python3 request 库
Posted 听海8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3 request 库相关的知识,希望对你有一定的参考价值。
request库
虽然Python的标准库中 urllib.request 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
requests 的底层实现其实就是 urllib3。
Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6—3.6,而且能在PyPy下完美运行。
1.1 requests库特性。
Requests库是Python中的一个HTTP请求第三方库,用来简化网络请求,
它有如下特征,能够完全满足现在的Web开发。
1.Keep-Alive & 连接池。
2.国际化域名和 URL。
3.带持久 Cookie 的会话。
4.浏览器式的 SSL 认证。
5.自动内容解码。
6.基本/摘要式的身份认证。
7.优雅的 key/value Cookie。
8.自动解压。
9.Unicode 响应体。
10.HTTP(S) 代理支持。
11.文件分块上传。
12.流下载。
13.连接超时。
14.分块请求。
15.支持 .netrc。
1.2 requests库安装。
requests库的安装可以通过pip install requests命令安装或者利用easy_install都可以完成安装,一般情况都是通过pip install requests命令安装。
1.3 用requests库发送请求。
使用 Requests发送网络请求非常简单。
第一步:需要导入 Requests 模块:
import requests
第二步:创建一个Response对象,我们可以各种通过HTTP请求类型从这个对象中获取所有我们想要的信息。
例如:获取 Github 的公共时间线。
Response = requests.get(\'https://api.github.com/events\')
Response = requests.post(\'http://httpbin.org/post\', data = {\'key\':\'value\'})
Response = requests.put(\'http://httpbin.org/put\', data = {\'key\':\'value\'})
Response = requests.delete(\'http://httpbin.org/delete\')
Response = requests.head(\'http://httpbin.org/get\')
Response = requests.options(\'http://httpbin.org/get\')
Get 、Post、PUT、DELETE、HEAD 以及 OPTIONS 都是requests 库的HTTP请求类型,常用的一般是Get 、Post两种,下面的教程也是以Get 、Post两种为主介绍相关的使用。
1.4 带参数的Get请求。
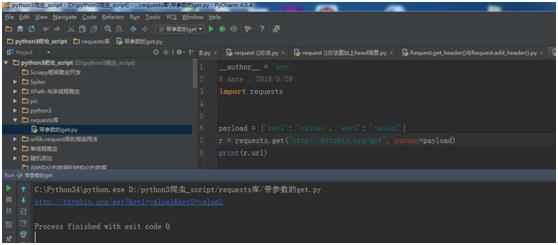
通常一个get完整的URL是手工构建的,数据会以键/值对的形式置于URL中,跟在一个问号的后面。例如, httpbin.org/get?key=val。 Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。举例来说,如果你想传递 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代码:
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
r = requests.get("http://httpbin.org/get", params=payload)
print(r.url)
运行结果:
http://httpbin.org/get?key1=value1&key2=value2
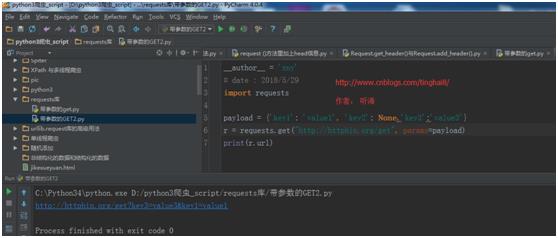
注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
例子:
import requests
payload = {\'key1\': \'value1\', \'key2\': None,\'key3\':\'value3\'}
