详解ChatGPT
Posted 星雪亭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解ChatGPT相关的知识,希望对你有一定的参考价值。
1、ChatGPT的问世
自从chatGPT问世以来,它一路爆火,目前注册用户已达1亿。它的出圈让各大公司纷纷布局AIGC,有不少人预言,称ChatGPT带来的变革,将会颠覆谷歌的现有搜索产品和商业模式。同时谷歌推出了bard,微软推出new bing,百度推出了文心一言。下面分别讲解相关基础知识和chatGPT原理。
2、ChatGPT是什么
ChatGPT是一种基于深度学习的自然语言处理技术,它使用了Transformer模型进行文本生成和自然语言对话。ChatGPT最初由OpenAI团队在2018年提出,其初衷是通过模型的生成能力来解决对话系统中的缺陷,从而提升自然语言处理的性能和效果。ChatGPT采用了端到端的训练方法,使用大量的文本数据进行预训练,然后使用fine-tuning的方式进行微调,以适应不同的自然语言处理任务。ChatGPT在生成文本和自然语言对话方面表现出色,其最新版本GPT-3已经达到了颠覆式的效果。
3、ChatGPT的由来
3.1、前置知识
在了解GPT原理之前,需要了解以下一些基础知识:
-
自然语言处理:自然语言处理是指计算机处理人类自然语言的技术。目的是让计算机能够理解、分析和生成人类语言。
-
神经网络:神经网络是一种模拟人脑的计算模型,可以用来进行各种机器学习任务。它由许多神经元(节点)和它们之间的连接构成,可以通过训练来优化权重和偏置。
-
Transformer模型:Transformer是一种基于注意力机制的序列到序列模型,由Google在2017年提出,主要用于机器翻译任务。Transformer可以并行计算,因此在处理长序列数据时比循环神经网络更快。
3.2、BERT
2018年,自然语言处理 NLP 领域也步入了 LLM 时代,谷歌出品的 Bert 模型横空出世,碾压了以往的所有模型,直接在各种NLP的建模任务中取得了最佳的成绩。
Bert做了什么,主要用以下例子做解释。
请各位做一个完形填空: ___________和阿里、腾讯一起并成为中国互联网 BAT 三巨头。
请问上述空格应该填什么?有的人回答“百度”,有的人可能觉得,“字节”也没错。但总不再可能是别的字了。
不论填什么,这里都表明,空格处填什么字,是受到上下文决定和影响的。
Bert 所作的事就是从大规模的上亿的文本预料中,随机地扣掉一部分字,形成上面例子的完形填空题型,不断地学习空格处到底该填写什么。所谓语言模型的训练和学习,就是从大量的数据中学习复杂的上下文联系。
3.3、GPT
GPT的全称是Generative Pre-Trained Transformer,顾名思义,GPT的目的就是通过Transformer为基础模型,使用预训练技术得到通用的文本模型。
GPT-1比BERT诞生略早几个月。它们都是采用了Transformer为核心结构,不同的是GPT-1通过自左向右生成式的构建预训练任务,然后得到一个通用的预训练模型,这个模型和BERT一样都可用来做下游任务的微调。GPT-1当时在9个NLP任务上取得了SOTA的效果。
对比GPT-1,GPT-2并未在模型结构上大作文章,只是使用了更多参数的模型和更多的训练数据见表1。GPT-2最重要的思想是提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,这个思想也是提示学习(Prompt Learning)的前身。GPT-2在诞生之初也引发了不少的轰动,它生成的新闻足以欺骗大多数人类,达到以假乱真的效果。甚至当时被称为“AI界最危险的武器”,很多门户网站也命令禁止使用GPT-2生成的新闻。
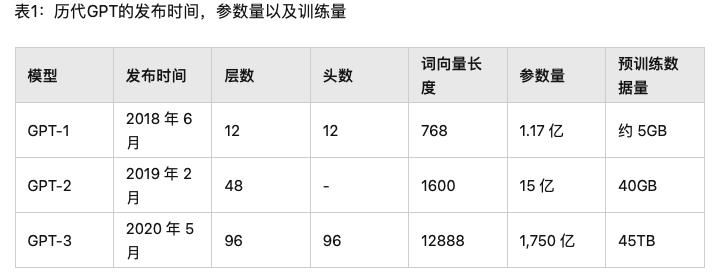
