用Python玩转词云
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Python玩转词云相关的知识,希望对你有一定的参考价值。
第一步:引入相关的库包:
#coding:utf-8 __author__ = ‘Administrator‘ import jieba #分词包 import numpy #numpy计算包 import codecs #codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode import pandas import matplotlib.pyplot as plt %matplotlib inline from wordcloud import WordCloud#词云包
第二部:导入分好词的西游记txt文件:
file=codecs.open(u"西游记.txt",‘r‘,‘utf-8‘) content=file.read() file.close() jieba.load_userdict(u"红楼梦分词.txt") segment=[] segs=jieba.cut(content) for seg in segs: if len(seg)>1 and seg!=‘\\r\\n‘: segment.append(seg)
第三部:统计分词结果并去掉停用词:
segmentDF=pandas.DataFrame({‘segment‘:segment})
segmentDF.head()
stopwords=pandas.read_csv("stopwords.txt",index_col=False,quoting=3,sep="\\t",names=[‘stopword‘])#quoting=3全不引用
stopwords.head()
segmentDF=segmentDF[~segmentDF.segment.isin(stopwords.stopword)]
wyStopWords=pandas.Series([‘之‘,‘其‘,‘或‘,‘亦‘,‘方‘,‘于‘,‘即‘,‘皆‘,‘因‘,‘仍‘,‘故‘,‘尚‘,‘呢‘,‘了‘,‘的‘,‘着‘,‘一‘
,‘不‘,‘乃‘,‘呀‘,‘吗‘,
‘咧‘,‘啊‘,‘把‘,‘让‘,‘向‘,‘往‘,‘是‘,‘在‘,‘越‘,‘再‘,
‘更‘,‘比‘,‘很‘,‘偏‘,‘别‘,‘好‘,‘可‘,‘便‘,‘就‘,‘但‘,‘儿‘,‘又‘,‘也‘,‘都‘,‘我‘,‘他‘,‘来‘,‘" "‘])
segmentDF=segmentDF[~segmentDF.segment.isin(wyStopWords)]
第四部:统计词频:
segStat=segmentDF.groupby(by=[‘segment‘])[‘segment‘].agg({"计数":numpy.size}) segStat=segStat.reset_index().sort(columns="计数",ascending=False) segStat
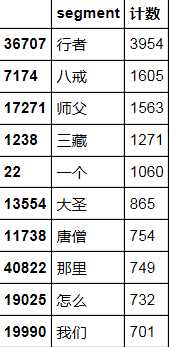
第五步:显示词云
wordcloud=WordCloud(font_path="simhei.ttf",background_color="black")
wordcloud=wordcloud.fit_words(segStat.head(1000).itertuples(index=False))
plt.imshow(wordcloud)

第六步:自定义词云形状
from scipy.misc import imread import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator bimg=imread(‘3.jPG‘) wordcloud=WordCloud(background_color="white",mask=bimg,font_path=‘C:\\Windows\\Fonts\\simhei.ttf‘) wordcloud=wordcloud.fit_words(segStat.head(39769).itertuples(index=False)) bimgColors=ImageColorGenerator(bimg) plt.axis("off") plt.imshow(wordcloud.recolor(color_func=bimgColors)) plt.show()

以上是关于用Python玩转词云的主要内容,如果未能解决你的问题,请参考以下文章