深入理解python虚拟机:调试器实现原理与源码分析
Posted Chang-LeHung
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解python虚拟机:调试器实现原理与源码分析相关的知识,希望对你有一定的参考价值。
 在本篇文章当中主要给大家介绍 python 语言当中调试器的实现原理,通过了解一个语言的调试器的实现原理我们可以更加深入的理解整个语言的运行机制,可以帮助我们更好的理解程序的执行。
在本篇文章当中主要给大家介绍 python 语言当中调试器的实现原理,通过了解一个语言的调试器的实现原理我们可以更加深入的理解整个语言的运行机制,可以帮助我们更好的理解程序的执行。
深入理解python虚拟机:调试器实现原理与源码分析
调试器是一个编程语言非常重要的部分,调试器是一种用于诊断和修复代码错误(或称为 bug)的工具,它允许开发者在程序执行时逐步查看和分析代码的状态和行为,它可以帮助开发者诊断和修复代码错误,理解程序的行为,优化性能。无论在哪种编程语言中,调试器都是一个强大的工具,对于提高开发效率和代码质量都起着积极的作用。
在本篇文章当中主要给大家介绍 python 语言当中调试器的实现原理,通过了解一个语言的调试器的实现原理我们可以更加深入的理解整个语言的运行机制,可以帮助我们更好的理解程序的执行。
让程序停下来
如果我们需要对一个程序进行调试最重要的一个点就是如果让程序停下来,只有让程序的执行停下来我们才能够观察程序执行的状态,比如我们需要调试 99 乘法表:
def m99():
for i in range(1, 10):
for j in range(1, i + 1):
print(f"ixj=i*j", end=\'\\t\')
print()
if __name__ == \'__main__\':
m99()
现在执行命令 python -m pdb pdbusage.py 就可以对上面的程序进行调试:
(py3.8) ➜ pdb_test git:(master) ✗ python -m pdb pdbusage.py
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(3)<module>()
-> def m99():
(Pdb) s
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(10)<module>()
-> if __name__ == \'__main__\':
(Pdb) s
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(11)<module>()
-> m99()
(Pdb) s
--Call--
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(3)m99()
-> def m99():
(Pdb) s
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(4)m99()
-> for i in range(1, 10):
(Pdb) s
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(5)m99()
-> for j in range(1, i + 1):
(Pdb) s
> /Users/xxxx/Desktop/workdir/dive-into-cpython/code/pdb_test/pdbusage.py(6)m99()
-> print(f"ixj=i*j", end=\'\\t\')
(Pdb) p i
1
(Pdb)
当然你也可以在 IDE 当中进行调试:

根据我们的调试经历容易知道,要想调试一个程序首先最重要的一点就是程序需要在我们设置断点的位置要能够停下来
cpython 王炸机制 —— tracing
现在的问题是,上面的程序是怎么在程序执行时停下来的呢?