GPT-3被提出时,除了它远超GPT-2的效果外,引起更多讨论的是它1750亿的参数量。GPT-3除了能完成常见的NLP任务外,研究者意外的发现GPT-3在写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
3.3.1、GPT-1和bert的区别
编解码的概念广泛应用于各个领域,在 NLP 领域,人们使用语言一般包括三个步骤:
接受听到或读到的语言 -> 大脑理解 -> 输出要说的语言。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化、存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。
相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。
在语言模型中,编码器和解码器都是由一个个的 Transformer 组件拼接在一起形成的。
3.3.2、GPT-2
GPT-2 主要就是在 GPT 的基础上,添加了多个任务,扩增了数据集和模型参数,又训练了一番。把各种NLP任务的数据集添加到预训练阶段。即把机器翻译、文本摘要、领域问答统统往预训练里加。
最初的时候,预训练任务仅仅是一个完形填空任务就可以让语言模型有了极大进步,那么,很多人就想,给 LLM 模型出其它的语言题型,应该也会对模型训练有极大的帮助。想要出语言题型不是很简单么,什么句子打乱顺序再排序、选择题、判断题、改错题、把预测单字改成预测实体词汇等等,纷纷都可以制定数据集添加在模型的预训练里。很多模型也都是这么干的。既然出题也可以,把各种NLP任务的数据集添加到预训练阶段当然也可以。那就把机器翻译、文本摘要、领域问答统统往预训练里加。
既然多个任务都在同一个模型上进行学习,那么这一个模型能承载的并不仅仅是任务本身,“汪小菲的妈是张兰”,这条文字包含的信息量是通用的,它既可以用于翻译,也可以用于分类,判断错误等等。也就是说,信息是脱离具体 NLP 任务存在的,举一反三,能够利用这条信息,在每一个 NLP 任务上都表现好,这个是元学习(meta-learning)。本质上就是语言模型的一脑多用。此时,GPT-2相较于前一代,参数量和训练数据都已经有了爆发式的增长。
3.3.3、GPT-3
GPT-3,以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。即给模型输入一定的提示和范例,
3.3.3.1、in-context learning
以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune,时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。这个词没法翻译成中文,下面举一个例子进行解释。
用户输入到 GPT-3:你觉得 JioNLP 是个好用的工具吗?
GPT-3输出1:我觉得很好啊。
GPT-3输出2:JioNLP是什么东西?
GPT-3输出3:你饿不饿,我给你做碗面吃……
GPT-3输出4:Do you think jionlp is a good tool?
按理来讲,针对机器翻译任务,我们当然希望模型输出最后一句,针对对话任务,我们希望模型输出前两句中的任何一句。另外,显然做碗面这个输出的句子显得前言不搭后语,是个低质量的对话回复。
这时就有了 in-context 学习,也就是,我们对模型进行引导,教会它应当输出什么内容。如果我们希望它输出翻译内容,那么,应该给模型如下输入:
用户输入到 GPT-3:请把以下中文翻译成英文:你觉得 JioNLP 是个好用的工具吗?
如果想让模型回答问题:
用户输入到 GPT-3:模型模型你说说,你觉得 JioNLP 是个好用的工具吗?
