python使用jieba实现中文文档分词和去停用词
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python使用jieba实现中文文档分词和去停用词相关的知识,希望对你有一定的参考价值。
分词工具的选择:
现在对于中文分词,分词工具有很多种,比如说:jieba分词、thulac、SnowNLP等。在这篇文档中,笔者使用的jieba分词,并且基于python3环境,选择jieba分词的理由是其比较简单易学,容易上手,并且分词效果还很不错。
分词前的准备:
- 待分词的中文文档
- 存放分词之后的结果文档
- 中文停用词文档(用于去停用词,在网上可以找到很多)
分词之后的结果呈现:

去停用词和分词前的中文文档
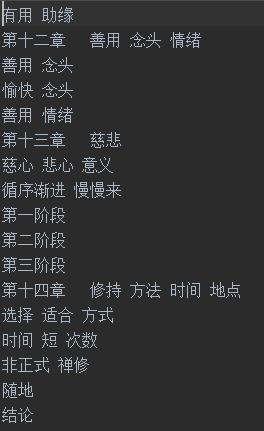
去停用词和分词之后的结果文档
分词和去停用词代码实现:
1 import jieba 2 3 # 创建停用词列表 4 def stopwordslist(): 5 stopwords = [line.strip() for line in open(\'chinsesstoptxt.txt\',encoding=\'UTF-8\').readlines()] 6 return stopwords 7 8 # 对句子进行中文分词 9 def seg_depart(sentence): 10 # 对文档中的每一行进行中文分词 11 print("正在分词") 12 sentence_depart = jieba.cut(sentence.strip()) 13 # 创建一个停用词列表 14 stopwords = stopwordslist() 15 # 输出结果为outstr 16 outstr = \'\' 17 # 去停用词 18 for word in sentence_depart: 19 if word not in stopwords: 20 if word != \'\\t\': 21 outstr += word 22 outstr += " " 23 return outstr 24 25 # 给出文档路径 26 filename = "Init.txt" 27 outfilename = "out.txt" 28 inputs = open(filename, \'r\', encoding=\'UTF-8\') 29 outputs = open(outfilename, \'w\', encoding=\'UTF-8\') 30 31 # 将输出结果写入ou.txt中 32 for line in inputs: 33 line_seg = seg_depart(line) 34 outputs.write(line_seg + \'\\n\') 35 print("-------------------正在分词和去停用词-----------") 36 outputs.close() 37 inputs.close() 38 print("删除停用词和分词成功!!!")
以上是关于python使用jieba实现中文文档分词和去停用词的主要内容,如果未能解决你的问题,请参考以下文章