r = requests.get("http://httpbin.org/get", params=payload)
print(r.url)
运行结果:
http://httpbin.org/get?key3=value3&key1=value1
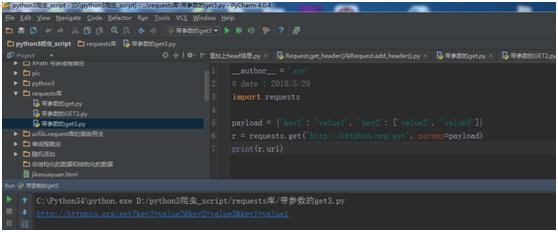
你还可以将一个列表作为值传入。
例子:
import requests
payload = {\'key1\': \'value1\', \'key2\': [\'value2\', \'value3\']}
r = requests.get("http://httpbin.org/get", params=payload)
print(r.url)
运行结果:
http://httpbin.org/get?key2=value2&key2=value3&key1=value1
1.5 Get请求带headers 和 params查询参数。
Get请求如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
例子:
import requests
kw = {\'wd\':\'电影\'}
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# params 接收一个字典或者字符串的查询参数,字典类型自动转换为url编码,不需要urlencode()
response = requests.get("http://www.baidu.com/s?", params = kw, headers = headers)
# 查看响应内容,response.text 返回的是Unicode格式的数据。
print(response.text)
# 查看响应内容,response.content返回的字节流数据。
print(response.content)
# 查看完整url地址。
print(response.url)
# 查看响应头部字符编码。
print(response.encoding)
# 查看响应码。
print(response.status_code)
运行结果:
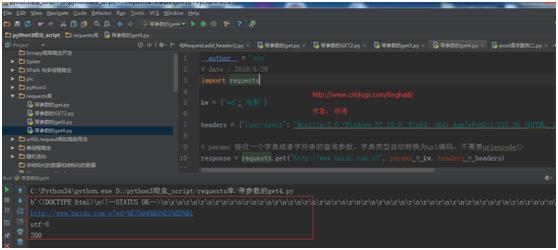
说明:
【response.text】:获取响应内容。
【response.content】:也是获取响应内容,但是返回的是字节流数据。
【response.url】:查看完整的请求URL。
【response.encoding】:查看响应头部字符编码。
【response.status_code】:查看响应状态码。
使用response.text 时,Requests 会基于 HTTP 响应的文本编码自动解码响应内容,大多数 Unicode 字符集都能被无缝地解码。
使用response.content 时,返回的是服务器响应数据的原始二进制字节流,可以用来保存图片等二进制文件。
1.6 Post请求。
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
例子:
import requests
payload = {\'key1\': \'value1\', \'key2\': \'value2\'}
ret = requests.post("http://httpbin.org/post", data=payload)
print(ret.text)
运行结果:
{"args":{},"data":"","files":{},"form":{"key1":"value1","key2":"value2"},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Content-Length":"23","Content-Type":"application/x-www-form-urlencoded","Host":"httpbin.org","User-Agent":"python-requests/2.18.4"},"json":null,"origin":"119.123.205.115","url":"http://httpbin.org/post"}
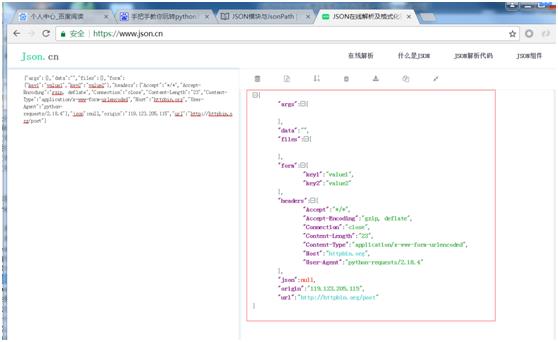
1.7 响应内容。
requests模块的返回对象是一个Response对象,可以从这个对象中获取需要的信息。下面 r 代表Response对象。
【r.text】:文本响应内容。
【r.context】:二进制响应内容。
【r.json()】:JSON响应内容 。
