python webdriver 测试框架-数据驱动excel驱动的方式
Posted 夏晓旭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python webdriver 测试框架-数据驱动excel驱动的方式相关的知识,希望对你有一定的参考价值。
简介:
数据驱动excel驱动方式,就是数据配置在excel里面,主程序调用的时候每次用从excel里取出的数据作为参数,进行操作,
需要掌握的地方是对excel的操作,要灵活的找到目标数据
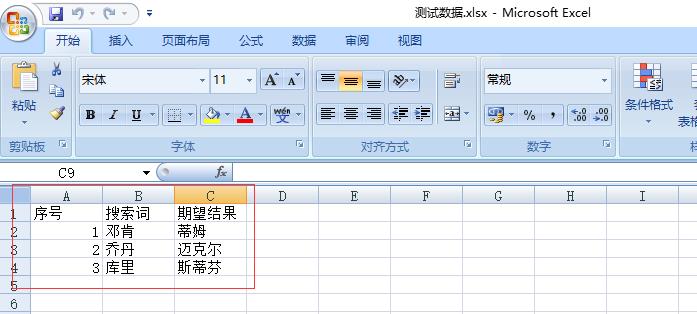
测试数据.xlsx:
路径-D:\\test\\0627
ExcelUtil.py:
#encoding=utf-8
from openpyxl import load_workbook
class ParseExcel(object):
def __init__(self, excelPath, sheetName):
# 将要读取的excel加载到内存
self.wb = load_workbook(excelPath)
# 通过工作表名称获取一个工作表对象
self.sheet = self.wb.get_sheet_by_name(sheetName)
# 获取工作表中存在数据的区域的最大行号
self.maxRowNum = self.sheet.max_row
def getDatasFromSheet(self):
# 用于存放从工作表中读取出来的数据
dataList = []
# 因为工作表中的第一行是标题行,所以需要去掉
for line in self.sheet.rows:
# 遍历工作表中数据区域的每一行,
# 并将每行中各个单元格的数据取出存于列表tmpList中,
# 然后再将存放一行数据的列表添加到最终数据列表dataList中
tmpList = []
tmpList.append(line[1].value)
tmpList.append(line[2].value)
dataList.append(tmpList)
# 将获取工作表中的所有数据的迭代对象返回
return dataList[1:]
if __name__ == \'__main__\':
excelPath = u\'E:\\\\数据驱动\\\\测试数据.xlsx\'
sheetName = u"搜索数据表"
pe = ParseExcel(excelPath, sheetName)
print pe.getDatasFromSheet()
for i in pe.getDatasFromSheet():
print i[0], i[1]
加print调试日志:
#encoding=utf-8
from openpyxl import load_workbook
class ParseExcel(object):
def __init__(self,excelPath,sheetName):
self.wb=load_workbook(excelPath)
self.sheet=self.wb.get_sheet_by_name(sheetName)
self.maxRowNum=self.sheet.max_row
def getDatasFromSheet(self):
dataList=[]
for line in self.sheet.rows:
tmpList=[]
tmpList.append(line[1].value)
print "line[1].value",line[1].value
tmpList.append(line[2].value)
print "line[2].value",line[2].value
dataList.append(tmpList)
print dataList[1:]
return dataList[1:]
if __name__==\'__main__\':
excelPath=u"d:\\\\test\\\\0627\\\\测试数据.xlsx"
sheetName=u"搜索数据表"
pe=ParseExcel(excelPath,sheetName)
print pe.getDatasFromSheet()
for i in pe.getDatasFromSheet():
print i[0],i[1]
单独运行结果:
D:\\test\\0627>python ExcelUtil.py
ExcelUtil.py:7: DeprecationWarning: Call to deprecated function get_sheet_by_name (Use wb[sheetname]).