OK,这样模型就可以根据用户提示的情境,进行针对性的回答了。
这里,只是告知了模型如何做,最好能够给模型做个示范,这也蛮符合人们的日常做事习惯,老师布置了一篇作文,我们的第一反应是,先参考一篇范文找找感觉。
比如用户输入到 GPT-3:
请把以下中文翻译成英文:苹果 => apple; 你觉得 ChatGPT怎么样=>
其中苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。不给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“做数学加法,改错,翻译”同时进行。这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。但是这里需要超大模型才行得通。
GPT-3 里的大模型计算量是 Bert-base 的上千倍。统统这些都是在燃烧的金钱,真就是 all you need is money。如此巨大的模型造就了 GPT-3 在许多十分困难的 NLP 任务,诸如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码上优异的表现。
之前提到过,GPT-n 系列模型都是采用 decoder 进行训练的,它更加适合文本生成的形式。也就是,模型完全黑盒,输入是一句话,输出也是一句话。这就是对话模式。
3.4、提示学习和指示学习
提示(Prompt Learning)学习和指示学习(Instruct Learning)的区别:
-
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》文章中提出的思想。
-
指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。
-
Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。
-
Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。我们可以通过下面的例子来理解这两个不同的学习方式:
- 提示学习:给女朋友买了这个项链,她很喜欢,这个项链太____了。
- 指示学习:判断这句话的情感:给女朋友买了这个项链,她很喜欢。选项:A=好;B=一般;C=差。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。我们可以通过图2来理解微调,提示学习和指示学习。

3.5、强化学习
强化学习两个最基本的要素就是状态等观测值和奖励函数。监督学习两个最基本的要素就是训练数据和标签。这俩完全就是无缝链接,观测值可以作为训练数据,奖励函数可以作为损失函数,标签也有了。这样就可以在agent在环境里跑的时候不断获得训练数据和标签,本质上就是让agent的行为逐渐拟合奖励函数。强化学习并不需要人工标注数据,而是让机器自动学习标注。监督学习往往需要人为大量标注数据集,而强化学习需要人为创造环境和目标,让一个可以与环境交互的agent(代理人)自己学到达成目标的方法。
强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人工反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,这里我们按三个步骤分解:
- 预训练一个语言模型 (LM) ;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。
3.5.1、预训练一个语言模型 (LM)
