Python爬虫入门
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫入门相关的知识,希望对你有一定的参考价值。
Python爬虫简介(来源于维基百科):
网络爬虫始于一张被称作种子的统一资源地址(URLs)列表。当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张"待访列表",即所谓"爬行疆域"(crawl frontier)。此疆域上的统一资源地址将被按照一套策略循环访问。如果爬虫在他执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以被查看。阅读和浏览他们的网站上实时更新的信息,并保存为网站的“快照”。大容量的体积意味着网络爬虫只能在给定时间内下载有限数量的网页,所以要优先考虑其下载。高变化率意味着网页可能已经被更新或者删除。一些被服务器端软件生成的URLs(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。
简单点书,python爬虫就是一个机械化的为你查询网页内容,并且根据你制定的规则返回你需要的资源的一类程序,也是目前大数据常用的一种方式。
代码如下:
from urllib.request import urlopenfrom bs4 import BeautifulSoup
html = urlopen("http://www.jianshu.com")
bsObj = BeautifulSoup(html)
print(bsObj.h1)
nameList=bsObj.findAll("h4",{"class":"title"})for name in nameList:
print(name.get_text())
当然,在此之前,你需要在linux上安装了python3 ,最好是3.5 这样才能保证不出错误,然后我假设是一个安装了ubuntu 16.04 的用户,你现在只需要按照下面的输入代码,就差不多了:
sudo apt-get update更新你的软件源
sudo apt-get install python3-pip下载python库,包文件安装工具
pip3 install bs4下载目前最流行的HTML解析工具之一的BeautifulSoup .
然后,新建一个.py后缀的新文件,写入上述的代码,然后执行,这里是用的bs2.
.py作为文件名,所以执行下述命令,看看会发生啥~~!!
python3 bs2.py >bs.txt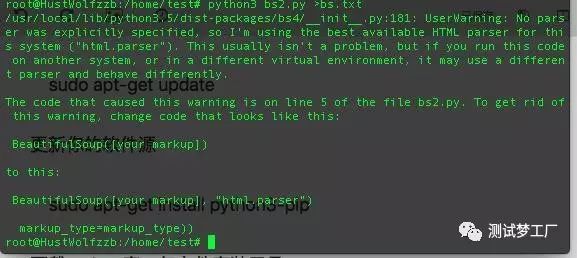
执行文件
OK,现在可以查看结果了 cat bs.txt 对了,上面那个>的意思是把结果写进后面的文件
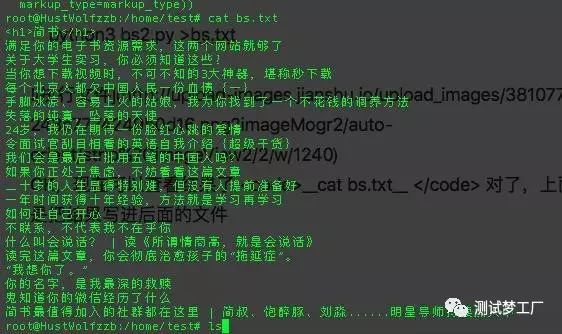
首页的显示
更改查找规则:
from urllib.request import urlopenfrom bs4 import BeautifulSoup
html = urlopen("http://www.jianshu.com")
bsObj = BeautifulSoup(html)
print(bsObj.h1)
nameList=bsObj.findAll("li",{"class":"have-img"})for name in nameList:
print(name.get_text())
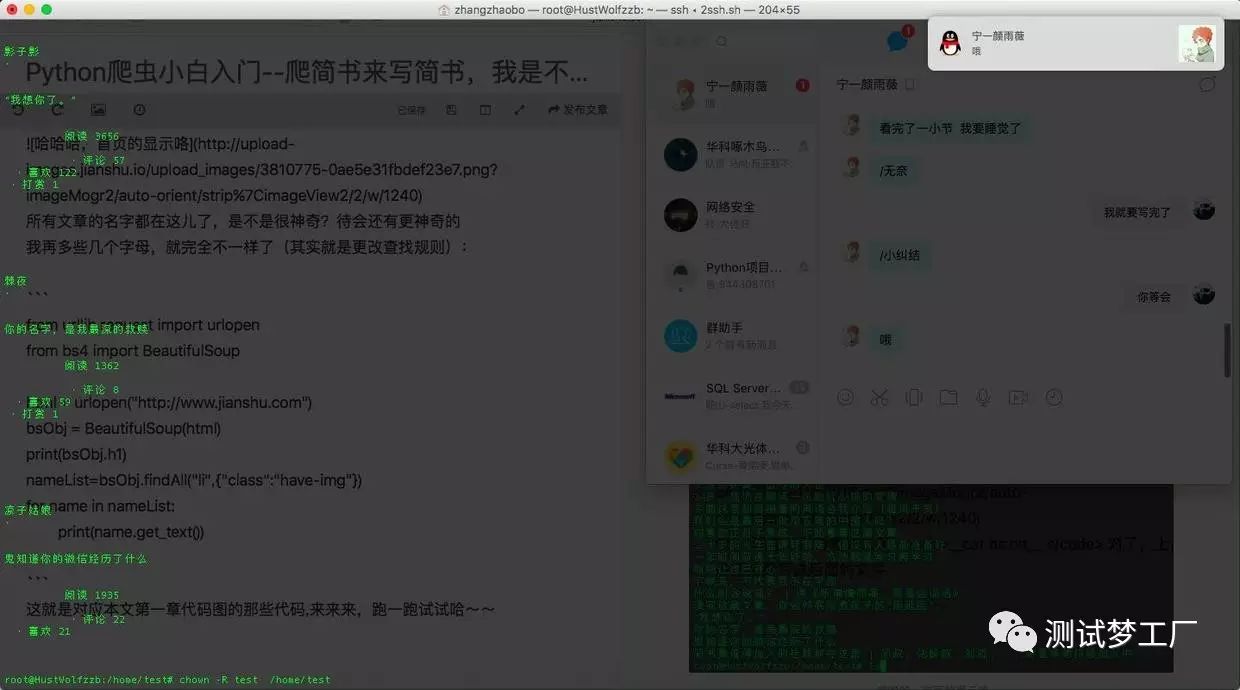
多了不少东西~~~
由于这样会对简书服务器造成负载,所以希望大家克制一下,不要过多的爬。温柔以待简书
?

长按二维码识别关注,您的支持是我们最大的动力。
公众号:测试梦工厂
QQ一群:300897805

以上是关于Python爬虫入门的主要内容,如果未能解决你的问题,请参考以下文章