根据前面的学习我们可以了解到,一个 python 程序的执行首先需要经过 python 编译器编译成 python 字节码,然后交给 python 虚拟机进行执行,如果需要程序停下来就一定需要虚拟机给上层的 python 程序提供接口,让程序在执行的时候可以知道现在执行到什么位置了。这个神秘的机制就隐藏在 sys 这个模块当中,事实上这个模块几乎承担了所有我们与 python 解释器交互的接口。实现调试器一个非常重要的函数就是 sys.settrace 函数,这个函数将为线程设置一个追踪函数,当虚拟机有函数调用,执行完一行代码的时候、甚至执行完一条字节码之后就会执行这个函数。
设置系统的跟踪函数,允许在 Python 中实现一个 Python 源代码调试器。该函数是线程特定的;为了支持多线程调试,必须对每个正在调试的线程注册一个跟踪函数,使用 settrace() 或者使用 threading.settrace() 。
跟踪函数应该有三个参数:frame、event 和 arg。frame 是当前的栈帧。event 是一个字符串:\'call\'、\'line\'、\'return\'、\'exception\'、 \'opcode\' 、\'c_call\' 或者 \'c_exception\'。arg 取决于事件类型。
跟踪函数在每次进入新的局部作用域时被调用(事件设置为\'call\');它应该返回一个引用,用于新作用域的本地跟踪函数,或者如果不想在该作用域中进行跟踪,则返回None。
如果在跟踪函数中发生任何错误,它将被取消设置,就像调用settrace(None)一样。
事件的含义如下:
-
call,调用了一个函数(或者进入了其他代码块)。调用全局跟踪函数;arg 为 None;返回值指定了本地跟踪函数。
-
line,将要执行一行新的代码,参数 arg 的值为 None 。
-
return,函数(或其他代码块)即将返回。调用本地跟踪函数;arg 是将要返回的值,如果事件是由引发的异常引起的,则arg为None。跟踪函数的返回值将被忽略。
-
exception,发生了异常。调用本地跟踪函数;arg是一个元组(exception,value,traceback);返回值指定了新的本地跟踪函数。
-
opcode,解释器即将执行新的字节码指令。调用本地跟踪函数;arg 为 None;返回值指定了新的本地跟踪函数。默认情况下,不会发出每个操作码的事件:必须通过在帧上设置 f_trace_opcodes 为 True 来显式请求。
-
c_call,一个 c 函数将要被调用。
-
c_exception,调用 c 函数的时候产生了异常。
自己动手实现一个简单的调试器
在本小节当中我们将实现一个非常简单的调试器帮助大家理解调试器的实现原理。调试器的实现代码如下所示,只有短短几十行却可以帮助我们深入去理解调试器的原理,我们先看一下实现的效果在后文当中再去分析具体的实现:
import sys
file = sys.argv[1]
with open(file, "r+") as fp:
code = fp.read()
lines = code.split("\\n")
def do_line(frame, event, arg):
print("debugging line:", lines[frame.f_lineno - 1])
return debug
def debug(frame, event, arg):
if event == "line":
while True:
