前言
前面国庆节的时候写过一个简易的爬虫。
还没看过的同学可以先看一下,这只爬虫主要用来爬取各个博客平台的阅读量等数据,一直以来都是每天晚上我自己手动在本地电脑运行,中间也有过几次忘记运行了,导致没有当天的统计数据。
当然最好的办法就是把这只爬虫部署在服务器上,让服务器定时去运行,这样就不需要我每天人工运行了,还有另外一件事就是之前也说了要做一个统计页面,自己挖的坑,要自己填起来。

正好最近各个云服务厂商都在搞双十一的活动,小编一眼看下去,都是新用户才能享受优惠,还好,小编在京东云还是新用户,购买了京东云的服务。
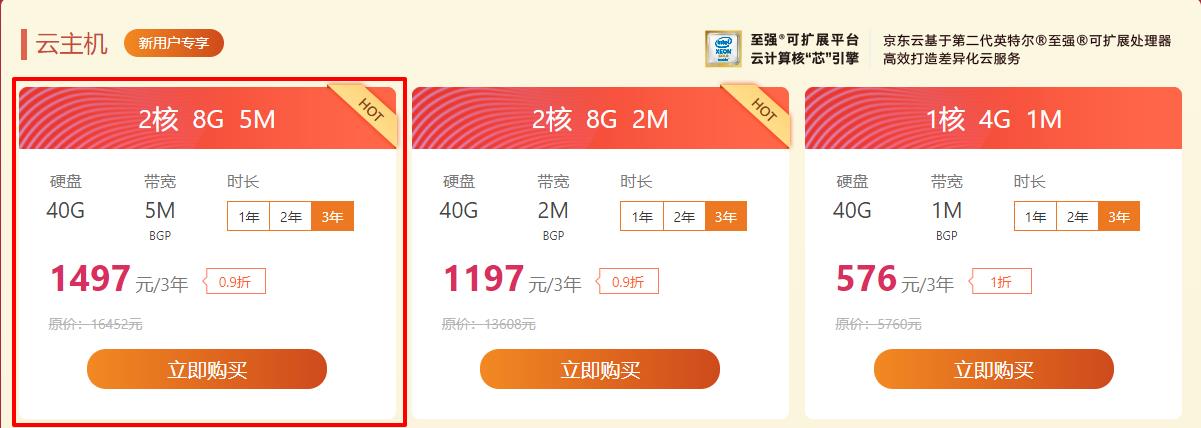
这个价格实在是太!贵!了!

一般自己测试使用没必要买和我同款的机器,小编买这个是为了后面有一些其他的服务也可以部署在上面。
闲话不多说,我们正式开始吧。
前置环境准备
新机器拿到手,除了上面装好了一个 CentOS 以外,啥都没有了,第一步当然是先把环境装起来啊。
先列举下我们要装的软件:
- Docker
- Mysql
- Python3
- Java8
- Nginx
先装这么多吧,后续有补充的话再接着装。
Docker
首先什么是 Docker 请各位同学自己摆渡好吧,我简单解释一下 Docker 是一个容器,这个容器中可以运行很多的程序,这些程序之间互不干扰,如果其中那个程序在使用的过程中配置不对搞不定了,只需要将对应的 container 停止掉删除掉重新启动一个即可,从这一点上来讲类似于一个沙盒环境。这一点上尤其是数据库,本人拥有者丰富的在本地安装 Mysql 把 Mysql 玩脱了重新安装的经验。还是 Docker 好用。

开始安装 Docker ,首先时用自己喜欢的工具连接到远程的服务器上(小编这里使用的是 xshell ),或者也可以自己本地安装对应的 CentOS 虚拟机(win 环境下安装 CentOS 虚拟机又可以写一篇教程了,尤其是其中的网络配置,第一次安装的同学十有八九都卡在这里,有需要的同学可以在公众号给我留言)。
连接成功后如下图:
好像把 ip 露出来了,emmmmmmmmmmmmm ,各位大佬,没事干别攻击小编的机器,拜谢。
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3: 更新并安装 Docker-CE
