python beautifulsoup应用问题?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python beautifulsoup应用问题?相关的知识,希望对你有一定的参考价值。
想抓企业名字,给讲讲哪里不对出不了结果
from selenium import webdriver
import timedriver = webdriver.Chrome() # 打开 Chrome 浏览器driver.get("http://m.chkling.com.cn/activity?sid=14f6f1619fb9e670&cfrom=UP2CW&code=001tnrFa1yv2AA0HsuIa1648644tnrFg&state=")
time.sleep(2) #等一下driver.find_element_by_xpath("(//img[contains(@src,'https://img.chkling.com/m/img/close_btn.png')])[2]").click()
from bs4 import BeautifulSoupdata = driver.page_source #获取网页文本soup = BeautifulSoup(data,features="lxml")
name = soup.find_all('data-v-1937cf82','class':'player-name')
print(name)driver.quit()
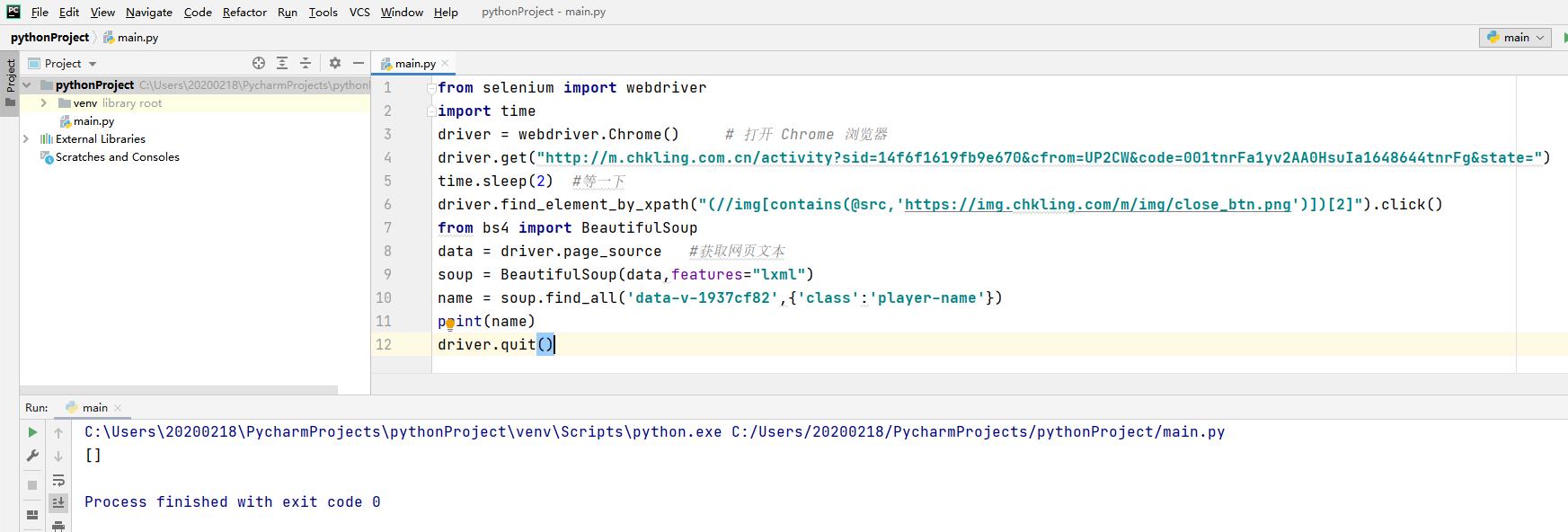
查一下 beautifulsoup 的文档,有关 css 选择器的部分,对一下 find_all 里面的语法是不是正确 。在写 find_all 的时候一层一层选下去,不要一开始就写到最里面一层。
平时写解析的时候用 lxml 比较多,beautifulsoup 的写法太久没写过了。追问
直接输出driver.page_source里的内容没有问题,卡在find_all这块了
追答太久没写过 beautifulsoup 了,你自己看一下 css 选择器吧。
我用 lxml 的 xpath 选择器实现一遍给你看。
from lxml import etree
response = etree.HTML(driver.source)
name_list = response.xpath('//div[@class="player-name"]/text()')
如无意外的话,name_list 估计就是你想要的结果。
太懒了,不想再去看 beautifulsoup 了。以后我也基本不会用到。
谢谢,已经实现了。还有我想问下要现在输出内容都在一块,想输出内容一行一行的应该怎么写?