_ = input("(Pdb)")
if _ == \'n\':
return do_line(frame, event, arg)
elif _.startswith(\'p\'):
_, v = _.split()
v = eval(v, frame.f_globals, frame.f_locals)
print(v)
elif _ == \'q\':
sys.exit(0)
return debug
if __name__ == \'__main__\':
sys.settrace(debug)
exec(code, None, None)
sys.settrace(None)
在上面的程序当中使用如下:
- 输入 n 执行一行代码。
- p name 打印变量 name 。
- q 退出调试。
现在我们执行上面的程序,进行程序调试:
(py3.10) ➜ pdb_test git:(master) ✗ python mydebugger.py pdbusage.py
(Pdb)n
debugging line: def m99():
(Pdb)n
debugging line: if __name__ == \'__main__\':
(Pdb)n
debugging line: m99()
(Pdb)n
debugging line: for i in range(1, 10):
(Pdb)n
debugging line: for j in range(1, i + 1):
(Pdb)n
debugging line: print(f"ixj=i*j", end=\'\\t\')
1x1=1 (Pdb)n
debugging line: for j in range(1, i + 1):
(Pdb)p i
1
(Pdb)p j
1
(Pdb)q
(py3.10) ➜ pdb_test git:(master) ✗
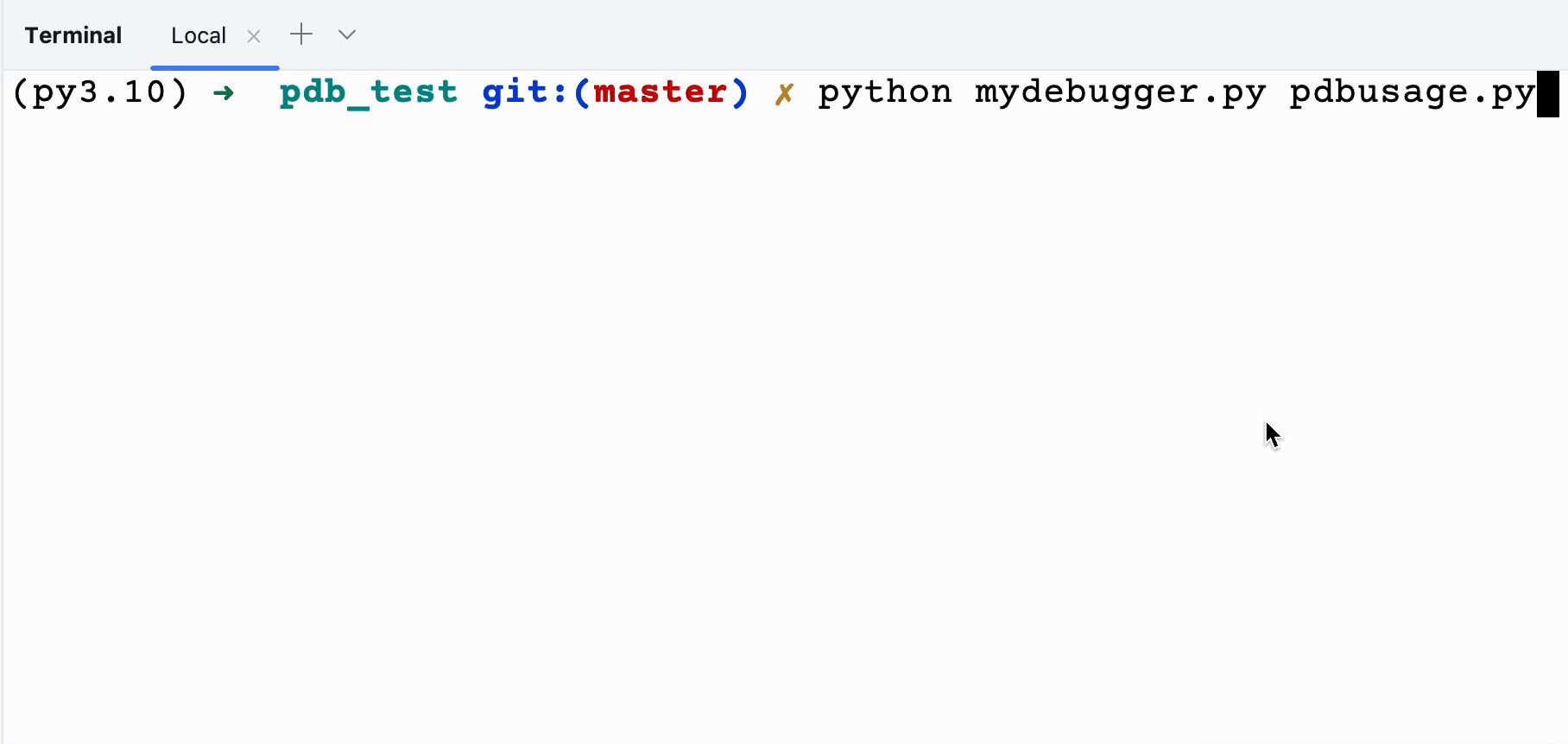
可以看到我们的程序真正的被调试起来了。
现在我们来分析一下我们自己实现的简易版本的调试器,在前文当中我们已经提到了 sys.settrace 函数,调用这个函数时需要传递一个函数作为参数,被传入的函数需要接受三个参数:
-
frame,当前正在执行的栈帧。
-
event,事件的类别,这一点在前面的文件当中已经提到了。
-
arg,参数这一点在前面也已经提到了。
-
同时需要注意的是这个函数也需要有一个返回值,python 虚拟机在下一次事件发生的时候会调用返回的这个函数,如果返回 None 那么就不会在发生事件的时候调用 tracing 函数了,这是代码当中为什么在 debug 返回 debug 的原因。
我们只对 line 这个事件进行处理,然后进行死循环,只有输入 n 指令的时候才会执行下一行,然后打印正在执行的行,这个时候就会退出函数 debug ,程序就会继续执行了。python 内置的 eval 函数可以获取变量的值。
python 官方调试器源码分析
python 官方的调试器为 pdb 这个是 python 标准库自带的,我们可以通过 python -m pdb xx.py 去调试文件 xx.py 。这里我们只分析核心代码:
代码位置:bdp.py 下面的 Bdb 类
def run(self, cmd, globals=None, locals=None):
"""Debug a statement executed via the exec() function.