sudo yum makecache fast
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo systemctl start docker
如果 Linux 是使用 root 账号登录,命令中无需添加 sudo ,这个关键字的含义是使用管理员权限执行命令。
Docker 默认的镜像源在遥远的太平洋的另一端,可以配置国内的镜像加速来加块我们的拉取速度,小编这里选择的是阿里云的镜像加速,配置方式如下:
# 创建文件夹
sudo mkdir -p /etc/docker
# 写入配置内容
sudo tee /etc/docker/daemon.json <<-\'EOF\'
{
"registry-mirrors": ["https://12ofullf.mirror.aliyuncs.com"]
}
EOF
# 重启服务
sudo systemctl daemon-reload
sudo systemctl restart docker
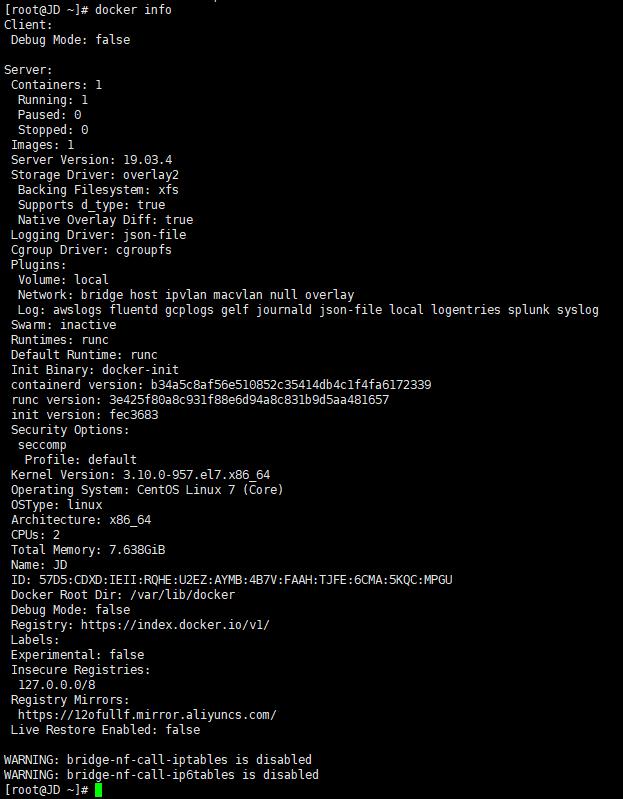
至此,Docker 安装配置就完成了,可以使用如下命令查看 Docker 的相关信息来验证 Docker 正常安装:
docker info
页面正常打印如下:
Mysql
Mysql 可以有两种安装方式,一种是直接在 CentOS 上进行安装,另一种是在 Docker 中进行安装,这里小编选择后一种,别问为啥,问就是简单、方便、快捷。
小编这里安装的 Mysql 选择版本为 5.7 ,安装命令如下:
docker pull mysql:5.7
等进度条走完,好了,我们已经装好了 Mysql ,是不是很简单。

当然,我们刚才只是把 Mysql 的景象给 pull 下来了,接下来的启动才是关键。
docker run --name mysql --restart=always -p 3306:3306 -v /www/mysql/conf.d:/etc/mysql/conf.d -v /www/mysql/mysql.conf.d:/etc/mysql/mysql.conf.d -v /www/mysql/datadir:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 -e TZ=Asia/Shanghai -d mysql:5.7
