 ,而其对应的数据是在常量池中保存的。所以我们说String不可变,指的就是value在栈中的引用地址不可变,而不是说常量池中数组本身的数据元素不可变。
另外我们要注意,Java中的字符串常量池,用来存储字符串字面量! 但是由于JDK版本的不同,常量池的位置也不同:
JDK 6 及以下版本的字符串常量池是在方法区(Perm Gen)中,此时常量池中存储的是字符串对象;在 JDK 8.0 中,方法区(永久代被元空间取代了;
JDK 7、8以后的字符串常量池被转移到了堆中,此时常量池存储的就是字符串对象的引用,而不是字符串对象本身。
至此,我们就带各位把String类中的核心源码分析完了,接下来我们再进一步分析String不可变的原因,及其他底层原理设计。
二. String的不可变性
1. 实验案例
了解了上面的这些核心源码之后,接下来再带各位来验证一下,看看String到底能不能变!我先给各位来一段案例代码,代码案例如下图所示。
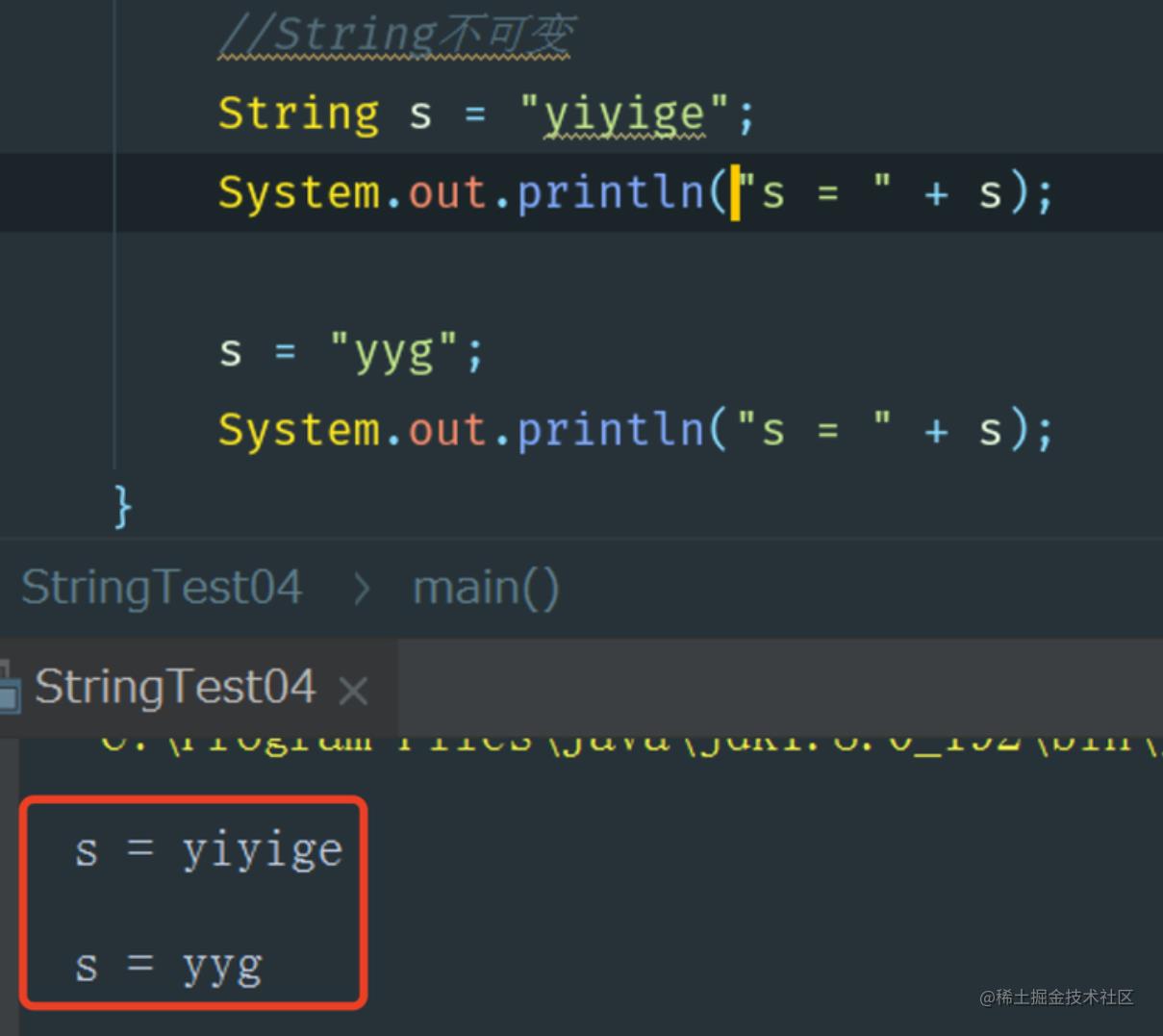
结果s的内容变了,好像是啪啪打脸了???!!!咋回事,你不是说了String不可变吗?怎么这么快就翻车打脸了? 别急,让我们好好来分析一下。
2. 结果剖析
首先我们从结果上来看String s 变量的结果好像改变了,但为什么我们又说String是不可变的呢?
要想明白这个问题,我们得先弄清楚一个点,即引用和值的区别! 在上面的代码中,我们先是创建了一个 "yiyige" 为内容的字符串引用s,s其实先是指向了value对象,而value对象则指向存储了 "y,i,y,i,g,e" 字符的字符数组。
因为value被final修饰,所以value的值不可被更改。因此,上面代码中改变的其实是s的引用指向,而不是改变了String对象的值。换句话说,上面实例中 s的值 只是 value的引用地址,并不是String内容本身!