Python爬虫爬取深大信息工程学院老师个人介绍网址小实例
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫爬取深大信息工程学院老师个人介绍网址小实例相关的知识,希望对你有一定的参考价值。
1 #-*-coding:utf-8-*- 2 3 import requests 4 5 from bs4 import BeautifulSoup 6 7 r = requests.get (‘http://cie.szu.edu.cn/szucie/index.php/category/jsfc/‘) 8 9 #返回的‘r‘是一个包含了整个HTTP协议需要的各种各样东西的对象 10 11 html = r.content 12 13 #获取网页源代码 14 15 soup = BeautifulSoup (html , ‘html.parser‘) #html.parser是解析器 16 17 #下面根据我们看到的网页提取。首先提取这部分代码的第一行,先定位到这部分代码: 18 19 div_people_list = soup.find (‘div‘ , attrs = {‘class‘ : ‘col-mb-12 col-8 detail‘}) 20 21 #这里使用了BeautifulSoup对象的find方法,这个方法的意思是找到带有‘div‘这个标签并且参数包含"class = ‘people_list‘"的代码。如果有多个的话,find方法就取第一个 22 23 a_s = div_people_list.find_all (‘a‘) 24 25 #这里使用find_all方法取出所有标签为"a"的代码,返回一个列表(list)。"a"标签里的"href"参数是我们需要的老师的个人主页的信息,而标签里面的文字是老师的名字 26 27 for a in a_s : 28 url = a[‘href‘] 29 name = a.get_text() 30 print name , url
运行结果如下:
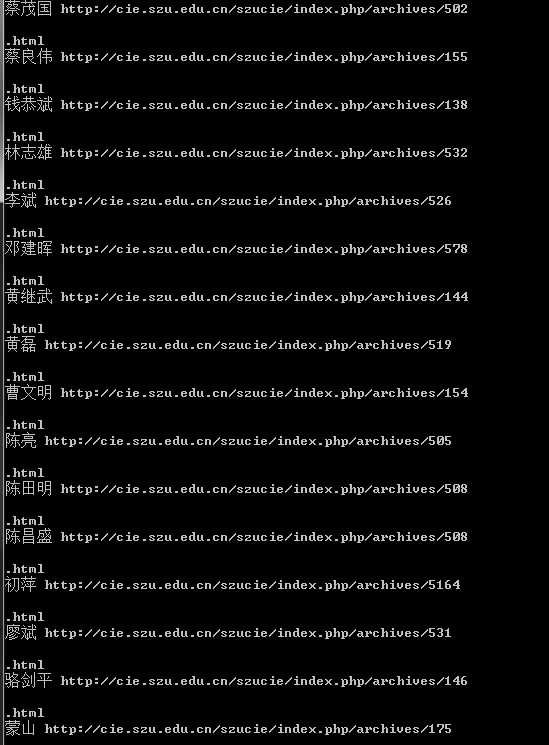
以上是关于Python爬虫爬取深大信息工程学院老师个人介绍网址小实例的主要内容,如果未能解决你的问题,请参考以下文章