这个命令稍微有点长,不过没关系,直接 Copy 就 Ok。
稍微解释下其中的含义吧:
--restart 标志会检查容器的退出代码,并据此来决定是否要重启容器,默认是不会重启。
--restart 的参数说明:
- always:无论容器的退出代码是什么,Docker都会自动重启该容器。
- on-failure:只有当容器的退出代码为非0值的时候才会自动重启。另外,该参数还接受一个可选的重启次数参数,
--restart=on-fialure:5表示当容器退出代码为非0时,Docker会尝试自动重启该容器,最多5次。
-v 容器内的 /var/lib/mysql 在宿主机上 /www/mysql/datadir 做映射
-e MYSQL_ROOT_PASSWORD 初始密码
-p 将宿主机3306的端口映射到容器3306端口
接下来我们测试下刚才安装的 Mysql ,当然是使用本地的连接工具看下是否能正常连接啊,这里的工具小编选择了 Navicat 这一经典的 Mysql 连接工具。
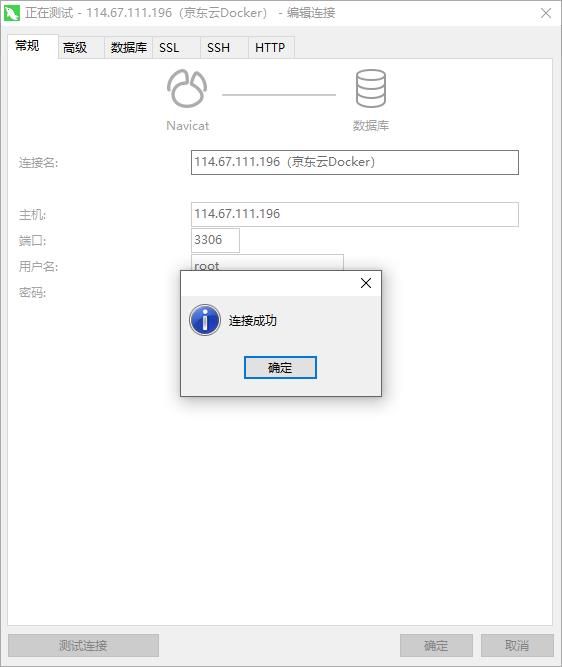
测试链接成功,我们的 Mysql 安装完成。
Nginx
Nginx 是一款优秀的反向代理工具,详细的信息各位同学可以摆渡,简单描述下使用场景的话就是我一台服务器上可以启动多个服务,通过 Nginx 反向代理,可以映射多个域名,使用不同的域名访问不同的服务,当然 Nginx 的功能远不止这些。
首先,打开 Nginx 的官网( http://nginx.org/en/download.html ),选择一个你喜欢的版本,Copy 到它的下载链接:
然后我们使用 wget 命令来下载它。
cd /opt/
wget http://nginx.org/download/nginx-1.17.5.tar.gz
小编这里选择的 Nginx 的版本为 1.17.5 。
等待进度条走完,这时我们得到了一个 Nginx 的压缩包,接下来解压它。
tar -xvzf nginx-1.17.5.tar.gz
然后我们需要安装 nginx 的编译环境:
yum install -y gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel
等待进度条走完。
进入我们刚才解压的目录:
cd nginx-1.17.5
开始配置、编译、安装:
./configure
make && make install
一小段时间的等待。
等待执行完成后,可以看到 Nginx 已经帮我们安装到 /usr/local/nginx/ 这个目录下了,接下来我们可以创建一个软连接,让我们在任何目录都可以直接执行 nginx 的命令:
ln -s /usr/local/nginx/sbin/nginx /usr/local/sbin/
nginx 相关命令
# 启动
nginx
# 停止
nginx -s quit 或者 nginx -s stop
# 重启
nginx -s reload
我们启动 nginx ,打开浏览器访问直接访问ip,如图:
Nginx 已经安装完成,反向代理的配置我们后面用到了再聊,这里先酱。
Java8
统计报表服务小编这里计划使用 Java 来写,当然 Java 程序也可以放入 Docker 中运行,不过配置 Java 环境就是一件顺手的事情,顺便做了吧:)
首先一样,先下载 JDK8 ,并且将 JDK8 放入 /opt/ 目录中。
因为小编这里本地有下好的,就不去下载了,大家可以访问 Oracle 的官网下载。
小编这里给一个下载链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
回到我们的 CentOS :
cd /opt/
ll

小编这里使用的 jdk 的版本是 8u221 。
直接解压:
tar -xvzf jdk-8u221-linux-x64.tar.gz
好了,我们又安装完了,当然还需要配置下环境变量,直接编辑 /etc/profile 这个文件,在文件中加入我们的环境变量:
# 编辑
vi /etc/profile
写入环境变量如下:
# 先按 i 开启插入模式,写入以下内容
export JAVA_HOME=/opt/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
退出保存时先按 esc 键,输入 :wq ,再按回车键 enter 。
这时需要刷新下配置文件:
source /etc/profile
我们来测试刚才配置的 jdk 环境变量是否生效:
# 输入
java -version