当我们执行 s = "yyg"; 语句时,Java中会创建一个新的字面量对象 "yyg",而原来的 "yiyige" 字面量对象依然存在于内存的intern缓存池中。 在Java中,因为数组也是对象, 所以value中存储的也只是一个引用,它指向一个真正的数组对象。在执行了String s = “yiyige”; 这句代码之后,真正的内存布局应该是下图这样的:

因为value是String封装的字符数组,value中的所有字符都属于String这个对象。由于value是private的,且没有提供setValue等公共方法来修改这个value值,所以在String类的外部是无法修改value值的,也就是说一旦初始化就不能被修改。此外,value变量是final的, 也就是说在String类内部,一旦这个值初始化了,value这个变量所引用的地址就不会改变了,即一直引用同一个对象。正是基于这一层,所以说String对象是不可变的对象。
但其实value所引用对象的内容完全可以发生改变,我们可以利用反射来消除String类对象的不可变特性。
所以String的不可变性,指的是value在栈中的引用地址不可变,而不是说常量池中array本身的数据元素不可变!
而String对象的改变实际上是通过内存地址的 “断开-连接” 变化来完成的,这个过程中原字符串中的内容并没有任何的改变。String s = "yiyige"; 和 s = "yyg"; 实质上是开辟了2个内存空间,s 只是由原来指向 "yiyige" 变为指向 "yyg" 而已,而其原来的字符串内容,是没有改变的,如下图所示。

因此,我们在以后的开发中,如果要经常修改字符串的内容,请尽量少用String,因为字符串的指向“断开-连接”会大大降低性能,建议使用:StringBuilder、StringBuffer。
那么String一定不可变吗?有没有办法让String真的可变呢?我们继续往下学习!
三. String真的不可变吗?
