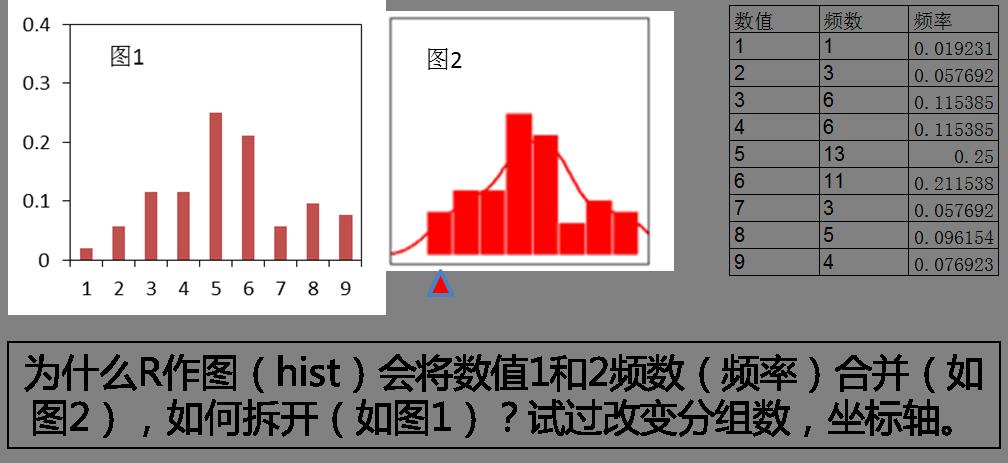
为啥R语言作图(hist)会将数值1和2频数(频率)合并(如图2),如何拆开(如图1)?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥R语言作图(hist)会将数值1和2频数(频率)合并(如图2),如何拆开(如图1)?相关的知识,希望对你有一定的参考价值。
为什么R语言作图(hist)会将数值1和2频数(频率)合并(如图2),如何拆开(如图1)?试过改变分组数,坐标轴。
R语言hist绘图函数
hist 用于绘制直方图,下面介绍每个参数的作用;
1)x: 用于绘制直方图的数据,该参数的值为一个向量
代码示例:
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data)
效果图如下:
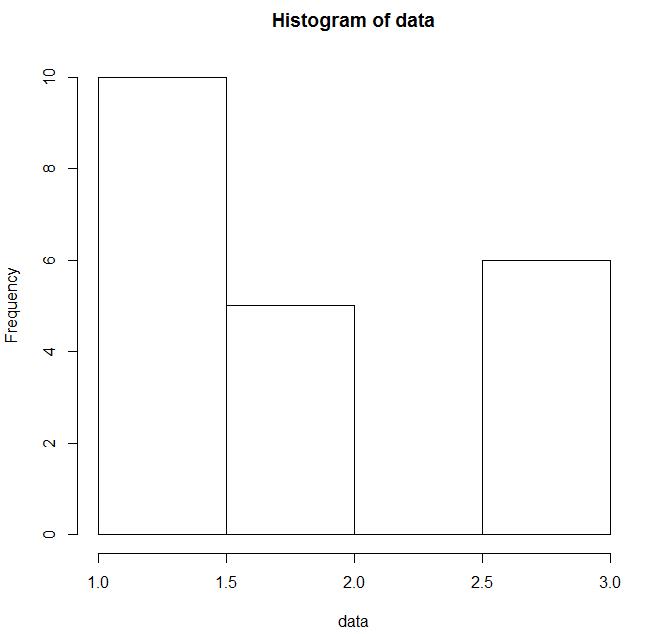
从图中可以看出,横坐标为不同的区间,纵坐标为落入该区间内的频数;
2) break : 该参数的指定格式有很多种
第一种: 指定一个向量,给出不同的断点
代码示例:
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5))
效果图如下:

第二种:指定分隔好的区间的个数,会根据区间个数自动去计算区间的大小
代码示例:
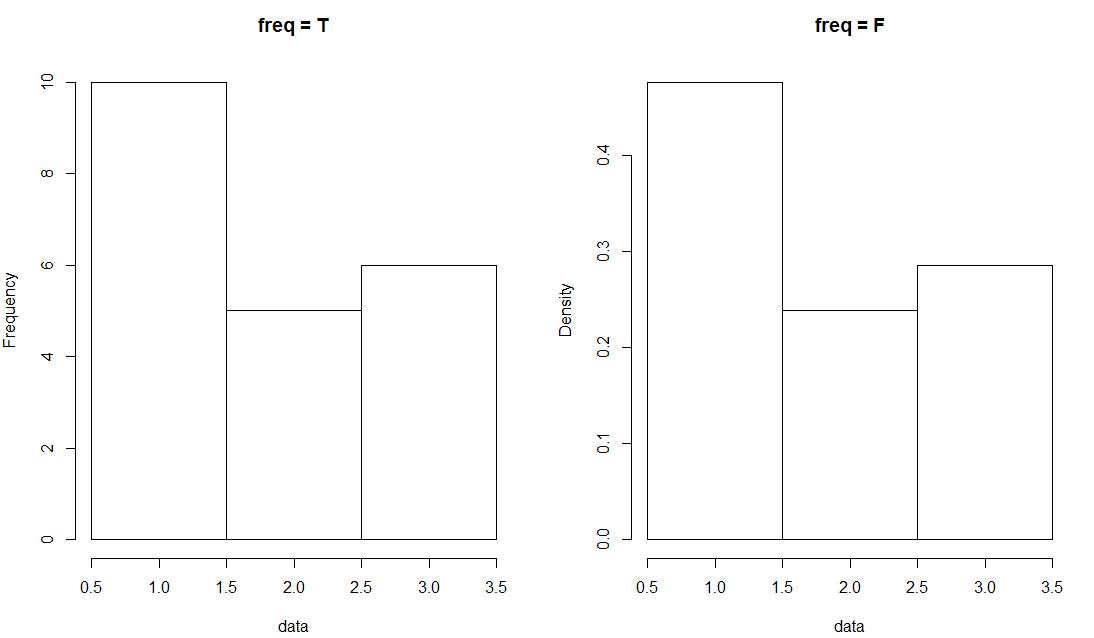
3)freq: 逻辑值,默认值为TRUE , y轴显示的是每个区间内的频数,FALSE, 代表显示的是频率(= 频数/ 总数)
