Python爬取中国天气网天气
Posted RhythmLian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取中国天气网天气相关的知识,希望对你有一定的参考价值。
Python爬取中国天气网
基于requests库制作的爬虫。
使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)"
程序正常运行需要在同文件夹下加入一个“data.csv”文件,内容请参考链接: 城市代码
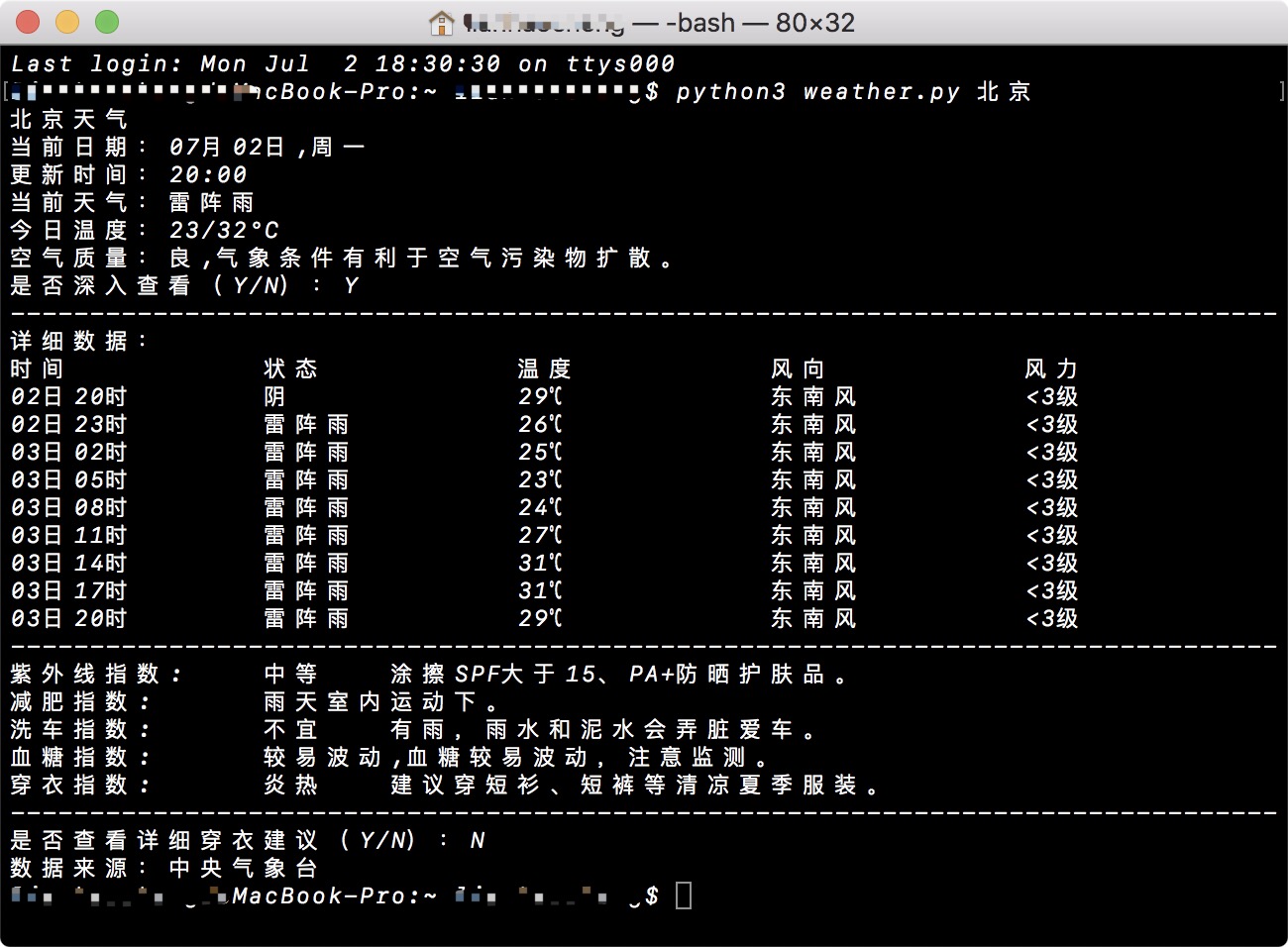
运行效果:
源码:
import sys import re import requests import webbrowser from PIL import Image from requests.exceptions import RequestException import csv data={} with open("data.csv",\'r\') as f: rawinfos=list(csv.reader(f)) for i in rawinfos: data[i[0]]=i[1] def get_one_page(url,headers): try: response=requests.get(url,headers=headers) if response.status_code==200: response.encoding=\'utf-8\' return response.text return None except RequestException: return None headers={\'User-Agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7\'} try: address=data[sys.argv[1]] except: sys.exit("\\033[31m无该城市!\\033[0m") html=get_one_page(\'http://www.weather.com.cn/weather1d/\'+address+\'.shtml\',headers) if not html: print("城市代码有误!") exit(1) ADDRESS=re.findall(\'<title>(.*?)</title>\',html) aim=re.findall(\'<input type="hidden" id="hidden_title" value="(.*?)月(.*?)日(.*?)时(.*?) (.*?) (.*?) (.*?)"\',html,re.S) airdata=re.findall(\'<li class="li6 hot">\\n<i></i>\\n<span>(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\\n</li>\',html,re.S) print(ADDRESS[0][1:5]) print("当前日期:%s月%s日,%s"%(aim[0][0],aim[0][1],aim[0][4])) print("更新时间:%s:00"%aim[0][2]) print("当前天气:%s"%aim[0][5]) print("今日温度:%s"%aim[0][6]) print("空气质量:"+airdata[0][0]+","+airdata[0][2]) ask_ok=input("是否深入查看(Y/N):") if ask_ok==\'Y\' or