1. 实验案例
我在前面的章节中给大家说,String的不可变,其实指的是String类中value属性在栈中的引用地址不可变,而不是说常量池中array本身的数据元素不可变!也就是说String字符串的内容其实是可变的!那怎么实现呢?利用反射就可以实现,我们通过一个案例来证明一下。
try
String str = "yyg";
System.out.println("str=" + str + ", 唯一性hash值=" + System.identityHashCode(str));
Class stringClass = str.getClass();
//获取String类中的value属性
Field field = stringClass.getDeclaredField("value");
//设置私有成员的可访问性,进行暴力反射
field.setAccessible(true);
//获取value数组中的内容
char[] value = (char[]) field.get(str);
System.out.println("value=" + Arrays.toString(value));
value[1] = \'z\';
System.out.println("str=" + str + ", 唯一性hash值=" + System.identityHashCode(str));
catch (NoSuchFieldException | IllegalAccessException e)
e.printStackTrace();
2. 结果剖析
上面案例的执行结果如下图所示:
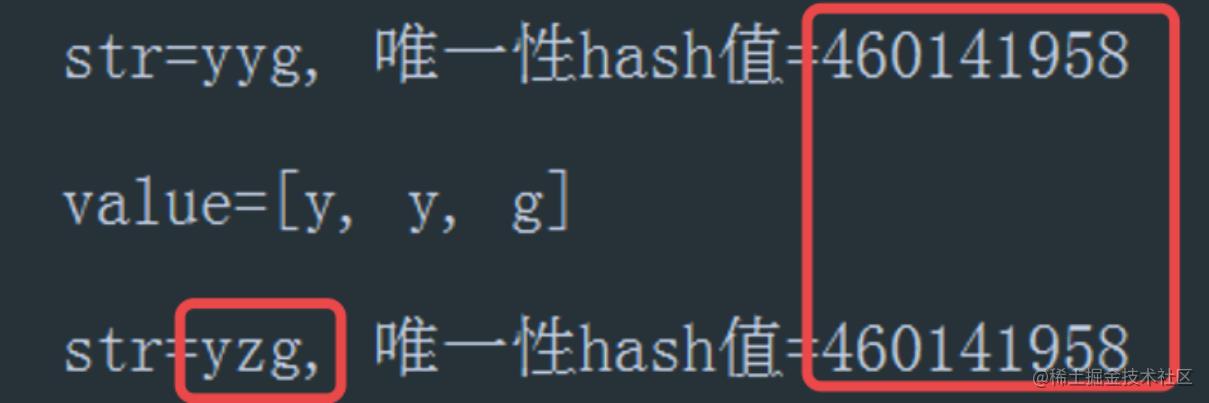
我们可以看到,String字符串的字符数组可以通过反射进行修改,导致字符串的“内容”真的发生了变化! 并且我们又利用底层的java.lang.System#identityHashCode()方法(不管是否重写了hashCode方法)获取了对象的唯一哈希值,该方法获取的hash值与hashCode()方法是一样的。我们可以看到两个字符串的唯一性hash值是一样的,证明字符串引用地址没有发生改变!所以在这里,我们并不是像之前那样创建了一个新的String字符串,而是真的改变了String的内容。这个代码案例进一步说明,String类的不可变指的是中value属性在栈中的引用地址不可变,而不是说常量池中array本身的数据元素不可变!也就是说String字符串的内容其实是可变的!