【r.raw】:原始相应内容。
(1)文本响应内容。
例子:
import requests
r = requests.get(\'https://api.github.com/events\')
print(r.text)
运行结果:
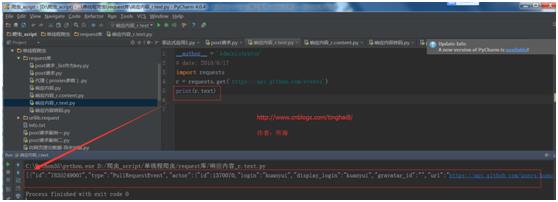
对于非文本请求,你也能以字节的方式访问请求响应体。
(2)二进制响应内容。
对于非文本请求,你也能以字节的方式访问请求响应体。
例子1:
import requests
r = requests.get(\'https://api.github.com/events\')
print(r.content)
运行结果:
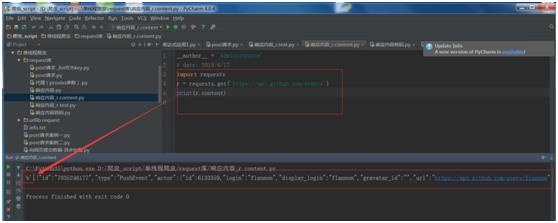
Requests 会自动为你解码 gzip 和 deflate 传输编码的响应数据。
例子2,以请求返回的二进制数据创建一张图片。
from PIL import Image
from io import BytesIO
i = Image.open(BytesIO(r.content))
(3)JSON响应内容。
Requests 中也有一个内置的 JSON 解码器,助你处理 JSON 数据。
例子:
import requests
r = requests.get(\'https://github.com/timeline.json\')
print(r.json())
运行结果:
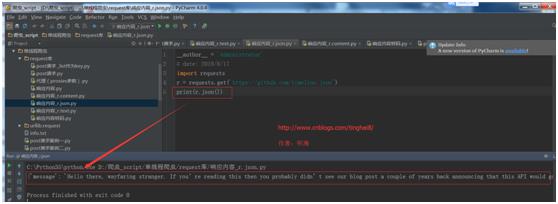
如果 JSON 解码失败, r.json 就会抛出一个异常。例如,相应内容是 401 (Unauthorized),尝试访问 r.json 将会抛出 ValueError: No JSON object could be decoded 异常。
(4)Raw响应内容。
在罕见的情况下,你可能想获取来自服务器的原始套接字响应,那么你可以访问 r.raw。 如果你确实想这么干,那请你确保在初始请求中设置了 stream=True。具体你可以这么做。
例子:
import requests
r = requests.get(\'https://github.com/timeline.json\', stream=True)
print(r.raw)
运行结果:
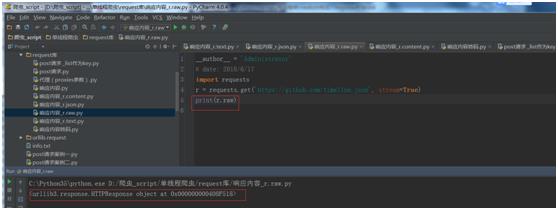
但一般情况下,你应该以下面的模式将文本流保存到文件。
with open(filename, \'wb\') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)
使用 Response.iter_content 将会处理大量你直接使用 Response.raw 不得不处理的。 当流下载时,上面是优先推荐的获取内容方式。
1.8 响应码转码。
Requests会自动将从Server返回的内容解码。许多Unicode字符也会被解码。
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 r.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用r.encoding 属性来改变它:
如果你改变了编码,每当你访问 r.text ,Request 都将会使用 r.encoding 的新值。你可能希望在使用特殊逻辑计算出文本的编码的情况下来修改编码。比如 HTTP 和 XML 自身可以指定编码。这样的话,你应该使用 r.content 来找到编码,然后设置 r.encoding 为相应的编码。这样就能使用正确的编码解析 r.text 了。
在你需要的情况下,Requests 也可以使用定制的编码。如果你创建了自己的编码,并使用codecs 模块进行注册,你就可以轻松地使用这个解码器名称作为 r.encoding 的值, 然后由 Requests 来为你处理编码。
例子:
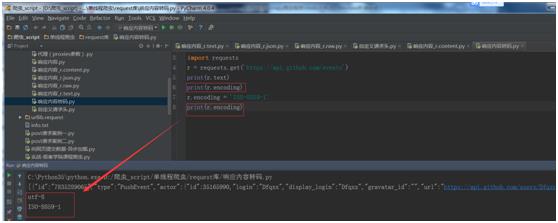
import requests
r = requests.get(\'https://api.github.com/events\')
print(r.text)
print(r.encoding)
r.encoding = \'ISO-8859-1\'
print(r.encoding)
运行结果:
1.9 自定义请求头。
如果你想为请求添加 HTTP 头部,只要简单地传递一个 dict 给 headers 参数就可以了。
