06 内存(上)划分与组织内存
Posted xuan01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了06 内存(上)划分与组织内存相关的知识,希望对你有一定的参考价值。
分段分页的问题:
表示方式和状态确定角度:段的长度和大小不一,页大小固定,只需用位图就能表示页的分配与释放;
内存碎片的利用:段的内存碎片会难以利用,页碎片可以利用修改页表的方式,让连续的虚拟页面映射到非连续的物理页面;
内存和硬盘的数据交换效率:遇到内存不足时系统会将一部分数据写回硬盘,释放内存,段的交换时间不一,页没有这个问题 ;
段最大的问题就是是的虚拟内存地址空间难于实施;因此选择页管理内存;4KB,也正好对应长模式下MMU 4KB的分页方式;
如何表示一个页:
真实的物理页内存布局信息来源于:e820map_t 结构数组,在初始化时已经转换为phymmarge_t结构数组了;
若用位图表示页的话:低效,且信息能表示的少;我们还需要页的状态,页的地址,分配模式,类型,链表等,所以考虑用结构体实现;
msadsc_t 结构体;包括 内存空间地址描述符标志 msadflgs_t结构体, 物理地址和标志 phyadrflgs_t结构体;
内存区:
将多个页面划分为几个内存区,如硬件区、内核区、应用区;方便管理;
硬件区:0~32MB范围, 常见的网卡、AHCI、DMA方式,外部设备直接和内存交换数据,不通过CPU的MMU,且只能访问低于24MB的物理内存,所以就将这部分规定用作硬件区分配页;
内核区:内核也使用内存,运行在虚拟地址空间,需要有一段物理内存和虚拟地址空间是 线性映射关系;内核使用内存需要更大、连续的物理内存空间,就在这个区分配;
应用区:给应用用户态程序使用,系统并不会为应用一次性分配完所需的所有物理内存,而是按需分配,用到一页分配一页;;如果访问到一个没有与物理内存页建立映射关系的虚拟内存页,这时候CPU就会产生缺页异常,最终这个缺页异常由系统处理,系统会分配一个物理内存页,并建好映射关系;这是因为这种情况往往分配的是单个页面,所以为了给单个页面提供快捷的内存请求服务,就需要把离散的单页、或者是内核自身需要建好页表才可以访问的页面,统统收归用户区;;
表示内存区的结构:memarea_t 结构体,包括内存区开始地址和结束地址,里面有多少个物理页面,已经分配多少个物理页面;
接下来要把内存区数据结构 和 内存页面数据 结构关联起来;
组织内存页:
定义一个挂载msadsc_t 结构的数据结构 bafhlst_t 结构体,其中需要锁、状态、msadsc_t结构数量、挂载msadsc_t结构的链表、一些统计数据;
这个数据结构只是有了 挂载msadsc_t结构的地方, 形成了bafhlst_t 结构数组,并且把这个bafhlst_t 结构数组放在一个内存分割合并的数据结构中 memdivmer_t ;
分割:表示分配内存, 合并:释放内存;
其中 dm_mdmlielst 结构代表 bafhlsh_t 结构数组,挂载连续的 msadsc_t 结构数量 等于 这个数组下标值左移之后的值,最大值是51,因为2^51 * 2 ^ 12 = 2 ^ 63,对于64位系统,只需要这样的两个数组就能完整表示所有内存;这样做的意义:
1、内存对齐,提升CPU寻址速度 2、内存分配时,根据需求大小快速定位至少从哪一部分开始 3、内存分配时,并发加锁,分组可以提升效率 4、内存分配回收时,很多计算也更简单
我们并不在意其中第一个 msadsc_t结构数组对应的内存物理地址从哪里开始,但是第一个 msdasc_t 结构 与 最后一个msadsc_t 结构 ,它们之间的内存物理地址之间是连续的;
memarea_t 结构体 包含一个内存分割合并 memdivmer_t 结构,这个结构中又包含 dm_mdmlielst 数组; 数组中挂载了 msadsc_t 结构;
如下图:

JDK8中JVM堆内存划分
一:JVM中内存
JVM中内存通常划分为两个部分,分别为堆内存与栈内存,栈内存主要用运行线程方法
存放本地暂时变量与线程中方法运行时候须要的引用对象地址。
JVM全部的对象信息都
存放在堆内存中。相比栈内存,堆内存能够所大的多,所以JVM一直通过对堆内存划分
不同的功能区块实现对堆内存中对象管理。
堆内存不够最常见的错误就是OOM(OutOfMemoryError)
栈内存溢出最常见的错误就是StackOverflowError。程序有递归调用时候最easy发生
二:堆内存划分
在JDK7以及其前期的JDK版本号中。堆内存通常被分为三块区域Nursery内存(young
generation)、长时内存(old generation)、永久内存(Permanent Generation for
VM Matedata),显演示样例如以下图:
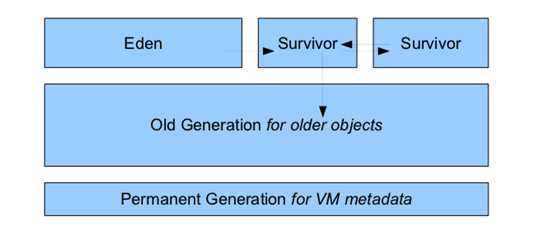
当中最上一层是Nursery内存,一个对象被创建以后首先被放到Nursery中的Eden内
存中,假设存活期超两个Survivor之后就会被转移到长时内存中(Old Generation)中
永久内存中存放着对象的方法、变量等元数据信息。通过假设永久内存不够。我们
就会得到例如以下错误:
java.lang.OutOfMemoryError: PermGen
而在JDK8中情况发生了明显的变化,就是普通情况下你都不会得到这个错误,原因
在于JDK8中把存放元数据中的永久内存从堆内存中移到了本地内存(native memory)
中,JDK8中JVM堆内存结构就变成了例如以下:
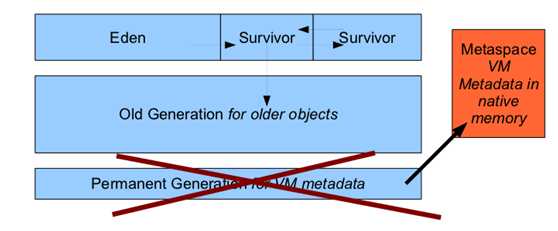
这样永久内存就不再占用堆内存。它能够通过自己主动增长来避免JDK7以及前期版本号中
常见的永久内存错误(java.lang.OutOfMemoryError: PermGen),或许这个就是你的
JDK升级到JDK8的理由之中的一个吧。
当然JDK8也提供了一个新的设置Matespace内存
大小的參数。通过这个參数能够设置Matespace内存大小,这样我们能够依据自己
项目的实际情况,避免过度浪费本地内存,达到有效利用。
-XX:MaxMetaspaceSize=128m 设置最大的元内存空间128兆
注意:假设不设置JVM将会依据一定的策略自己主动添加本地元内存空间。
假设你设置的元内存空间过小,你的应用程序可能得到下面错误:
java.lang.OutOfMemoryError: Metadata space
java1.8之前内存区域分为方法区、堆内存、虚拟机栈、本地方法栈、程序计数器。 下图所示:
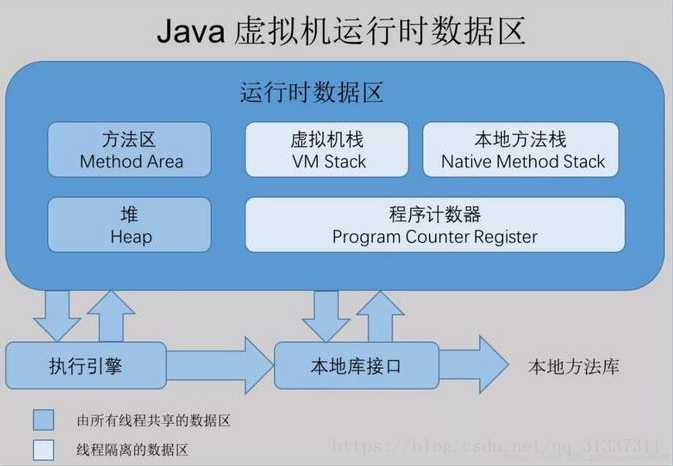
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。很多人都更愿意把方法区称为“永久代”(Permanent Generation)。从jdk1.7已经开始准备“去永久代”的规划,jdk1.7的HotSpot中,已经把原本放在方法区中的静态变量、字符串常量池等移到堆内存中。
在jdk1.8中,永久代已经不存在,存储的类信息、编译后的代码数据等已经移动到了元空间(MetaSpace)中,元空间并没有处于堆内存上,而是直接占用的本地内存(NativeMemory)。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
注意:如果不设置JVM将会根据一定的策略自动增加本地元内存空间。
如果你设置的元内存空间过小,你的应用程序可能得到以下错误:
java.lang.OutOfMemoryError: Metadata space
在Java7之前,HotSpot虚拟机中将GC分代收集扩展到了方法区,使用永久代来实现了方法区。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载。而在Java8中,已经彻底没有了永久代,将方法区直接放在一个与堆不相连的本地内存区域,这个区域被叫做元空间。
常量池里存储着字面量和符号引用。
符号引用包括:1.类的全限定名,2.字段名和属性,3.方法名和属性。
字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
- 1.字符串池常量池在每个VM中只有一份,存放的是字符串常量的引用值,存放在堆中.
- 2.class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用。
- 3.运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
JVM内存参数设置
堆内存设置
- 堆内存(总的)由
-Xms和-Xmx分别设置最小和最大堆内存 - New Generation 由
-Xmn设置,-XX:SurvivorRatio=m设置 Eden和 两个Survivor区的大小比值;-XX:NewRatio=n设置 New Generation 和 Old Generation 的大小比值。 - 每个线程的堆栈大小由 ·-Xss· 设置,JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
非堆内存设置
非堆内存由 -XX:PermSize=n 和 -XX:MaxPermSize=n 分别设置最小和最大非堆内存大小
原文链接:https://blog.csdn.net/xiaoliuliu2050/article/details/102701527
以上是关于06 内存(上)划分与组织内存的主要内容,如果未能解决你的问题,请参考以下文章