四. 结语
String作为Java中使用最为广泛的一个类,之所以设计为不可变,主要是出于效率与安全性方面考虑。这种设计有优点,也有缺点。
1. 不可变性的优点
1、只有当字符串是不可变的,字符串池才有可能实现。 字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串引用都可以指向池中的同一个字符串。但如果字符串是可变的,如果一个引用变量改变了字符串的值,那么其它指向这个值的变量内容也会跟着一起改变。
2、如果字符串是可变的,那么可能会引起很严重的安全问题。 譬如,数据库的用户名、密码都是以字符串的形式传入数据库,以获得数据库的连接;或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象值,造成安全漏洞。
3、因为字符串是不可变的, 在物理上是绝对的线程安全,所以同一个字符串实例可以被多个线程共享。 由于不可变对象不可能被修改,因此能够在多线程中被任意自由访问而不导致线程安全问题,不需要多余的同步操作。即在并发场景下,多个线程同时读一个资源,并不会引发竞态条件,只有对资源进行读写才有危险。不可变对象不能被写,所以线程安全。
4、类加载器要用到字符串,不可变性也提供了安全性,以便正确的类可以被加载。 譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
5、因为字符串是不可变的,所以在字符串对象创建的时候hashCode()就被执行并把执行结果缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,所以字符串的处理速度要快过其它的键对象,这就是HashMap中的键往往都使用字符串的原因,当我们需要频繁读取访问任意键值对时,能够节省很多的CPU计算开销。
6、Sting的不可变性会提高执行性能和效率,基于Sting不可变,我们就可以用缓存池将String对象缓存起来,同时把一个String对象的地址赋值给多个String引用,这样可以安全保证多个变量共享同一个对象。因此,构造一万个string s = "xyz",实际上得到都是同一个字符串对象,避免了很多不必要的空间开销。
2. 不可变性的缺点
● 丧失了部分灵活性。我们平时使用的大部分都是可变对象,比如内容变化时,只需要利用setValue()更新一下就可以了,不需要重新创建一个对象,但是String很难做到这一点。当然,我们完全可以使用StringBuilder来弥补这个缺点。
● 脆弱的不可变性,String其实可以利用JNI或反射来改变其不可变性。
面试常考问题:Java泛型的底层原理是什么?
本文来自读者小志的投稿
导语
笔者在最近的日常工作中,因业务需要,研究 Java 字节码层面的知识。具体是,需要根据类字节码,获取特定方法名的方法入参,此方法名在源码中只有一个。但是在实际使用中发现:在类实现泛型接口的情况下,在字节码层面,类却有两个同名方法,导致无法确定哪个方法才是我们需要的方法。经过研究发现,其中一个方法是编译器在编译的过程中,自动生成的桥接方法(bridge method),两个方法可通过特定标识区分。
注:此处的桥接方法,跟设计模式中的桥接模式,不是一个概念。
问题描述
为了能够说明问题,笔者模糊了实际业务场景的具体案例,用一个稍微简单,能够说明问题的示例,来分析编译器自动生成的桥接方法(bridge method)。
我们知道,Java 泛型是JDK 5 中引入的一个新特性,应用广泛。比如,我们有一个操作算子泛型接口 Operator<T>,接口中有一个 process(T t) 方法,其作用是对入参 T 进行逻辑处理。示例代码如下:
/**
* @author renzhiqiang
* @date 2022/2/20 18:30
*/
public interface Operator<T>
/**
* process method
* @param t
*/
void process(T t);
在实际业务场景中,我们会有不同的操作算子,实现Operator<T> 接口,进行业务逻辑处理。那么我们来创建一个具体的算子,并实现Operator<T> 接口,重写 process(T t) 方法。如下:
/**
* 用户信息算子
* @author renzhiqiang
* @date 2022/2/20 18:30
*/
public class UserInfoOperator implements Operator<String>
@Override
public void process(String s)
// do something
其中,泛型接口中的入参类型 T,在实现类中替换成了实际需要的类型 java.lang.String。到这里,我们就准备好了代码样例。
那么,我们的目标是什么呢?就是要获取UserInfoOperator#process(String s) 方法的参数类型java.lang.String。读到这里,读者可能会想:这不很简单么,通过反射,根据Class#getDeclaredMethods(),获取到 UserInfoOperator 的所有方法,再找到方法名是 process 的方法,然后再获取到参数列表,不就可以获取参数类型java.lang.String 了么。
如果正在阅读文章的你也这么想的话,那请继续往下看。
根据 Java 反射方法Class#getDeclaredMethods() 的描述:
Returns an array of Method objectsincluding public, protected, default (package) access, and private methods, butexcludes inherited methods.