例如,在前一个示例中我们没有指定 content-type。
import requests
url = \'https://api.github.com/some/endpoint\'
headers = {\'user-agent\': \'my-app/0.0.1\'}
r = requests.get(url, headers=headers)
注意: 定制 header 的优先级低于某些特定的信息源,例如:
1.如果在 .netrc 中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了auth= 参数,.netrc 的设置就无效了。
2.如果被重定向到别的主机,授权 header 就会被删除。
3.代理授权 header 会被 URL 中提供的代理身份覆盖掉。
4.在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
更进一步讲,Requests 不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的 header 信息都会被传递进去。
注意: 所有的 header 值必须是 string、bytestring 或者 unicode。尽管传递 unicode header 也是允许的,但不建议这样做。
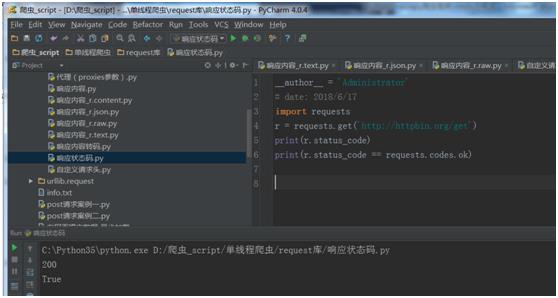
1.10 响应状态码。
我们可以通过r.status_code检测响应状态码。
例子:
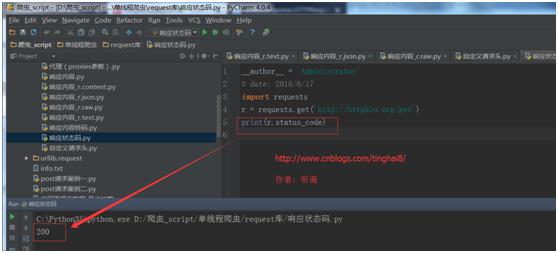
import requests
r = requests.get(\'http://httpbin.org/get\')
print(r.status_code)
运行结果:
为方便引用,Requests还附带了一个内置的状态码查询对象。
r.status_code == requests.codes.ok
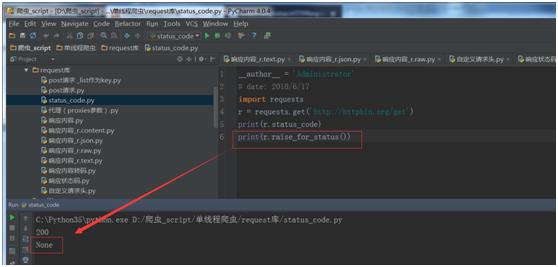
如果发送了一个错误请求(一个 4XX 客户端错误,或者 5XX 服务器错误响应),我们可以通过Response.raise_for_status() 来抛出异常。
import requests
r = requests.get(\'http://httpbin.org/get\')
print(r.status_code)
假如运行的结果为:404,会报如下错误:
bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
但是,由于我们的例子中 r 的 status_code 是 200 ,当我们调用 raise_for_status() 时,得到的是:None。
1.11 响应头。
我们可以通过r.headers查看以一个请求的服务器响应头。
例子:
import requests
r = requests.get(\'http://httpbin.org/get\')
print(r.headers)
运行结果:
{\'Server\': \'gunicorn/19.8.1\',
\'Access-Control-Allow-Origin\': \'*\',
\'Content-Length\': \'211\',
\'Content-Type\': \'application/json\',
\'Connection\': \'keep-alive\',
\'Access-Control-Allow-Credentials\': \'true\',
\'Date\': \'Sun, 17 Jun 2018 03:21:54 GMT\',
\'Via\': \'1.1 vegur\'}
返回的是一个字典,这个字典比较特殊:它是仅为 HTTP 头部而生的,HTTP 头部是大小写不敏感的,因此,我们可以使用任意大写形式来编写这些响应头字段。
还有一个特殊点,那就是服务器可以多次接受同一 header,每次都使用不同的值。 Requests 会自动将它们合并。
1.12 cookies
我们可以通过r.cookies 去获取一个请求的cookies,特别是在实战中登录模块用的比较多,我们可以通过cookies进行登录。
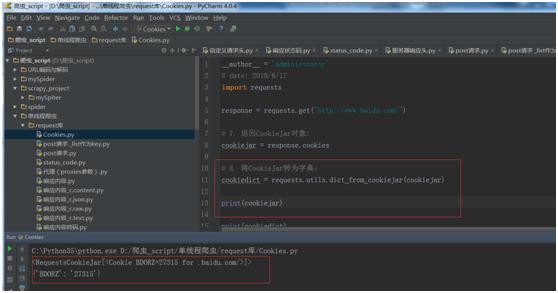
例子1:
import requests
response = requests.get("http://www.baidu.com/")
# 返回CookieJar对象:
cookiejar = response.cookies