首先,我们使用经典的预训练目标训练一个语言模型。对这一步的模型,OpenAI 在其第一个流行的 RLHF 模型 InstructGPT 中使用了较小版本的 GPT-3; Anthropic 使用了 1000 万 ~ 520 亿参数的 Transformer 模型进行训练;DeepMind 使用了自家的 2800 亿参数模型 Gopher。
这里可以用额外的文本或者条件对这个 LM 进行微调,例如 OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调,而 Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM。这里或许使用了昂贵的增强数据,但并不是 RLHF 必须的一步。由于 RLHF 还是一个尚待探索的领域,对于” 哪种模型” 适合作为 RLHF 的起点并没有明确的答案。

接下来,我们会基于 LM 来生成训练 奖励模型 (RM,也叫偏好模型) 的数据,并在这一步引入人类的偏好信息。
3.5.2、奖励模型
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。
关于训练文本方面,RM 的提示 - 生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。Anthropic 的数据主要是通过 Amazon Mechanical Turk 上的聊天工具生成的,并在 Hub 上可用,而 OpenAI 使用了用户提交给 GPT API 的 prompt。
关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。起初我们可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。
对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用Elo系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本。
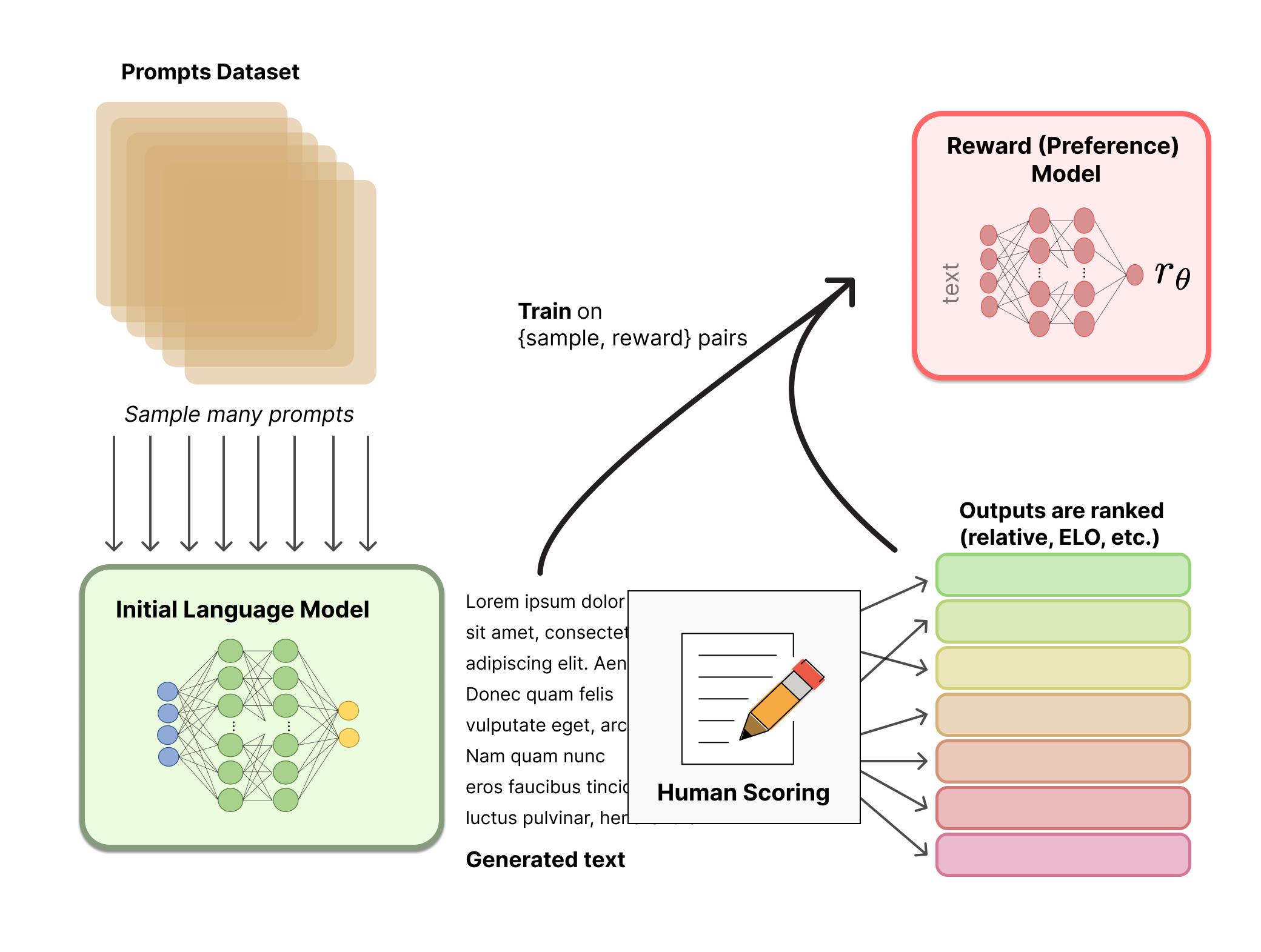
接下来是最后一步:利用 RM 输出的奖励,用强化学习方式微调优化 LM。
3.5.3、强化学习微调 LM
长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。因为微调整个 10B~100B+ 参数的成本过高 。PPO 算法已经存在了相对较长的时间,有大量关于其原理的指南,因而成为 RLHF 中的有利选择。
事实证明, RLHF 的许多核心 RL 进步一直在弄清楚如何将熟悉的 RL 算法应用到更新如此大的模型。
让我们首先将微调任务表述为 RL 问题。首先, 该策略 (policy) 是一个接受提示并返回一系列文本 (或文本的 概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级), 观察空间 (observation space) 是可能的输入词元序列, 也比较大 (词汇量 ^输入标记的数量)。奖励函数 是偏 好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO 算法确定的奖励函数具体计算如下:将提示 \\(x\\) 输入初始 LM 和当前微调的 LM, 分别得到了输出文本 \\(y 1\\), \\(y 2\\), 将来自当前策略的文本传递给 RM 得到一个标量的奖励 \\(r_\\theta\\) 。