翻译过来就是:返回方法对象数组,包括公共方法、受保护方法、默认(包)访问方法和私有方法,但不包括继承方法。
根据我们的示例,如果我们通过反射,利用Class#getDeclaredMethods() 方法,我们预期的返回方法数组中,应该只有一个方法名是process 才对,但是这里却有两个 process 方法。惊不惊奇,意不意外!

图 debug 发现 UserInfoOperator 类的两个 process 方法
产生原因
编译器生成 bridge 方法
我们知道,Java 源码需要经过编译器编译,生成对应的 .class 文件,才能给 JVM 使用。在源码中,我们只定义了一个名为 process 的方法。那么我们考虑,编译器在编译源码的过程中,是否会进行一些特的处理。为了更加直观的查看编译后的字节码文件,在 Idea 安装 jclasslib 插件,通过 jclasslib 查看 UserInfoOperator 和 Operator<T> 的字节码。如下:

图 jclasslib 查看 UserInfoOperator 类的字节码(第一个 process 方法)
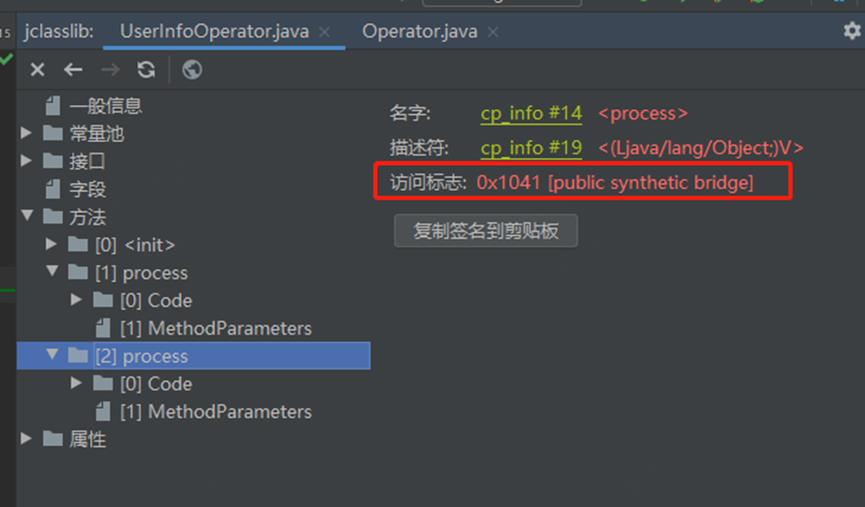
图 jclasslib 查看 UserInfoOperator 类的字节码 (第二个 process 方法)
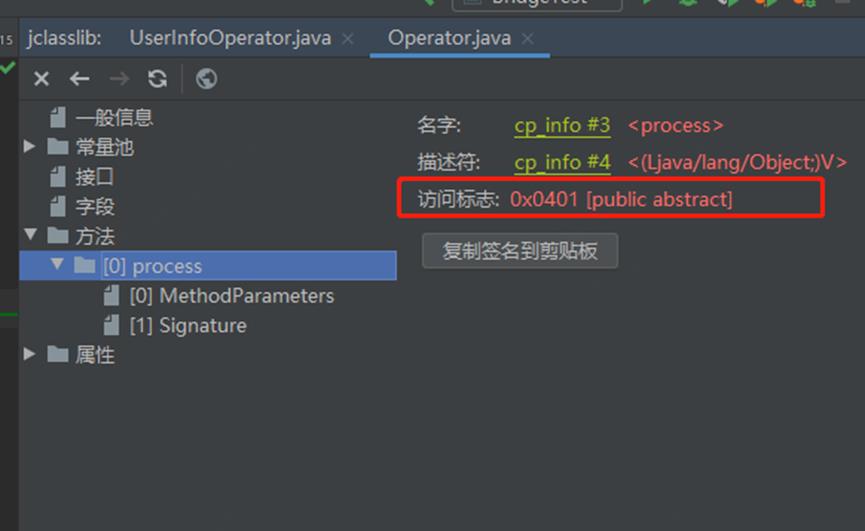
图 jclasslib 查看 Operator<T> 类的字节码
通过 jclasslib 查看 .class 文件发现,在 UserInfoOperator 类中确实存在两个 process 方法:其中一个方法入参是 java.lang.String,另一个方法的入参是 java.lang.Object。而在 Operator 字节码中,只有一个 process 方法,方法的入参是 java.lang.Object。同时我们注意到,在 UserInfoOperator 类的字节码中, [访问标志]项,其中一个方法的访问标志是 [public synthetic bridge]。其中 public 很好理解,但是其中的 [synthetic bridge] 是怎么来的呢?