# 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print(cookiejar)
print(cookiedict)
运行结果:
例子2:利用Cookie模拟登录步骤:
1.在浏览器输入http://demo.bxcker.com,输入用户名和密码登录。
2.登录成功点“客户管理”模块。
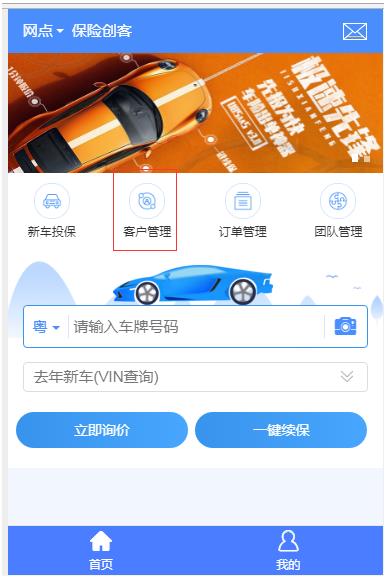
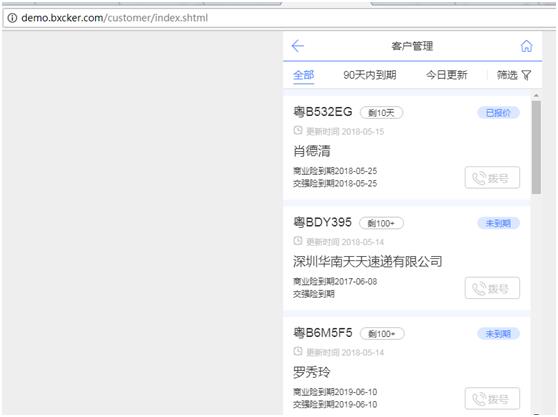
3.进入客户管理模块,显示客户列表。
4.通过抓包工具抓取客户列表,得到登录后的Cookie信息。
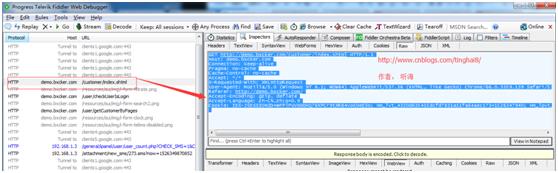
GET http://demo.bxcker.com/customer/index.shtml HTTP/1.1
Host: demo.bxcker.com
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36
Referer: http://demo.bxcker.com/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: IEX-JSESSIONID=WFPlPUVbbbkQ76XPCr9tXRB4voK0eESo; Hm_lvt_4320d635415dcfd7831a11fa64aec173=1526347940; Hm_lpvt_4320d635415dcfd7831a11fa64aec173=1526347940; SPRING_SECURITY_REMEMBER_ME_COOKIE=UE9kSDFGMnVsS291S2Z2V1k5c1daQT09OjZxWFVDUUhoVmR2UTdsWnRFRnlZZ0E9PQ
5.利用sublime text工具处理抓到的http请求头信息替换成字典。
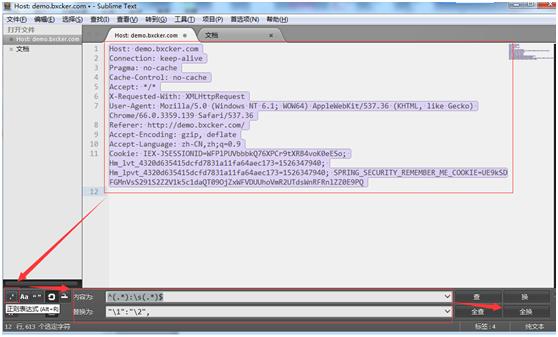
选择内容替换的方式是用正则表达式。
内容填写:^(.*):\\s(.*)$ (需要把header文件内容处理成字典,中间有个空格,所以加个\\s)
替换为填写:"\\1":"\\2",
点全换,处理完成之后变成如下:
"Host":"demo.bxcker.com",
"Connection":"keep-alive",
"Pragma":"no-cache",
"Cache-Control":"no-cache",
"Accept":"*/*",
"X-Requested-With":"XMLHttpRequest",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Referer":"http://demo.bxcker.com/",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cookie":"IEX-JSESSIONID=WFPlPUVbbbkQ76XPCr9tXRB4voK0eESo; Hm_lvt_4320d635415dcfd7831a11fa64aec173=1526347940; Hm_lpvt_4320d635415dcfd7831a11fa64aec173=1526347940; SPRING_SECURITY_REMEMBER_ME_COOKIE=UE9kSDFGMnVsS291S2Z2V1k5c1daQT09OjZxWFVDUUhoVmR2UTdsWnRFRnlZZ0E9PQ",
6. 处理完成之后直接拷贝到Python定义的头信息变量headers={}里。
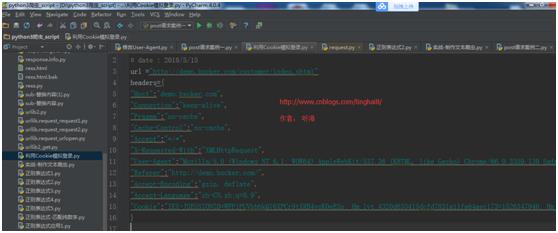
7. 整理headers 信息(去掉一些没用的,保留一些重要的)。
"Connection":"keep-alive",
"X-Requested-With":"XMLHttpRequest",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Referer":"http://demo.bxcker.com/",
"Cookie":"IEX-JSESSIONID=WFPlPUVbbbkQ76XPCr9tXRB4voK0eESo; Hm_lvt_4320d635415dcfd7831a11fa64aec173=1526347940; Hm_lpvt_4320d635415dcfd7831a11fa64aec173=1526347940; SPRING_SECURITY_REMEMBER_ME_COOKIE=UE9kSDFGMnVsS291S2Z2V1k5c1daQT09OjZxWFVDUUhoVmR2UTdsWnRFRnlZZ0E9PQ",