代码示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), freq = T, main = "freq = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), freq = F, main = "freq = F")
效果图如下:
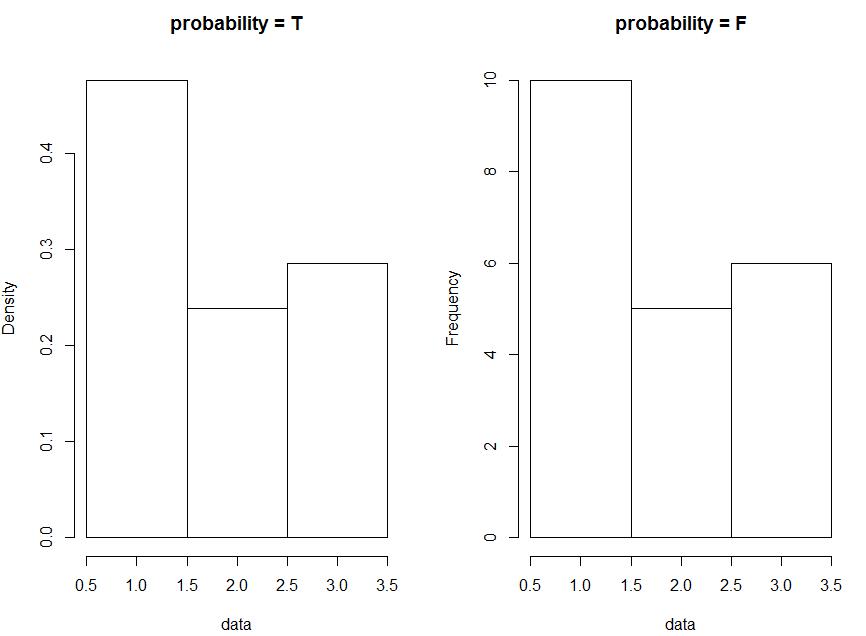
4)probability : 逻辑值,和 freq 参数的作用正好相反,TRUE 代表频率, FALSE 代表频数
代码示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), probability = T, main = "probability = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), probability = F, main = "probability = F")
效果图如下:
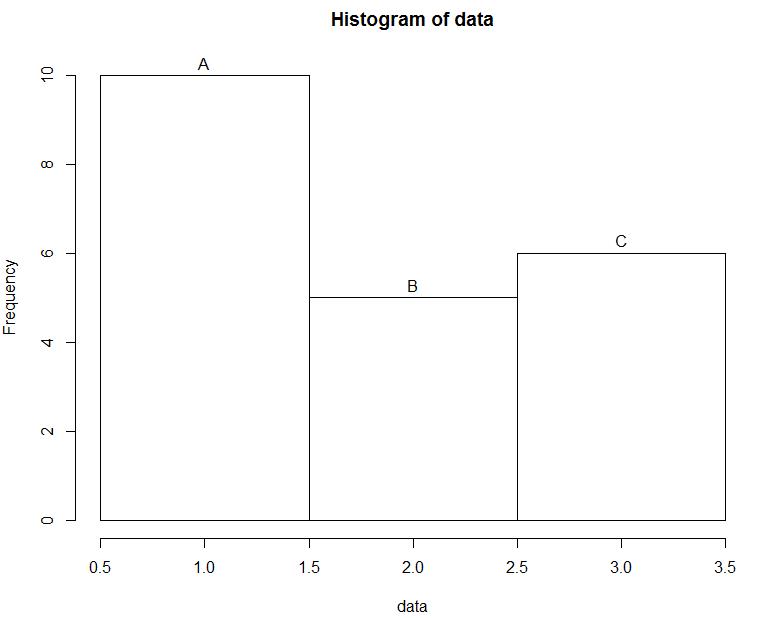
5) labels: 显示在每个柱子上方的标签,
代码示例:
hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), labels = c("A", "B", "C"))
效果图如下:
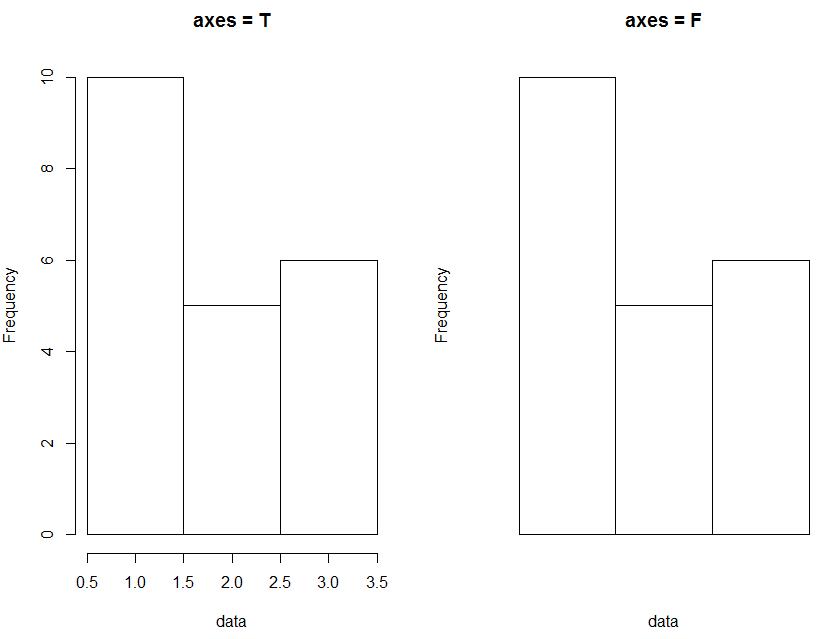
6) axes : 逻辑值,是否显示轴线
代码示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), axes = T, main = "axes = T") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), axes = F, main = "axes = F")