查阅相关资料后发现,标识符 synthetic ,表示此方法是否是由编译器自动产生的;标识符 bridge,表示此方法是否是由编译器产生的桥接方法。
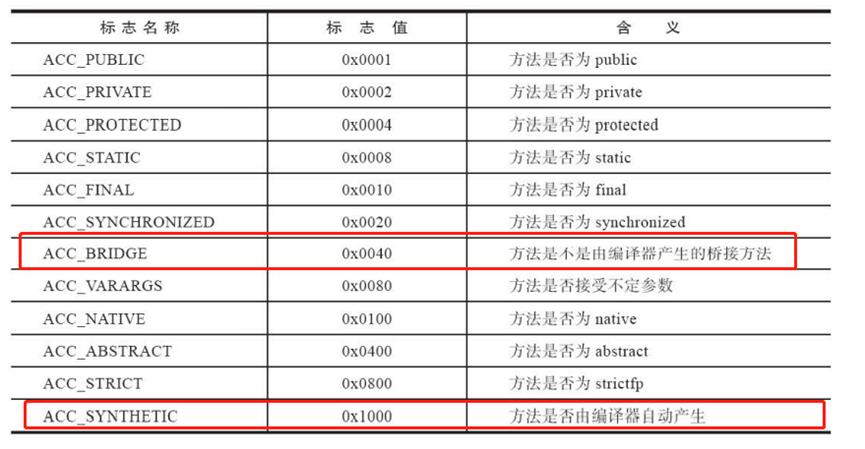
图 方法访问标志(来源:深入理解 Java 虚拟机(第三版))
到此,可以确定的是,其中一个process 方法,是编译器自动产生的桥接方法。那么为什么编译器会产生桥接方法呢?以及在什么情况下,会产生桥接方法?以及如何判断一个方法是不是桥接方法?我们继续往下分析。
为何生成 bridge 方法
正确编译
在源码中,Operator 类的 process 方法的参数定义是 process(T t),参数类型是 T。而在字节码层面我们看到,process 方法在编译之后,编译器将入参类型变成了 java.lang.Object。伪代码示意,大概是这样:
public interface Operator<Object>
/**
* 方法参数变成 Object 类型
* @param object
*/
void process(Object object);
想象一下,如果没有编译器自动生成的桥接方法,那么在编译层面是不能通过的:因为接口 Operator<T> 中的 process 方法,,经过编译之后,参数类型变成了 java.lang.Object 类型,而实现类 UserInfoOperator 中的 process 方法的参数是 java.lang.String 类型,两者的方法参数不一致,导致UserInfoOperator 并没有重写接口中的 process 方法,因此编译无法通过。
这种情况下,编译器自动生成一个桥接方法 void process(Object obj) 方法,则可以编译通过,似乎是理所当然的事情。自动生成的 process方法,方法签名为:void process(Object object)。伪代码示意,大概是这样:
// 自动生成的process 方法
public void process(Object object)
process((String) object);
类型擦除
我们知道,Java 中的泛型在编译期间会将泛型信息擦除。如代码定义 List<String> 和 List<Integer>,编译之后都会变成 List。我们再考虑一种常见的情形:Java 类库中比较器的用法。我们自定义比较器的时候,可以通过实现 Comparator 接口,实现比较逻辑。示例代码如下:
public class MyComparator implements Comparator<Integer>
public int compare(Integer a,Integer b)
// 比较逻辑
这种情况下,编译器同样会产生一个桥接方法。方法签名为 intcompare(Object a, Object b) 。

图 MyComparator 类的两个 compare 方法
伪代码示意,大概是这样:
public class MyComparator implements Comparator<Integer>
public int compare(Integer a,Integer b)
// 比较逻辑
// 桥接方法 (bridge method)
public int compare(Object a,Object b)
return compare((Integer)a,(Integer)b);
因此,当我们使用如下方式进行比较的时候,能够通过编译并得到我们预期的结果:
Object a = 5;
Object b = 6;
Comparator rawComp = new MyComparator();
// 可以通过编译,因为自动生成了桥接方法compare(Object a, Object b)
int comp = rawComp.compare(a, b);
另外,我们知道,泛型编译之后,类型信息会被擦除。如果我们有这样一个比较方法:
// 比较方法
public <T> T max(List<T> list, Comparator<T> comparator)