8. 编写完整的程序。
import requests
from urllib import parse
url ="http://demo.bxcker.com/qhiex_login"
headers ={
"Referer": "http://demo.bxcker.com/",
"Connection": "keep-alive",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Accept-Language": "zh-CN,zh;q=0.9",
}
data ={"username":"demo100","password":"demo100"}
# 通过urlencode()转码
postdata = parse.urlencode(data).encode(encoding=\'UTF8\')
response = requests.post(url, data = postdata,headers=headers)
# 返回CookieJar对象:
cookiejar = response.cookies
# 将CookieJar转为字典:
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print(cookiejar)
print(cookiedict)
#利用cookie登录,访问客户管理模块
r=requests.get("http://demo.bxcker.com/customer/index.shtml",headers=headers)
# 响应内容转码
r.encoding = \'utf-8\'
#打印响应内容
print(r.text)
运行结果:
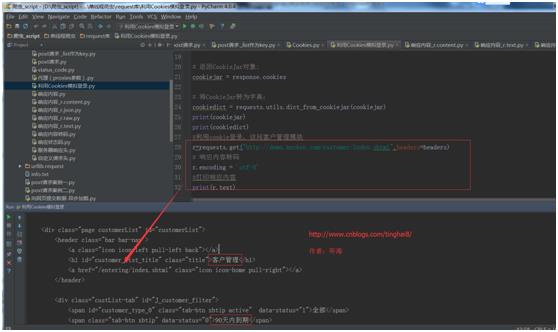
可以看到客户列表里的相关信息,证明是通过Cookie登录成功,然后跳转到客户管理模块,获取的客户信息。
1.13 Sission
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开。
会话能让我们在跨请求时候保持某些参数,比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
例子:利用Sission实现登录。
import requests
from urllib import parse
url ="http://demo.bxcker.com/qhiex_login"
headers ={
"Referer": "http://demo.bxcker.com/",
"Connection": "keep-alive",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Accept-Language": "zh-CN,zh;q=0.9",
}
data ={"username":"demo100","password":"demo100"}
# 创建session对象,可以保存Cookie值。
ssion = requests.session()
# 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在ssion里。
ssion.post("http://www.renren.com/PLogin.do", data = data)
# ssion包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面。
r = ssion.get("http://demo.bxcker.com/customer/index.shtml",headers=headers)
# 响应内容转码。
r.encoding = \'utf-8\'
# 打印响应内容。
print(r.text)
运行结果:
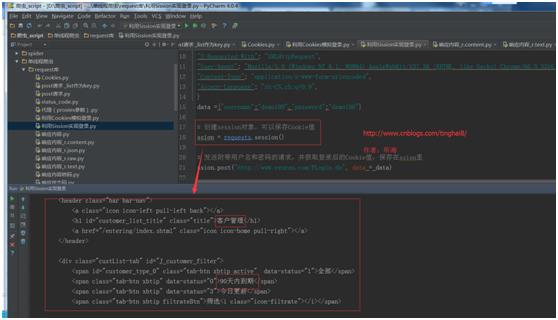
1.14 重定向和重定向历史。
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。
可以使用响应对象的 history 方法来追踪重定向。
Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