globals defaults to __main__.dict; locals defaults to globals.
"""
if globals is None:
import __main__
globals = __main__.__dict__
if locals is None:
locals = globals
self.reset()
if isinstance(cmd, str):
cmd = compile(cmd, "<string>", "exec")
sys.settrace(self.trace_dispatch)
try:
exec(cmd, globals, locals)
except BdbQuit:
pass
finally:
self.quitting = True
sys.settrace(None)
上面的函数主要是使用 sys.settrace 函数进行 tracing 操作,当有事件发生的时候就能够捕捉了。在上面的代码当中 tracing 函数为 self.trace_dispatch 我们再来看这个函数的代码:
def trace_dispatch(self, frame, event, arg):
"""Dispatch a trace function for debugged frames based on the event.
This function is installed as the trace function for debugged
frames. Its return value is the new trace function, which is
usually itself. The default implementation decides how to
dispatch a frame, depending on the type of event (passed in as a
string) that is about to be executed.
The event can be one of the following:
line: A new line of code is going to be executed.
call: A function is about to be called or another code block
is entered.
return: A function or other code block is about to return.
exception: An exception has occurred.
c_call: A C function is about to be called.
c_return: A C function has returned.
c_exception: A C function has raised an exception.
For the Python events, specialized functions (see the dispatch_*()
methods) are called. For the C events, no action is taken.
The arg parameter depends on the previous event.
"""
if self.quitting:
return # None
if event == \'line\':
print("In line")
return self.dispatch_line(frame)
if event == \'call\':
print("In call")
return self.dispatch_call(frame, arg)
if event == \'return\':
print("In return")
return self.dispatch_return(frame, arg)
if event == \'exception\':
print("In execption")
return self.dispatch_exception(frame, arg)
if event == \'c_call\':
print("In c_call")
return self.trace_dispatch
if event == \'c_exception\':
print("In c_exception")
return self.trace_dispatch
if event == \'c_return\':
print("In c_return")
return self.trace_dispatch
print(\'bdb.Bdb.dispatch: unknown debugging event:\', repr(event))
return self.trace_dispatch
从上面的代码当中可以看到每一种事件都有一个对应的处理函数,在本文当中我们主要分析 函数 dispatch_line,这个处理 line 事件的函数。
def dispatch_line(self, frame):
"""Invoke user function and return trace function for line event.
If the debugger stops on the current line, invoke
self.user_line(). Raise BdbQuit if self.quitting is set.
Return self.trace_dispatch to continue tracing in this scope.
"""
if self.stop_here(frame) or self.break_here(frame):
self.user_line(frame)
if self.quitting: raise BdbQuit
return self.trace_dispatch
这个函数首先会判断是否需要在当前行停下来,如果需要停下来就需要进入 user_line 这个函数,后面的调用链函数比较长,我们直接看最后执行的函数,根据我们使用 pdb 的经验来看,最终肯定是一个 while 循环让我们可以不断的输入指令进行处理:
def cmdloop(self, intro=None):
"""Repeatedly issue a prompt, accept input, parse an initial prefix
off the received input, and dispatch to action methods, passing them
the remainder of the line as argument.