T biggestSoFar = list.get(0);
for ( T t : list )
if (comparator.compare(t,biggestSoFar) > 0)
biggestSoFar = t;
return biggestSoFar;
编译之后,泛型被擦除掉,伪代码表示,大概是这样:
public Object max(List list, Comparator comparator)
Object biggestSoFar =list.get(0);
for ( Object t : list )
if (comparator.compare(t,biggestSoFar) > 0) //比较逻辑
biggestSoFar = t;
return biggestSoFar;
我们将 MyComparator 其中一个参数传入 max() 方法。如果没有桥接方法的话,那么第四行的比较逻辑,将无法正确编译,因为MyComparator 类中没有两个参数是 Object 类型的比较方法,只有参数类型是 Integer 类型的比较方法。读者可自行测试。
解决方案
通过以上的案例描述,我们知道,在实现泛型接口的场景下,编译器会自动生成桥接方法,保证编译能够通过。那么在这种情况下,我们只要识别哪一个是桥接方法,哪一个不是桥接方法,就可以解决我们一开始的问题。很自然的,既然编译器自动产生了一个桥接方法,那么应该会有某种方式,可以让我们判断一个方法是否是桥接方法。
果然,我们继续研究发现,Method 类中提供了 Method#isBridge() 方法。查看源码中对方法的描述:Method#isBridge():Returns true if this method is a bridge method;returns false otherwise。
到此,我们通过反射,获取到 UserInfoOperator 类中的两个process 方法,再调用 Method#isBridge() 方法,即可锁定需要的方法,因而进一步获取方法参数 java.lang.String。
深入分析
至此可以说,就业务需求来说,我们完美的找到了解决方案。但在此之后,不禁会想:除了上述示例,还有哪些情况下,编译器也会自动生成桥接方法呢?我们继续深入研究。
类继承
通过查阅相关资料,我们考虑如下一种情况:
/**
* 如下会产生桥接方法吗?
* @author renzhiqiang
* @date 2022/2/20 18:33
*/
public class BridgeMethodSample
static class A
public void foo()
public static class C extends A
public static class D extends A
@Override
public void foo()
上述代码示例中,我们定义了三个静态内部类:A C D,其中 C D 分别继承 A。经过编译,通过jclasslib 查看 BridgeMethodSample 字节码,我们也发现:类 C 中编译器为其生成了桥接方法 void foo(),而类 D 中却没有。

图 类C 生成桥接方法

图 类D 没有生成桥接方法
深入分析,并根据上述分析的经验,我们猜测,编译器生成桥接方法,一定是在某种情况下需要一个方法,来满足 Java 编程规范,或者需要保证程序运行的正确性。通过字节码可以看出,类 A 没有 public 修饰,包范围以外的程序是没有访问类 A 的权限的,更不用说类 A 中的方法。
但是类 C 是有public 修饰,C 类中的方法,包括继承来的方法,是可以被包外的程序访问的。因此,编译器需要生成一个桥接方法,以保证能够访问 foo() 方法,满足程序的正确运行。但是,类 D 同样继承 A,却没有生成桥接方法,根本原因是类 D 中重写了父类 A 中的 foo() 方法,即没有必要生成桥接方法。
方法重写
我们再看一种情况,方法重写。
Java 中,方法重写(Override),是子类对父类的允许访问的方法的实现过程进行重新编写的过程。重写需要满足一定的规则:
1. The method must have the same name as in the parentclass.
2. The method must have the same parameter as in theparent class.
3. There must be an IS-A relationship (inheritance).
JDK 5 之后,重写方法的返回类型,可以与父类方法返回类型相同,也可以不相同,但必须是父类方法返回类型的子类。我们考虑如下代码示例:
// 定义一个父类,包含一个 test() 方法
public class Father
public Object test(String s)
return s;
// 定义一个子类,继承父类
public class Child extends Father
@Override
public String test(String s)
return s;
以上,在 Child 子类中,我们重写了 test() 方法,但是返回值的类型,我们将 java.lang.Object 改变为它的子类 java.lang.String。编译之后,我们同样使用 jclasslib 插件,查看两个类的字节码,如下所示:

图 Child 类字节码test() 方法(1)
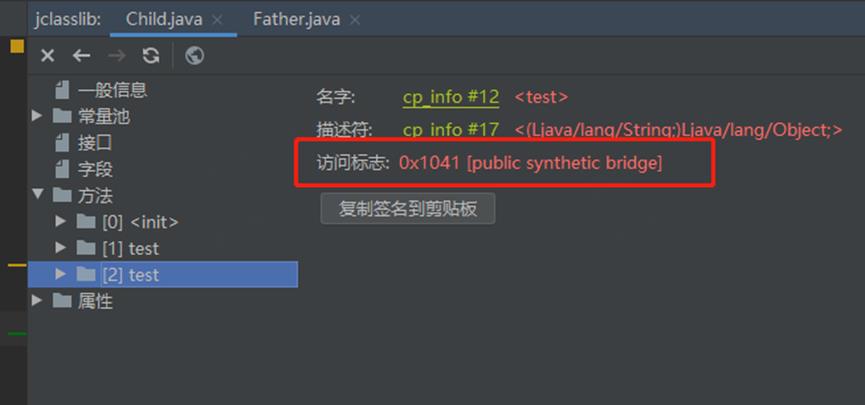
图 Child 类字节码test() 方法(2)

图 Father类字节码test() 方法
根据上图我们发现,Child 类中我们重写了 test() 方法,但是在字节码层面,发现有两个 test() 方法,其中一个方法的访问标志为 [public synthetic bridge], 表示这个方法是编译器为我们生成的。而当我们不改变 Child#test() 方法的返回类型时,编译器并没有为我们生成桥接方法,读者可自行试验。
也就是说,在子类方法重写父类方法,返回类型不一致的情况下,编译器也为我们生成了桥接方法。
以上,笔者罗列了几种编译器为我们自动生成桥接方法的情况。那么是否还有其他场景下,编译器也会生成桥接方法呢?如果您也曾研究过或者使用过 bridge 方法,欢迎交流讨论。
同时,给出一个 bridge 方法的非官方定义,希望能够给读者一些启发:
Bridge Method: These are methods that create an intermediate layerbetween the source and the target functions. It is usually used as part of thetype erasure process. It means that the bridge method is required as a typesafe interface.
限于笔者水平有限,难免有理解不准确、不到位的地方。欢迎交流讨论!
参考
https://stackoverflow.com/questions/5007357/java-generics-bridge-method
https://stackoverflow.com/questions/14144888/find-generic-method-with-actual-types-from-getdeclaredmethods
https://www.geeksforgeeks.org/method-class-isbridge-method-in-java/
以上是关于Java基础之String字符串的底层原理,面试常见问题的主要内容,如果未能解决你的问题,请参考以下文章