效果图如下:
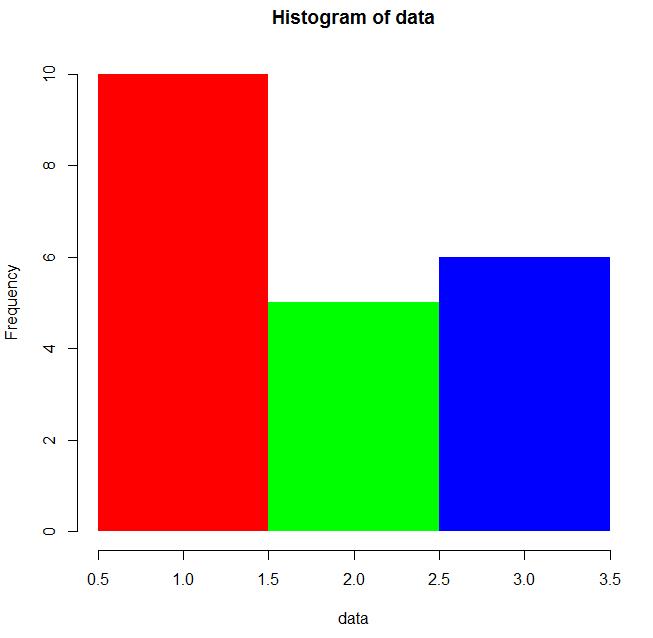
7) col : 柱子的填充色
代码示例:
par(mfrow = c(1, 2)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = "pink") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = rainbow(3))
效果图如下:

8) border : 柱子的边框的颜色,默认为black, 当border = NA 时, 代表没有边框
代码示例:
hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), col = rainbow(3), border = NA)
效果图如下:
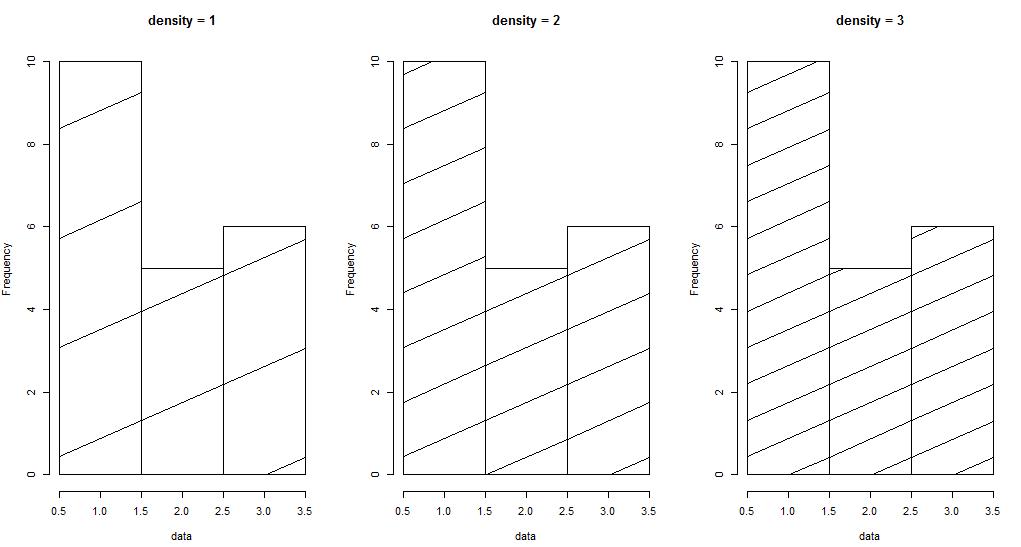
9) densitty 和 angle , 用线条填充柱子
代码示例: density 控制填充的线条的密度
par(mfrow = c(1, 3)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 1, main = "density = 1") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, main = "density = 2") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 3, main = "density = 3")
效果图如下:
代码示例: angle 控制线条的角度,必须和density 参数配合使用,才能发挥作用
par(mfrow = c(1, 3)) data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 45, main = "angle = 45") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 90, main = "angle = 90") hist(data, breaks = c(0.5, 1.5, 2.5, 3.5), density = 2, angle = 180, main = "angle = 180")
效果图如下:

最后介绍一下hist函数的返回值
data <- c(rep(1, 10), rep(2, 5), rep(3, 6)) a <- hist(data, breaks = c(0.5, 1.5, 2.5, 3.5)) a $breaks [1] 0.5 1.5 2.5 3.5 $counts [1] 10 5 6 $density [1] 0.4761905 0.2380952 0.2857143 $mids [1] 1 2 3 $xname [1] "data" $equidist [1] TRUE attr(,"class") [1] "histogram"
从代码中的结果可以看到,返回值是一个 histogram 类型的对象, 其中breaks 是分隔的区间,counts 是每个区间的频数,density是每个区间的频率,mids 是每个柱子的中心点;
利用返回值,我们可以用hist函数统计一串数据在不同区间的频数分布
以上是关于为啥R语言作图(hist)会将数值1和2频数(频率)合并(如图2),如何拆开(如图1)?的主要内容,如果未能解决你的问题,请参考以下文章