例如:Github 将所有的 HTTP 请求重定向到 HTTPS。
import requests
r = requests.get(\'http://github.com\')
print(r.url)
#\'https://github.com/\'
print(r.status_code)
# 200
print(r.history)
#[<Response [301]>]
如果你使用的是GET、OPTIONS、POST、PUT、PATCH 或者 DELETE,那么你可以通过 allow_redirects 参数禁用重定向处理:
import requests
r = requests.get(\'http://github.com\',allow_redirects=False)
print(r.status_code)
# 301
print(r.history)
#[]
如果你使用了 HEAD,你也可以启用重定向:
例子:
import requests
r = requests.get(\'http://github.com\',allow_redirects=False)
print(r.url)
#\'https://github.com/\'
print(r.history)
#[<Response [301]>]
1.15 请求超时设置。
你可以告诉 requests 在经过以 timeout 参数设定的秒数时间之后停止等待响应。
requests.get(\'http://github.com\', timeout=0.001)
1.16 代理(proxies参数)
如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求。
例子:
import requests
# 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get("http://www.baidu.com", proxies = proxies)
print response.text
也可以通过本地环境变量 HTTP_PROXY 和 HTTPS_PROXY 来配置代理:
export HTTP_PROXY="http://12.34.56.79:9527"
export HTTPS_PROXY="https://12.34.56.79:9527"
1.17 私密代理验证(特定格式) 和 Web客户端验证(auth 参数)。
urllib.request库 的做法比较复杂,requests只需要一步。
1.私密代理。
例子:
import requests
# 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = { "http": "xny_123:abc123@61.158.163.130:16816" }
response = requests.get("http://www.baidu.com", proxies = proxy)
print(response.text)
2.web客户端验证。
如果是Web客户端验证,需要添加 auth = (账户名, 密码)。
例子:
import requests
auth=(\'xiaony\', \'xny123\')
response = requests.get(\'http://192.168.1.102\', auth = auth)
print(response.text)
1.18 处理HTTPS请求 SSL证书验证。
Requests也可以为HTTPS请求验证SSL证书。
要想检查某个主机的SSL证书,你可以使用 verify 参数(也可以不写)。
例子:
import requests
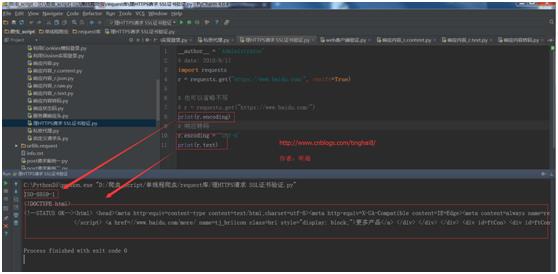
r = requests.get("https://www.baidu.com/", verify=True)
# 也可以省略不写
# r = requests.get("https://www.baidu.com/")
print(r.encoding)
# 响应转码
r.encoding = \'utf-8\'
print(r.text)
运行结果:
-------------------------------
个人今日头条账号: 听海8 (上面上传了很多相关学习的视频以及我书里的文章,大家想看视频,可以关注我的今日头条)

以上是关于python3 request 库的主要内容,如果未能解决你的问题,请参考以下文章