self.sheet=self.wb.get_sheet_by_name(sheetName)
line[1].value 搜索词
line[2].value 期望结果
line[1].value 邓肯
line[2].value 蒂姆
line[1].value 乔丹
line[2].value 迈克尔
line[1].value 库里
line[2].value 斯蒂芬
[[u\'\\u9093\\u80af\', u\'\\u8482\\u59c6\'], [u\'\\u4e54\\u4e39\', u\'\\u8fc8\\u514b\\u5c14\'], [u\'\\u5e93\\u91cc\', u\'\\u65af\\u8482\\u82ac\']]
[[u\'\\u9093\\u80af\', u\'\\u8482\\u59c6\'], [u\'\\u4e54\\u4e39\', u\'\\u8fc8\\u514b\\u5c14\'], [u\'\\u5e93\\u91cc\', u\'\\u65af\\u8482\\u82ac\']]
line[1].value 搜索词
line[2].value 期望结果
line[1].value 邓肯
line[2].value 蒂姆
line[1].value 乔丹
line[2].value 迈克尔
line[1].value 库里
line[2].value 斯蒂芬
[[u\'\\u9093\\u80af\', u\'\\u8482\\u59c6\'], [u\'\\u4e54\\u4e39\', u\'\\u8fc8\\u514b\\u5c14\'], [u\'\\u5e93\\u91cc\', u\'\\u65af\\u8482\\u82ac\']]
邓肯 蒂姆
乔丹 迈克尔
库里 斯蒂芬
最后运行的脚本:
data_drivern_by_excel.py:
#encoding=utf-8
from selenium import webdriver
import unittest,time
import logging,traceback
import ddt
from ExcelUtil import ParseExcel
from selenium.common.exceptions import NoSuchElementException
#初始化日志对象
logging.basicConfig(
#日志级别
level=logging.INFO,
#日志格式
#时间、代码所在文件名、代码行号、日志级别名称、日志信息
format=\'%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s\',
#打印日志的时间
datefmt=\'%a,%Y-%m-%d %H:%M:S\',
#日志文件存放的目录(目录必须存在)及日志文件名
filename=\'d:\\\\test\\\\0627\\\\report.log\',
#打开日志文件的方式
filemode=\'w\'
)
excelPath=u"d:\\\\test\\\\0627\\\\测试数据.xlsx"
sheetName=u"搜索数据表"
#创建ParseExcel类的实例对象
excel=ParseExcel(excelPath,sheetName)
#数据驱动装饰器
@ddt.ddt
class TestDemo(unittest.TestCase):
def setUp(self):
self.driver=webdriver.Firefox(executable_path=\'c:\\\\geckodriver\')
@ddt.data(*excel.getDatasFromSheet())#对调用函数返回的含列表的列表进行解包,传过来的就是列表中的一个列表
def test_dataDrivenByFile(self,data):
print "tuple(data):",tuple(data)#把传过来的一个列表转换成元祖,包含两个元素,搜索值和期望值
testData,expectData=tuple(data)
print "testData:",testData#调试用
print "expectData:",expectData#调试用
url=\'http://www.baidu.com\'
#访问百度首页
self.driver.get(url)
#讲浏览器窗口最大化
self.driver.maximize_window()
#print testData,expectData
#设置隐式等待时间为10秒钟
self.driver.implicitly_wait(10)
try:
#获取当前的时间戳,用于后面计算查询耗时用
start=time.time()
#获取当前时间的字符串,表示测试开始时间
startTime=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
#找到搜索输入框,并输入测试数据
self.driver.find_element_by_id(\'kw\').send_keys(testData)
#找到搜索按钮,并点击
self.driver.find_element_by_id(\'su\').click()
time.sleep(3)
#断言期望结果是否出现在页面源代码中
self.assertTrue(expectData in self.driver.page_source)
print u"搜索-%s,期望-%s"%(testData,expectData)
except NoSuchElementException,e:
logging.error(u"查找的页面元素不存在,异常堆栈信息:"+str(traceback.format_exc()))
except AssertionError,e:
logging.info(u\'搜索-"%s",期望-"%s",-失败\'%(testData,expectData))
except Exception,e:
logging.error(u"未知错误,错误信息:"+str(traceback.format_exc()))
else:
logging.info(u\'搜索- "%s",期望-"%s"-通过\'%(testData,expectData))
def tearDown(self):
self.driver.quit()
if __name__==\'__main__\':
unittest.main()
结果:
d:\\test\\0627>python test.py
d:\\test\\0627\\ExcelUtil.py:11: DeprecationWarning: Call to deprecated function get_sheet_by_name (Use wb[sheetname]).
self.sheet=self.wb.get_sheet_by_name(sheetName)
tuple(data): (u\'\\u9093\\u80af\', u\'\\u8482\\u59c6\')
testData: 邓肯
expectData: 蒂姆
搜索-邓肯,期望-蒂姆
.tuple(data): (u\'\\u4e54\\u4e39\', u\'\\u8fc8\\u514b\\u5c14\')
testData: 乔丹
expectData: 迈克尔
搜索-乔丹,期望-迈克尔
.tuple(data): (u\'\\u5e93\\u91cc\', u\'\\u65af\\u8482\\u82ac\')
testData: 库里
expectData: 斯蒂芬
搜索-库里,期望-斯蒂芬
.
----------------------------------------------------------------------
Ran 3 tests in 45.614s
OK
report.log:
Fri,2018-06-29 11:18:S test.py[line:70] INFO 搜索- "邓肯",期望-"蒂姆"-通过
Fri,2018-06-29 11:18:S test.py[line:70] INFO 搜索- "乔丹",期望-"迈克尔"-通过
Fri,2018-06-29 11:18:S test.py[line:70] INFO 搜索- "库里",期望-"斯蒂芬"-通过
总结:
如果日志logging部分书写格式有问题、或者路径不存在、或者字符等有问题,日志就会输出到屏幕上,如果没有问题,才会打印到日志文件report.log中
数据驱动excel驱动方式和其他方式(txt等)原理大同小异,都是把数据从文件中取出来,用ddt模块进行解包,传进主程序,难点就是对不同的文件类型进行读取可能需要专门的程序包来处理,说白了,都是对基础的运用进行整合,真正项目中用到的肯定比这个要复杂。。。
以上是关于python webdriver 测试框架-数据驱动excel驱动的方式的主要内容,如果未能解决你的问题,请参考以下文章
python webdriver 测试框架--数据驱动之Excel驱动
python webdriver 一步一步搭建数据驱动测试框架的过程和总结
selenium + python自动化测试unittest框架学习webdriver的二次封装
selenium + python自动化测试unittest框架学习webdriver元素定位