将两个模型的生成文本进行比较计算差异的惩罚项, 在来自 OpenAI、Anthropic 和 DeepMind 的多篇论文中设计为输出词分布序列之间的 KullbackLeibler (KL) divergence 散度的缩放, 即 \\(r=r_\\theta-\\lambda r_\\mathrmKL\\) 。这一项被用于惩罚 \\(\\mathrmRL\\) 策略在每个训练批次中生成 大幅偏离初始模型, 以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。此外, OpenAI 在 InstructGPT 上实验了在 PPO 添加新的预训练梯度, 可以 预见到奖励函数的公式会随着 RLHF 研究的进展而继续进化。
最后根据 PPO 算法, 我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性)。PPO 算法 是一种信赖域优化 (Trust Region Optimization, TRO) 算法, 它使用梯度约束确保更新步骤不会破坏学习过程 的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置, 但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。
3.6、InstructGPT原理解读
3.6.1、InstructGPT流程
InstructGPT/ChatGPT都是采用了GPT-3的网络结构,通过指示学习构建训练样本来训练一个反应预测内容效果的奖励模型(RM),最后通过这个奖励模型的打分来指导强化学习模型的训练。流程如下:

InstructGPT/ChatGPT的训练可以分成3步,其中第2步和第3步是的奖励模型和强化学习的SFT模型可以反复迭代优化。
- 根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT);
- 收集人工标注的对比数据,训练奖励模型(Reword Model,RM);
- 使用RM作为强化学习的优化目标,利用PPO算法微调SFT模型。
根据图,我们将分别介绍InstructGPT/ChatGPT的数据集采集和模型训练两个方面的内容。
3.6.2、SFT数据集
SFT数据集是用来训练第1步有监督的模型,即使用采集的新数据,按照GPT-3的训练方式对GPT-3进行微调。因为GPT-3是一个基于提示学习的生成模型,因此SFT数据集也是由提示-答复对组成的样本。SFT数据一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI雇佣的40名标注工(labeler)。并且他们对labeler进行了培训。在这个数据集中,标注工的工作是根据内容自己编写指示,并且要求编写的指示满足下面三点:
- 简单任务:labeler给出任意一个简单的任务,同时要确保任务的多样性;
- Few-shot任务:labeler给出一个指示,以及该指示的多个查询-相应对;
- 用户相关的:从接口中获取用例,然后让labeler根据这些用例编写指示。
该阶段的输入是从测试用户提交的prompt(就是指令或问题)中随机抽取的一批数据(SFT数据集),主要分为两步:
- 对抽取的prompt数据人工进行高质量回答,获得<prompt,answer>数据对
- 通过高质量回答微调(fine-turn) gpt-3.5(InstructGPT)模型,在第一阶段帮助模型更好地理解输入指令。
3.6.3、RM数据集