"""
print("In cmdloop")
self.preloop()
if self.use_rawinput and self.completekey:
try:
import readline
self.old_completer = readline.get_completer()
readline.set_completer(self.complete)
readline.parse_and_bind(self.completekey+": complete")
except ImportError:
pass
try:
if intro is not None:
self.intro = intro
print(f"self.intro = ")
if self.intro:
self.stdout.write(str(self.intro)+"\\n")
stop = None
while not stop:
print(f"self.cmdqueue = ")
if self.cmdqueue:
line = self.cmdqueue.pop(0)
else:
print(f"self.prompt = self.use_rawinput")
if self.use_rawinput:
try:
# 核心逻辑就在这里 不断的要求输入然后进行处理
line = input(self.prompt) # self.prompt = \'(Pdb)\'
except EOFError:
line = \'EOF\'
else:
self.stdout.write(self.prompt)
self.stdout.flush()
line = self.stdin.readline()
if not len(line):
line = \'EOF\'
else:
line = line.rstrip(\'\\r\\n\')
line = self.precmd(line)
stop = self.onecmd(line) # 这个函数就是处理我们输入的字符串的比如 p n 等等
stop = self.postcmd(stop, line)
self.postloop()
finally:
if self.use_rawinput and self.completekey:
try:
import readline
readline.set_completer(self.old_completer)
except ImportError:
pass
def onecmd(self, line):
"""Interpret the argument as though it had been typed in response
to the prompt.
This may be overridden, but should not normally need to be;
see the precmd() and postcmd() methods for useful execution hooks.
The return value is a flag indicating whether interpretation of
commands by the interpreter should stop.
"""
cmd, arg, line = self.parseline(line)
if not line:
return self.emptyline()
if cmd is None:
return self.default(line)
self.lastcmd = line
if line == \'EOF\' :
self.lastcmd = \'\'
if cmd == \'\':
return self.default(line)
else:
try:
# 根据下面的代码可以分析了解到如果我们执行命令 p 执行的函数为 do_p
func = getattr(self, \'do_\' + cmd)
except AttributeError:
return self.default(line)
return func(arg)
现在我们再来看一下 do_p 打印一个表达式是如何实现的:
def do_p(self, arg):
"""p expression
Print the value of the expression.
"""
self._msg_val_func(arg, repr)
def _msg_val_func(self, arg, func):
