32位汇编怎么编译程序 我看罗云斌的32位汇编书看到第二章卡住了,
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了32位汇编怎么编译程序 我看罗云斌的32位汇编书看到第二章卡住了,相关的知识,希望对你有一定的参考价值。
搞了一天了 还是编译不了汇编程序.用nmake 到底怎么编译程序,我要一个详细的编译过程
参考技术A 要了解nmake语法用RadASM很不错的IDE
64位汇编第二讲——64位汇编中局部变量使用及抬栈方法29171230
一.纯写64位汇编时局部变量处理和参数寄存器保存位置
纯写64位汇编和用VS2013写64位C代码生成的汇编会有一些格式上的区别,VS2013写64位C代码生成的汇编中是没用到栈基址寄存器rbp的,但是纯写汇编时只要申明了参数和使用了@LOCAL定义的局部变量,就会用到rbp。且看如下例子:1)用C写64位程序空函数生成的汇编代码,
;C代码 void FunTest2() { } ;汇编代码 000000013F753290 40 57 push rdi 000000013F753292 5F pop rdi 000000013F753293 C3 ret
2)在*.asm文件中写一个空函数,并且生成可执行文件,然后在X64dbg中查看其汇编代码如下, |
;无参无@LOCAL局部变量时的情形,不过会比较少,因为不多时候都会用到@LOCAL局部变量 MyAdd proc ret MyAdd endp 000000013F231000 | C3 | ret | ;申明了参数的情形 MyAdd proc n1:DWORD, n2:DWORD, n3:DWORD, n4:DWORD, n5:DWORD, n6:DWORD ret MyAdd endp 000000013F5A1000 | 55 | push rbp | 000000013F5A1001 | 48 8B EC | mov rbp,rsp | 000000013F5A1004 | C9 | leave | 000000013F5A1005 | C3 | ret | ;用到@LOCAL定义的局部变量的情形 MyAdd proc ;n1:DWORD, n2:DWORD, n3:DWORD, n4:DWORD, n5:DWORD, n6:DWORD LOCAL @n : Qword ret MyAdd endp 000000013FBB1000 | 55 | push rbp | 000000013FBB1001 | 48 8B EC | mov rbp,rsp | 000000013FBB1004 | 48 83 C4 F8 | add rsp,FFFFFFFFFFFFFFF8 | 000000013FBB1008 | C9 | leave | 000000013FBB1009 | C3 | ret
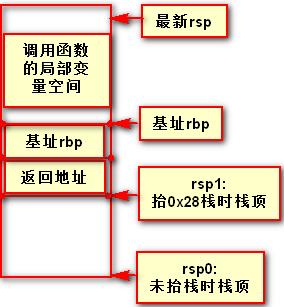
在写汇编代码时,如果用到基址寄存器,则不用每次都计算抬栈的个数,能大大的方便程序员写代码。在上一次课中讲到64位汇编会腾出至少0x28的空间给调用的函数保存参数寄存器,那么腾出来后该如何存放,参数寄存器的值存放抬0x28字节栈的地址处,因为此时用栈基址寄存器很好访问,如下:
其实在64位程序的设计上,如果有第五个或以上的参数,则是要通过栈传参的,同一个函数中所有的call中,在第一个call之前将所有的参数所需栈大小一起抬了,这能减少函数参数的出栈和入栈,从而提高效率。当然,试想我们能不能在call之间还抬栈呢?是不能的,因为只要一抬栈,rsp的值必然会改变,那么call的函数中要保存参数寄存器通过rsp+8寻址就会有偏差了。其实咋一看这样设计会给64位汇编程序开发造成很大的麻烦,因为每添加一个有第五个参数的call时,就要重新修改抬栈的数量,不过细细想来,我们可以用宏来开发,这样就可以直接改宏就可以了,并且在每个call前注释好它单个抬的栈的大小,方便之后统计校对。
另外一个问题是64位汇编中程序中,该不该用LOCAL类型的局部变量的。用LOCAL类型的局部变量的好处是可以直接通过结构体对象点出成员,使用很方便,这也是64位汇编中唯一可以用作结构体对象点成员的方法,在32位汇编中还可用ASSUME,但64位汇编中ASSUME失效。另外,LOCAL类型的局部变量还是自动抬栈和平栈的,其中使用到了rbp,但也因此抬了8字节的栈,改变了rsp,所以此时只能由rbp+10h来替代rsp+8来保存参数寄存器的值。那么除了LOCAL类型的局部变量,还可以用户自己抬栈来充当局部变量,这样做相对于LOCAL类型的局部变量自然麻烦很多,因为老是要算esp的值和静态局部变量总的自己大小,当然也不是不可能,用宏的话会稍微方便一些。
二. 64位汇编和32位汇编中数据类型的区别
64位汇编中地址是64位即8字节的,以前32位汇编中使用的结构体中对应到64位汇编中,个数和代表的含义都不边,只是有的成员的字节数会变化,如涉及到地址的都会由四字节变成八字节,64位汇编中现成可使用的*.inc文件比较少,如果非要用,只能自己写,但可以参考32位汇编中的结构体和宏,宏不需要改,直接拷贝就好,但结构体可以根据VS2013中64位汇编中结构体进行一些类型上的更改,主要是DWORD改QWORD。另外,64位汇编中函数声明方式为extern 函数名:proc,如extern UpdateWindow:proc,包的头文件方式同32位汇编。定义参数个数多余四个的函数时,同32位汇编中定义和申明,头四个参数,在一开始就赋予rcx、rdx、r8、r9的值。
以上是关于32位汇编怎么编译程序 我看罗云斌的32位汇编书看到第二章卡住了,的主要内容,如果未能解决你的问题,请参考以下文章