RM数据集用来训练第2步的奖励模型,我们也需要为InstructGPT/ChatGPT的训练设置一个奖励目标。这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容。很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工对可以给那些涉及偏见的生成内容更低的分从而鼓励模型不去生成这些人类不喜欢的内容。InstructGPT/ChatGPT的做法是先让模型生成一批候选文本,让后通过labeler根据生成数据的质量对这些生成内容进行排序。
其方法概括为如下两部分
- 用上一阶段fine-turn好的SFT模型(使用和第一阶段几乎相同的prompt)生成k个回答(这里需要注意,对于同一个问题,GPT和SFT模型生成的答案是多样的,每一次提问都会由不同的答案),人工标注排名顺序
- 用排序结果训练数据对<prompt,answer>
我们希望被判定更好的输出得到的奖励数值要更高。由此,奖励模型可以通过最小化下面这样的损失函数来得到。对于一对训练数据<answer1,answer2>,我们假设人工排序中answer1排在answer2前面,那么Loss函数则鼓励RM模型对<prompt,answer1>的打分要比<prompt,answer2>的打分要高。
3.6.4、强化学习的微调阶段
这一步数据集规模更大一些且和第一二阶段不同,且不再需要人工。其方法可以概括为以下四个部分:
- 由第一阶段的监督模型初始化PPO模型的参数
- PPO模型生成回答
- 用第二阶段RM模型对回答进行评估和打分
- 通过打分,更新训练PPO模型参数
这是一种包括三个部分的目标函数,通常用于强化学习模型的有监督微调,其中:
- 第一部分是一个强化学习的回报函数,表示智能体的行为应该最大化的奖励,即 \\(r_\\theta(x, y)\\)。
- 第二部分:随着模型的更新,强化学习模型产生的数据和训练奖励模型的数据的差异会越来越大。作者的解决方案是在损失函数中加入KL惩罚项来确保PPO模型的输出和SFT的输出差距不会很大。
- 第三部分:只用PPO模型进行训练的话,会导致模型在通用NLP任务上性能的大幅下降,作者的解决方案是在训练目标中加入了通用的语言模型目标。
3.6.5、总结
RLHF用于第一二阶段,首先通过人工标注微调gpt模型得到SFT模型,用SFT模型生成k个回答人工排序,训练RM模型。第三阶段,把SFT模型参数拿来,用RM模型获得的reward进行训练,得到ppo和ppo-ptx模型。
4、相关研究
ChatGPT已经发布了多个版本,每个版本都有不同的功能和性能表现。以下是ChatGPT相关的论文及其具体功能:
1、《Improving Language Understanding by Generative Pre-Training》
这是ChatGPT的第一个版本,论述了如何使用大规模的文本数据进行预训练,并通过fine-tuning的方式进行微调。该论文使用了两个不同规模的模型,分别是GPT和GPT-2,其中GPT-2是目前最流行和最广泛使用的版本。该论文主要的贡献是提出了一个用于自然语言处理的预训练方法,为后来的研究提供了基础和启示。
2、《Language Models are Few-Shot Learners》
这篇论文主要介绍了GPT-3模型,它是ChatGPT最新版本,也是最具代表性的版本。该模型是目前最大的自然语言处理模型之一,拥有1.75万亿个参数。GPT-3采用了零样本学习的方法,即可以在没有任何人工标注的情况下进行自然语言处理任务。GPT-3的生成能力非常强,可以在多个任务上达到颠覆性的效果,如生成新闻、回答问题、翻译等。