# 输出
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
# 输入
javac -version
# 输出
javac 1.8.0_221
jdk 安装完成
Python3
终于到了最重要的 Python3 的安装了 。

首先一样,去 Python 的官网,找到对应版本的 Python3 的下载地址,进入 /opt/ 目录进行下载:
官网下载链接:https://www.python.org/downloads/source/
小编这里选择的是截止目前最新发布的 3.8.0 版本。
wget https://www.python.org/ftp/python/3.8.0/Python-3.8.0.tgz
下载完成后直接解压:
tar -xvzf Python-3.8.0.tgz
解压后编译安装:
# 创建安装目录
mkdir /usr/local/python3
cd Python-3.8.0
# 检查配置
./configure --prefix=/usr/local/python3
# 编译、安装
make && make install
# 创建软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
测试安装结果:
# 输入
python3 -V
# 输出
Python 3.8.0
至此,前置环境已经搭建完成~~~
部署爬虫
我们前面写的爬虫是一个 .py ,先把这个文件上传至服务器,目录自己喜欢就好,小编一般放置在 /opt/ 目录下。
由于我们的爬虫引用了一些第三方的模块,这里需要先安装这些模块:
pip3 install lxml pymysql
安装完成后我们执行一下之前的脚本:
# 输入
python3 /opt/pythonproject/spider-demo.py
# 输出
---------CSDN 数据写入完成---------
---------掘金 数据写入完成---------
---------CNBLOG 数据写入完成---------
可以看到执行成功,接下来,我们要为 CentOS 设置定时任务,暂时先设置成每天的整点执行一次我们的 Python 爬虫,便于我们分辨当前的任务是否执行。
定时任务我们是使用 crontab 来完成的,如果当前的 CentOS 不含有 crontab ,可以先进行安装:
yum install crontabs -y
几个基础命令了解一下:
/sbin/service crond start //启动服务
/sbin/service crond stop //关闭服务
/sbin/service crond restart //重启服务
/sbin/service crond reload //重新载入配置
查看crontab服务状态:service crond status
我们先配置定时任务:
# 进入任务计划设置
crontab -e
# 计划内容
0 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23 * * * python3 /opt/pythonproject/spider-demo.py
# 保存退出
:wq
任务配置完成后,重新载入一下配置,或者重启一下服务都是可以的。
接下来就是静静的等待一小时后看下数据有没有正常的写入数据库。
统计报表
统计报表使用 Java 来完成,后端使用技术为 SpringBoot + Mybatis + Thymeleaf 。前端设计技术为 Vue + Element(饿了么前端组件库)。
具体实现就不列举了,有兴趣的同学可以访问代码仓库获取。
成品大致是酱紫滴:
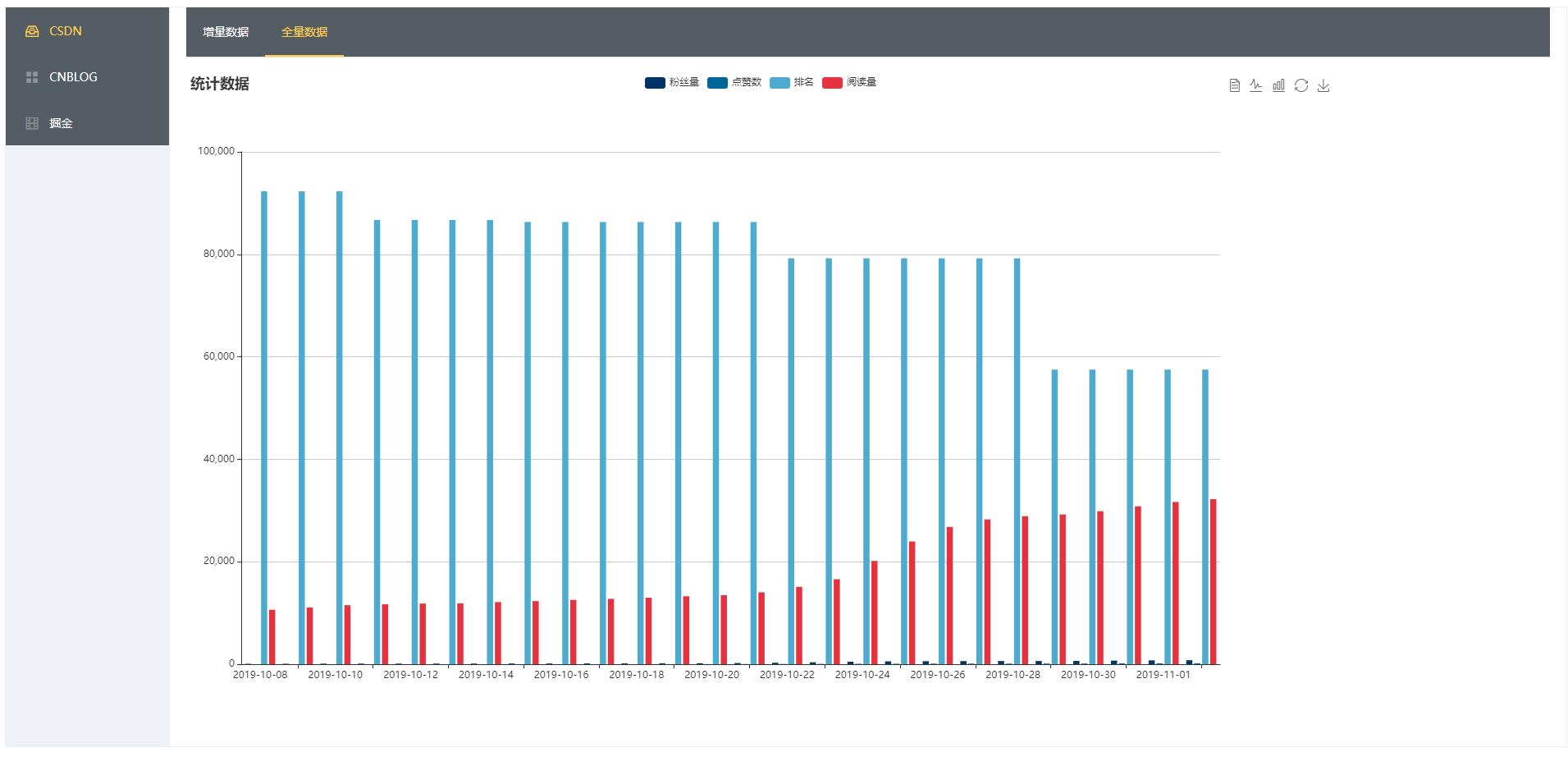
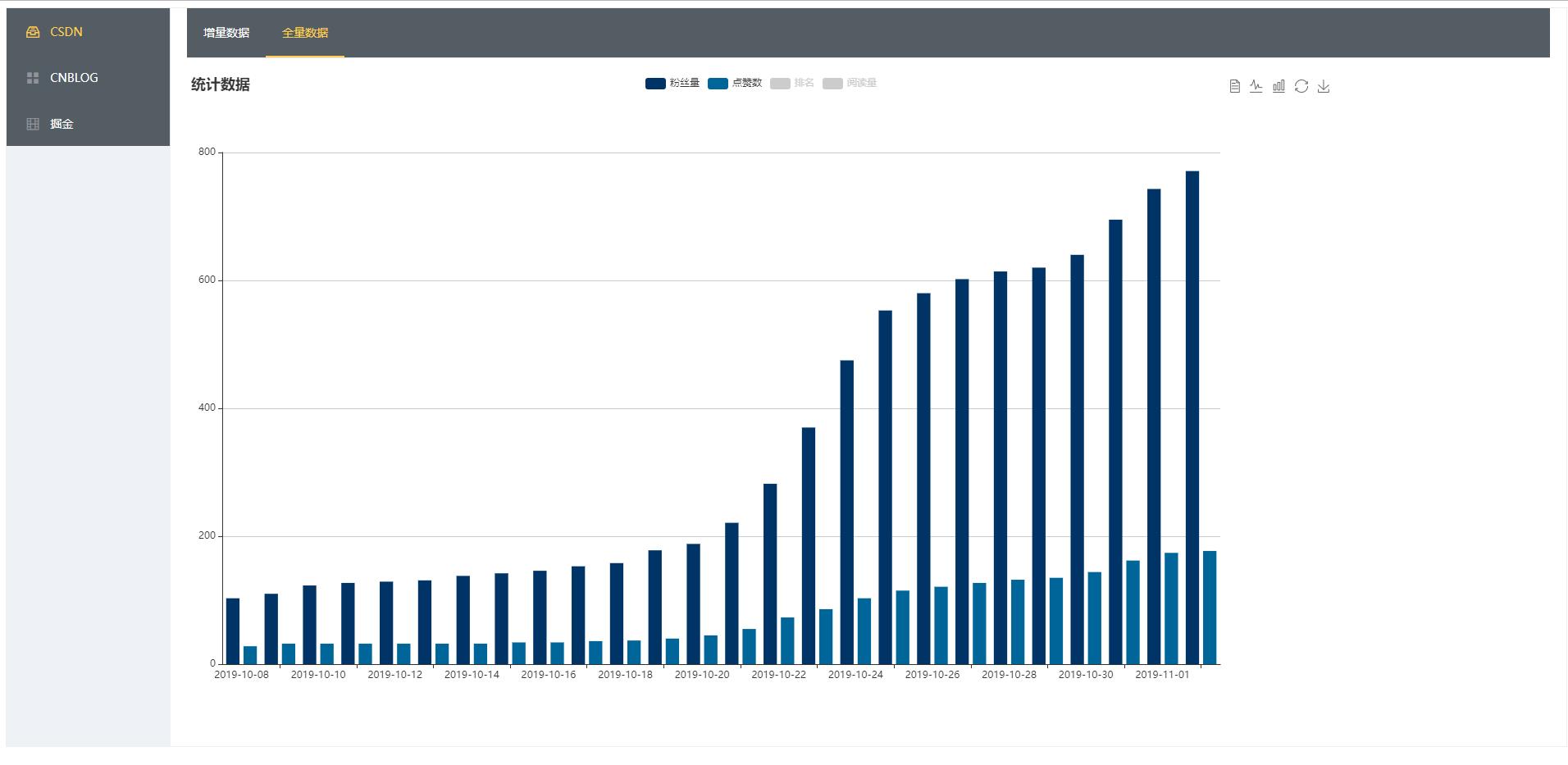
Java 程序发布大致介绍一下吧,在服务器上创建一个自己喜欢的目录,将本地的程序打包后拖上去,执行下面的命令:
nohup java -jar /opt/project/tongji.jar >tongji.out 2>&1 &
就启动成功了。当然也可以将这个程序打成 Docker 镜像(这个后续有机会再聊吧),通过 Docker 来启动 Java 服务。
你以为这就完了么?怎么可能,我们还有 Nginx 没有用呢,下面来介绍如何通过 Nginx 来反向代理一个域名。
首先,你要有一个域名,小编的域名是在腾讯云购买的,并且完成了备案,可以随心所欲的使用啦~~~~
首先,自定义一个域名指向我们的服务器,大致是这样滴:

稍微等一会,等 DNS 生效。然后我们访问域名:http://tongji.geekdigging.com/ ,这时可以看到页面跳转至 Nginx 的首页:
接下来我们要配置 Nginx 的反向代理了。
首先在 /usr/local/nginx/conf/nginx.conf 这个文件的最后增加一句话:
include /etc/nginx/vhost/*.conf;
因为我们后面可能会配置很多域名,这里直接将所有的域名相关的配置文件都放在 /etc/nginx/vhost/ 这个目录下,方便管理, nginx 自身的配置文件我们不多做修改。
我们在 /etc/nginx/vhost/ 创建 tongji.conf 文件,其中内容如下:
server {
listen 80;
autoindex on;
server_name tongji.geekdigging.com;
access_log off;
# access_log /usr/local/nginx/logs/fuhui_access.log combined;
error_log /usr/local/nginx/logs/fuhui_error.log error;
index index.html index.htm index.jsp index.php;
if ( $query_string ~* ".*[\\;\'\\<\\>].*" ){
return 404;
}
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Client-IP $remote_addr;
proxy_set_header X-Forward-For $remote_addr;
}
}
完成后重启 Nginx :
nginx -s reload
然后我们就能通过域名访问自己的统计报表了,如图:
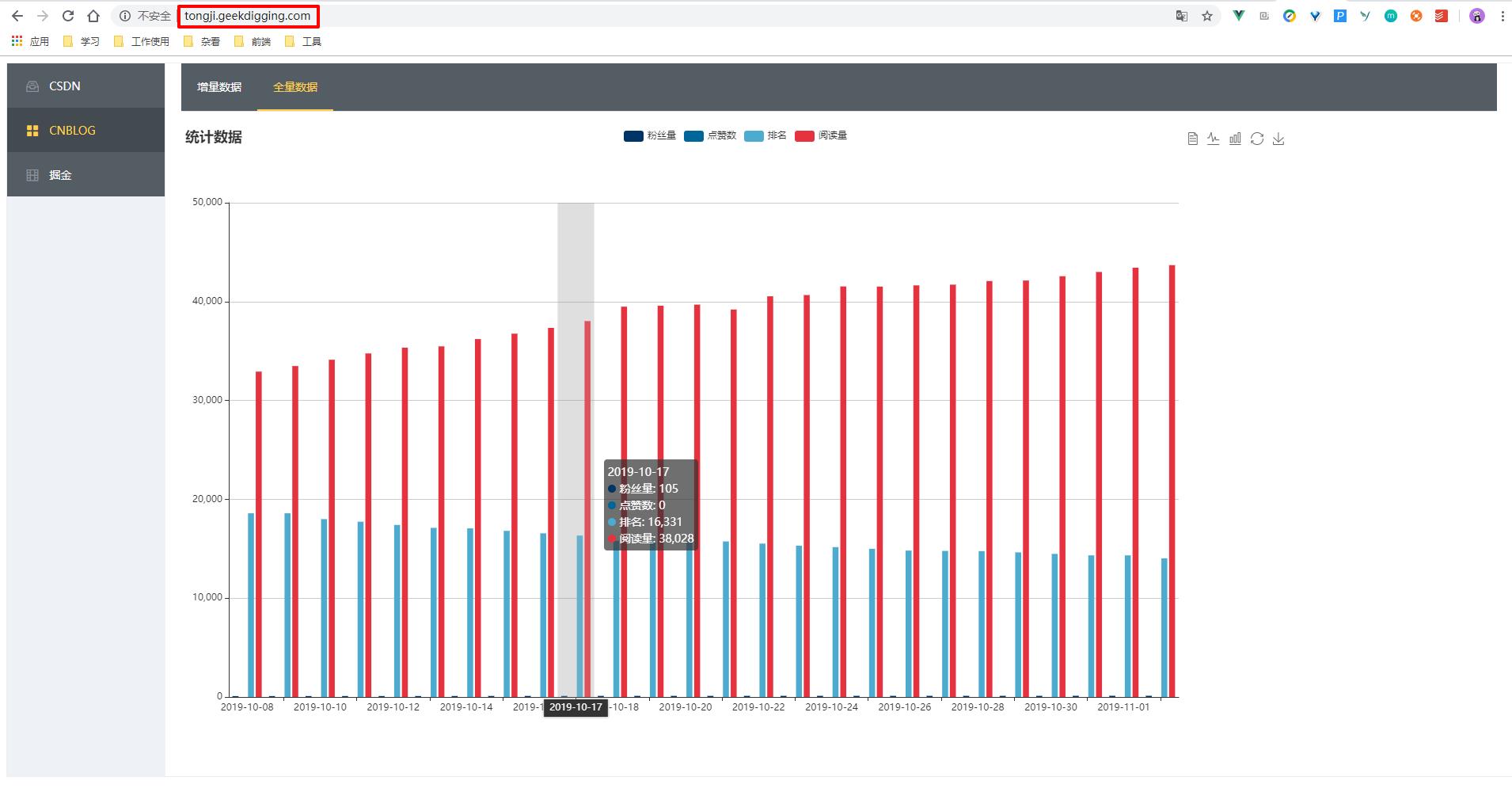
具体链接为:http://tongji.geekdigging.com/ ,感兴趣的小伙伴可以自己试试看,有不清楚的地方可以在公众号留言问我。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
参考
https://yq.aliyun.com/articles/110806?spm=5176.8351553.0.0.12931991GMAstw