ask_ok==\'y\': lightdata=re.findall(\'<li class="li1 hot">\\n<i></i>\\n<span>(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\\n</li>\',html,re.S) colddata=re.findall(\'<li class="li2 hot">\\n(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\',html,re.S) weardata=re.findall(\'<li class="li3 hot" id="chuanyi">\\n(.*?)<span>(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\',html,re.S) washdata=re.findall(\'<li class="li4 hot">\\n<i></i>\\n<span>(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\\n</li>\',html,re.S) bloodata=re.findall(\'<li class="li5 hot">\\n<i></i>\\n<span>(.*?)</span>\\n<em>(.*?)</em>\\n<p>(.*?)</p>\\n</li>\',html,re.S) detail = re.findall(\'hour3data={"1d":(.*?),"23d"\', html, re.S) detail = re.findall(\'"(.*?)"\', detail[0], re.S) print("--"*40) print(\'详细数据:\') print("%-10s\\t%-10s\\t%-10s\\t%-10s\\t%-10s"%("时间","状态","温度","风向","风力")) for each in detail: each=each.split(\',\') print("%-10s\\t%-10s\\t%-10s\\t%-10s\\t%-10s"%(each[0],each[2],each[3],each[4],each[5])) print("--"*40) print("%s:\\t%s\\t%s"%(lightdata[0][1],lightdata[0][0],lightdata[0][2])) print("%s:\\t%s"%(colddata[0][1],colddata[0][2])) print("%s:\\t%s\\t%s"%(washdata[0][1],washdata[0][0],washdata[0][2])) print("血糖指数:\\t%s,%s"%(bloodata[0][0],bloodata[0][2])) print("%s:\\t%s\\t%s"%(weardata[0][2],weardata[0][1],weardata[0][3])) print("--"*40) flag=input("是否查看详细穿衣建议(Y/N):") if flag==\'Y\' or flag==\'y\': webbrowser.open("http://www.weather.com.cn/forecast/ct.shtml?areaid="+address) print("数据来源:中央气象台")
以上是关于Python爬取中国天气网天气的主要内容,如果未能解决你的问题,请参考以下文章