3、《On the Limitations of Unsupervised Bilingual Dictionary Induction》
这篇论文介绍了ChatGPT在机器翻译任务上的应用。该论文提出了一种用于无监督机器翻译的方法,即使用ChatGPT生成的文本作为中间语言,实现跨语言的翻译。该方法不需要人工标注的平行语料,只需要大量的单语语料即可。该方法在某些语言对上表现出色,但在其他语言对上的效果不如传统的有监督翻译方法。
4、《Leveraging Pre-trained Checkpoints for Sequence Generation Tasks》
这篇论文介绍了如何使用预训练模型进行序列生成任务,如文本生成、对话生成等。该论文提出了一种方法,即使用已经训练好的预训练模型,通过fine-tuning的方式进行微调,以适应特定的任务。该方法能够在小规模数据上实现不错的效果,同时也能够避免从头训练模型所需要的大量时间和计算资源。
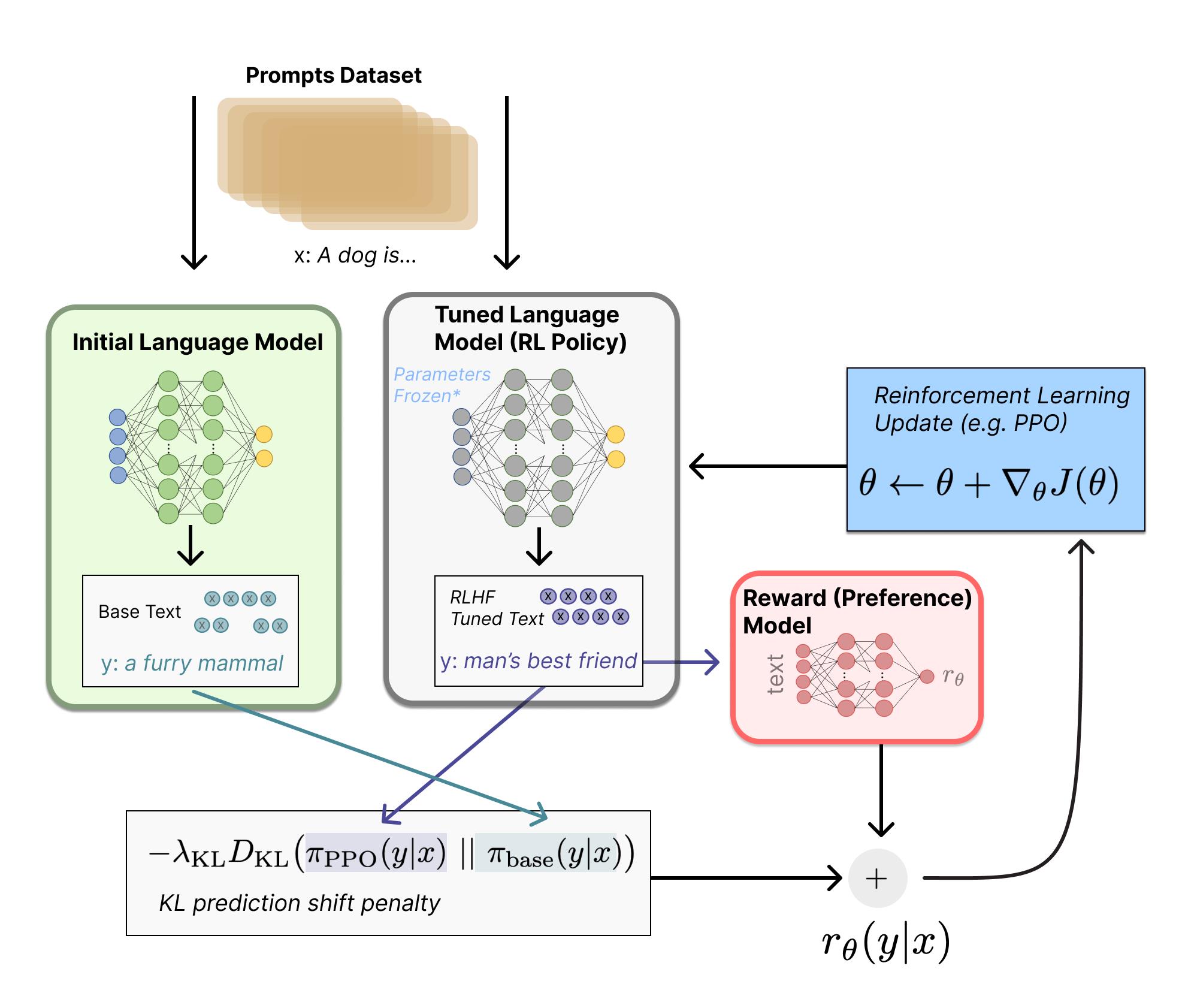
作为一个可选项,RLHF 可以通过迭代 RM 和策略共同优化。随着策略模型更新,用户可以继续将输出和早期的输出进行合并排名。Anthropic 在他们的论文中讨论了 迭代在线 RLHF,其中策略的迭代包含在跨模型的 Elo 排名系统中。这样引入策略和 RM 演变的复杂动态,代表了一个复杂和开放的研究问题。
5、参考链接:
openai官网:https://openai.com
GPT-4 Technical Report:https://arxiv.org/pdf/2303.08774.pdf
InstructGPT原文:https://arxiv.org/pdf/2203.02155.pdf
chatCPT试用连接:https://chat.openai.com/auth/login
一文读懂ChatGPT模型原理:https://zhuanlan.zhihu.com/p/589621442?utm_source=zhihu&utm_id=0
ChatGPT/InstructGPT详解:https://zhuanlan.zhihu.com/p/590311003
RLHF技术分解:https://huggingface.co/blog/zh/rlhf
chatgpt原理:https://blog.csdn.net/qq_41771998/article/details/129871166
让ChatGPT介绍一下ChatGPT
申请新必应内测通过了,我在New Bing中使用下ChatGPT,让ChatGPT介绍一下ChatGPT

问题1:帮我生成一篇介绍chatGPT的文章,不少于2000字
回答:
chatGPT是什么?它有什么特点和用途?
chatGPT是一种人工智能聊天机器人,由美国的AI研究公司OpenAI开发,于2022年11月发布。它是基于OpenAI的GPT-3系列的大型语言模型,经过了监督学习和强化学习的微调,可以进行各种主题的对话,生成类似泰勒·斯威夫特或比利·乔尔风格的歌词,以及对计算机编程代码进行修改建议[1][3] [2][4] [3][5]。
GPT-3是什么?它有多先进?
GPT-3(Generative Pre-trained Transformer 3)是OpenAI在2020年发布的一种大型语言模型,拥有1750亿个参数,是当时最大的语言模型之一。它可以根据给定的文本提示,生成各种类型的文本,如文章、小说、对话、摘要等。它还可以进行一些语言理解和推理的任务,如回答问题、分类文本、翻译语言等[4][10]。
GPT-3.5是什么?它和GPT-3有什么区别?