try:
val = self._getval(arg)
except:
return # _getval() has displayed the error
try:
self.message(func(val))
except:
self._error_exc()
def _getval(self, arg):
try:
# 看到这里就破案了这不是和我们自己实现的 pdb 获取变量的方式一样嘛 都是
# 使用当前执行栈帧的全局和局部变量交给 eval 函数处理 并且将它的返回值输出
return eval(arg, self.curframe.f_globals, self.curframe_locals)
except:
self._error_exc()
raise
总结
在本篇文章当中我们主要分析 python 当中实现调试器的原理,并且通过一个几十行的代码实现了一个非常简单的调试器,这可以深入帮助我们理解调试器实现的细节,这让我们对于程序设计语言的认识又加深了一点。最后简单的介绍了一下 python 自己的调试器 pdb,但是有一点遗憾的目前 pdb 还不能够支持直接调试 python 字节码,但是在 python 虚拟机当中已经有调试字节码的事件了,相信在未来应该可以直接调试字节码了。
还记得我们在讨论 frameobject 的时候有一个字段 f_trace 嘛,这个字段就是指向我们传递给 sys.settrace 的函数,当发生事件的时候虚拟机就会调用这个函数。
本篇文章是深入理解 python 虚拟机系列文章之一,文章地址:https://github.com/Chang-LeHung/dive-into-cpython
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
深入理解pythonpython语法总结:基础知识和对python中对象的理解
用python也用了两年了,趁这次疫情想好好整理下。
大概想法是先对python一些知识点进行总结,之后就是根据python内核源码来对python的实现方式进行学习,不会阅读整个源码,,,但是应该会把数据结构的实现、函数调用过程、以及python虚拟机的基本原理根据源码解释下。
当然限于笔者只是一个弱鸡,,,如内容有疏漏的地方或者是一些错误,希望看到的大佬不吝赐教。
第一部分 python语法总结
当然如果对python语法还是一无所知的同学请移步缪雪峰或者菜鸟教程等学习网站看一遍再过来,,,,这里只是进行一些简单的总结
当然,在这之中我会着重的标明一些python2和python3中的区别,具体的结构如下:
1.数据结构
2.选择循环
3.字符串与编码
4.函数
5.面向对象编程
6.异常处理以及python的模块
基础知识
当然,在开始之前我们还要简单的回顾一下基本知识(当然仅仅是列出一些要注意的点):
1.一切皆对象的思想
对象是python中最基本的概念,在python中处理的每个东西都可以称为对象,而同时python的变量都可以看成是内存中某个对象的引用。
关于引用的一个示例如图:
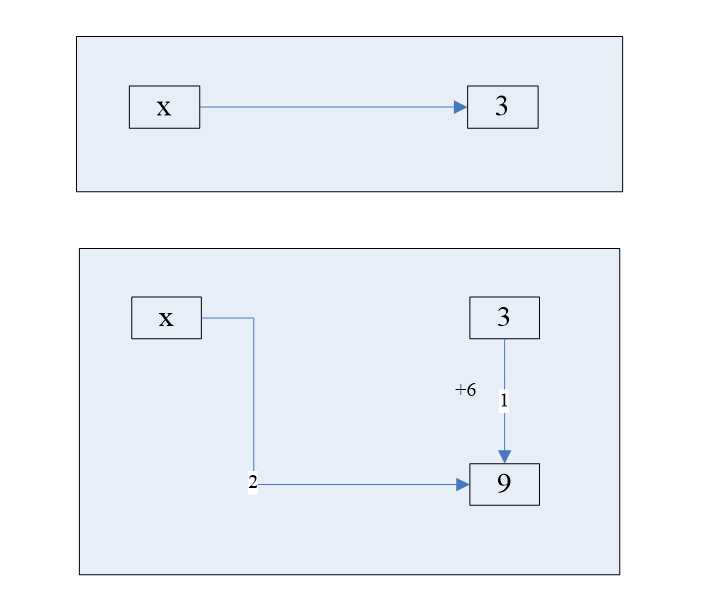
3,9即放在内存中的对象,而x则是对之的引用,当改变3的值的时候,只是将x指向的对象指向了9,而并没有改变3的值。
之后则是关于可变对象和不可变对象:
- 可变对象和不可变对象是指内容是否可以被改变。
- 不可变对象包括:number,string,tuple,
- 可变对象包括:list,set,dict
下面给出几个例子来说明上面的问题:
>>> a=1 >>> id(a) 491508784 >>> b=1 >>> id(b) 491508784 >>> c=[1,2,3] >>> id(c) 45265984 >>> d=[1,2,3] >>> id(d) 3252992 >>> a==b True >>> c==d True >>> a is b True >>> c is d False
我们可以看到,对于不可变对象,在内存中地址是唯一的,而对于可变对象,即便值相等,但是在内存中的存储却是两个不同的对象。同时python中“is”关键字是比较两个引用引用的是否为一个对象,而对于==则是比较的是对应值
再来一个例子:
>>> a=1 >>> b=a >>> a+=1 >>> a 2 >>> b 1 >>> a=[1,2,3] >>> b=a >>> b [1, 2, 3] >>> a[0]=0 >>> a [0, 2, 3] >>> b [0, 2, 3] >>> a*=2 >>> a [0, 2, 3, 0, 2, 3] >>> b [0, 2, 3, 0, 2, 3] >>> a=a*2 >>> a [0, 2, 3, 0, 2, 3, 0, 2, 3, 0, 2, 3] >>> b [0, 2, 3, 0, 2, 3]
我们可以看到,由于数字是不可变对象,所以改变a,将a指向的对象改变了,b仍然是之前所指的值。而对于可变对象,由于a,b值得是同一对象,所以通过索引改变a的时候,b也会跟着改变。
但是对于a=a*2这个操作,并没有对a进行原地(在对象上的)改变,相当于对重新创建了一个a*2的对象使a指向它,所以b并没有改变,但a*=2这个操作则是原地的,所以b也会跟着改变。
所以为了避免索引改变值,我们引用了copy操作
>>> a = [1, 2, 3] >>> b = a[:] >>> id(a) 140200275166560 >>> id(b) 140200275238712 # 由于 b 引用的是 a 引用对象的一个拷贝,两个变量指向的内存空间不同 >>> a[0] = 0 >>> b [1, 2, 3] # 改变 a 中的元素并不会引起 b 的变化
或
>>> import copy
>>> b = copy.copy(a)
当然,还会有浅层copy和深层copy的区别,浅层只是对父对象进行了拷贝,而深层拷贝则是除了顶层拷贝外将所有的子对象也进行了拷贝,如下例:
>>> a=[[1,2,3],0,3] >>> b=a.copy() >>> a[0][0]=0 >>> b [[0, 2, 3], 0, 3] >>> a[1]=1 >>> a [[0, 2, 3], 1, 3] >>> b [[0, 2, 3], 0, 3] >>> import copy >>> c=copy.deepcopy(a) >>> a[0][0]=3 >>> a [[3, 2, 3], 1, 3] >>> c [[0, 2, 3], 1, 3]
关于可迭代对象,这个就放在后面说,这里就不展开了。
之后是关于对象的回收
上每个象包含一个引用的计数器,计数器记录了当前指向该对象引用的数目,一旦对象的计数器为 0 ,即不存在对该对象的引用,则这个对象的内存空间会被回收。这就是 Python 中对象的回收机制,一个最明显的好处即在编写代码过程中不需要考虑释放内存空间。
2.几个python2和python3的差别
a.内置函数map()可以将一个单参数函数依次作用到一个序列的每个元素上,并返回:
一个列表作为结果(Python 2)
一个map对象(它是一个可迭代对象)作为结果 (Python 3)
b.python2和python3除法的区别:
Python中的除法有两种,整数除法(整除运算)和真除法
Python 2和Python 3对“/”运算符的解释有区别
Python 2将“/”解释为整数除法,而Python 3将其解释为真除法。例如,在Python 3中运算结果如下:
>>> 3/5 0.6 >>> 3//5 0 >>> 3.0/5 0.6 >>> 3.0//5 0.0 >>> 13//10 1
python2:
>>> 3/5 0 >>> 3//5 0 >>> 3.0/5 0.6 >>> 3.0//5 0.0 >>> 13//10 1
c.基本输入输出的区别
python2中input函数会根据所输入的界定符来判断对象类型,如输入1为整型,而输入‘1’为字符串型。
python2中raw_input会将所有的输入看为字符串
而python3中则没有raw_input,其input的作用就相当于python2中raw_input的作用
还有就是print函数的区别,相比大家已经很熟悉,这里不再阐述。
3.几个常用的内置函数,个人认为比较重要的几个
map函数,第一个传入一个函数,第二个参数传入一个列表,返回对列表中每个项使用第一个参数函数的结果(pyhon2和3返回的结果类型不同)
如(python3):
>>> a=[1,2,3] >>> map(str,a) >>> c=map(str,a) >>> type(c) <class ‘map‘> >>> list(c) [‘1‘, ‘2‘, ‘3‘]
dir()函数可以查看指定模块中包含的所有成员或者指定对象类型所支持的操作
ord()和chr()是一对功能相反的函数,ord()用来返回单个字符的序数或Unicode码,而chr()则用来返回某序数对应的字符
以上是关于深入理解python虚拟机:调试器实现原理与源码分析的主要内容,如果未能解决你的问题,请参考以下文章