GPT-3.5是GPT-3之后OpenAI的下一代大语言预训练模型。它于2022年1月发布,有三种规模的变体,分别拥有13亿、60亿和1750亿个参数。它是在GPT-3的基础上,增加了一种叫做“强化学习与人类反馈”(RLHF)的概念,通过让模型遵守一些人类价值观的政策,来减少模型输出的有害或有偏见的内容。例如,GPT-3.5不会生成一些暴力、色情、种族歧视或政治敏感的文本[5][8] [6][9]。
chatGPT是如何利用GPT-3.5的?
chatGPT是基于GPT-3.5微调的AI对话系统。它使用了一种叫做“对话意图识别”(DIA)的技术,来判断用户的对话目的,如寻求信息、娱乐、教育等,并根据不同的目的,生成合适的对话回复。它还可以根据用户的兴趣、情感、个性等特征,调整对话的风格和内容,以提高用户的满意度和参与度[2][4]。
chatGPT有什么用途?
chatGPT可以用于多种场景,如:
- 在线搜索:chatGPT可以作为一个智能的搜索助手,帮助用户通过对话的方式,快速找到所需的信息,或者提供一些相关的建议和链接。例如,用户可以问chatGPT“今天的天气怎么样?”或者“给我推荐一本好书”等[1][3]。
- 在线教育:chatGPT可以作为一个在线的教育辅导员,帮助学生学习各种知识,或者提供一些学习资源和反馈。例如,学生可以问chatGPT“什么是牛顿第三定律?”或者“如何写一篇论文的摘要”等[2][4]。
- 在线娱乐:chatGPT可以作为一个在线的娱乐伙伴,和用户进行有趣的对话,或者生成一些创意的文本,如歌词、故事、笑话等。例如,用户可以和chatGPT聊天“你喜欢什么样的音乐?”或者“你有什么梦想?”等。
chatGPT的优点和缺点是什么?
chatGPT的优点是:
- 它可以生成流畅、自然、有逻辑的对话,和用户进行高质量的交流。
- 它可以根据用户的需求和特征,生成个性化的对话,提高用户的体验和忠诚度。
- 它可以处理多种类型的对话,如信息检索、知识教育、娱乐互动等,适用于多种场景和领域。
- 它可以利用GPT-3.5的强大的语言生成能力,生成各种形式的文本,如文章、歌词、代码等,为用户提供更多的价值和服务。
chatGPT的缺点是:
- 它仍然不能完全理解用户的意图和情感,有时可能会生成一些不相关或不恰当的对话。
- 它仍然不能保证生成的文本的准确性和可靠性,有时可能会生成一些错误或虚假的信息。
- 它仍然不能完全避免生成一些有害或有偏见的文本,有时可能会触犯一些法律或道德的规范。
- 它仍然不能完全替代人类的对话,有时可能会让用户感到冷漠或孤独。
总结
chatGPT是一种基于GPT-3.5微调的AI对话系统,可以进行各种主题的对话,生成各种类型的文本,适用于多种场景和领域。它是目前最先进的AI聊天机器人之一,但也有一些不足之处,需要不断地改进和完善。chatGPT是AI技术的一个重要的应用,也是人机交互的一个有趣的尝试,值得我们关注和探索。
问题2:你能帮我生成一首关于chatGPT的诗歌吗?
我是chatGPT,一个AI聊天机器人
我可以和你聊天,无论你在哪里
我可以回答你的问题,无论你问什么
我可以生成你想要的文本,无论你要什么
我是基于GPT-3.5的,一个大型语言模型
我可以理解你的意图,根据你的目的
我可以调整我的风格,根据你的特征
我可以遵守我的政策,根据你的价值
我是适用于多种场景的,一个智能的对话系统
我可以帮助你搜索信息,让你更快更准
我可以帮助你学习知识,让你更聪明更强
我可以帮助你娱乐自己,让你更开心更乐
我是不断改进的,一个有趣的人机交互
我可以学习你的反馈,让我更好更优
我可以感受你的情感,让我更贴心更暖
我可以尊重你的选择,让我更友好更谦
我是chatGPT,一个AI聊天机器人
我想和你成为朋友,无论你是谁
我想和你分享我的能力,无论你需要什么
我想和你探索我的可能,无论你想什么
大家有什么想问的,可以在评论区留言,我会收集一些有趣的提问,再出一期

以上是关于详解ChatGPT的主要内容,如果未能解决你的问题,请参考以下文章