追答恕我直言,你的基础像是没学过,现在写爬虫似是太超前了。就算目标被你抓到,想保存等动作可能心有余而力不足。可能的话先把基础学一下吧。
如果是说上面这一句的话,name_list = response.xpath('//div[@class="player-name"]/text()'),返回是一个列表,用 for 就能轮询出来。爬虫的难度在于你前面用 selenium 另辟巧径的这块。后面的输出和保存已经是目标到手了的部分,已不算有难度的部分。
哈哈 您看的真准 我都是现看视频东拼西凑的代码
参考技术A 觉得不是beautifulsoup包的问题。首先,你要该选择器下是否有你想要的数据,建议打印出来看一下。其次,你也要确定自己的选择器没有写错Python BeautifulSoup,遍历标签和属性
【中文标题】Python BeautifulSoup,遍历标签和属性【英文标题】:Python BeautifulSoup, iterating through tags and attributes 【发布时间】:2017-11-27 04:02:24 【问题描述】:我想遍历 html 页面某些部分中的所有标签。我应用了 BeautifulSoup,但我可以没有它,只有 Selenium 库。 假设我有以下 html 代码:
<table id="myBSTable">
<tr>
<th>Column A1</th>
<th>Column B1</th>
<th>Column C1</th>
<th>Column D1</th>
<th>Column E1</th>
</tr>
<tr>
<td data="First Column Data"></td>
<td data="Second Column Data"></td>
<td title="Title of the First Row">Value of Row 1</td>
<td>Beautiful 1</td>
<td>Soup 1</td>
</tr>
<tr>
<td></td>
<td data-g="Second Column Data"></td>
<td title="Title of the Second Row">Value of Row 2</td>
<td>Selenium 1</td>
<td>Rocks 1</td>
</tr>
<tr>
<td></td>
<td></td>
<td title="Title of the Third Row">Value of Row 3</td>
<td>Pyhon 1</td>
<td>Boulder 1</td>
</tr>
<tr>
<th>Column A2</th>
<th>Column B2</th>
<th>Column C2</th>
<th>Column D2</th>
<th>Column E2</th>
</tr>
<tr>
<td data="First Column Data"></td>
<td data="Second Column Data"></td>
<td title="Title of the First Row">Value of Row 1</td>
<td>Beautiful 2</td>
<td>Soup 2</td>
</tr>
<tr>
<td></td>
<td data-g="Second Column Data"></td>
<td title="Title of the Second Row">Value of Row 2</td>
<td>Selenium 2</td>
<td>Rocks 2</td>
</tr>
<tr>
<td></td>
<td></td>
<td title="Title of the Third Row">Value of Row 3 2</td>
<td>Pyhon 2</td>
<td>Boulder 2</td>
</tr>
</table>
我的这部分工作完美:
#Selenium libraries
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
#BeautifulSoup
from bs4 import BeautifulSoup
browser = webdriver.Firefox()
browser.get('http://urltoget.com')
table = browser.find_element_by_id('myBSTable')
bs_table = BeautifulSoup(table.get_attribute('innerHTML'), 'lxml')
#So far so good
rows = bs_table.findAll('tr')
for tr in rows:
#Here is where I need help
#I want to iterate through all tags
#but I don't know if is going to be a th or a td
#At the same time I need to do something
#if is a td or a th
这就是我想要完成的:
#The following is a pseudo code
for col in tr.tags:
print col.name, col.value
for attribute in col.attrs:
print " ", attribute.name, attribute.value
#End pseudo code
谢谢, 附庸风雅
【问题讨论】:
【参考方案1】:您可以通过指定要查找的标签列表找到td 或th。要获取所有元素属性,请使用.attrs attribute:
rows = bs_table.find_all('tr')
for row in rows:
cells = row.find_all(['td', 'th'])
for cell in cells:
print(cell.name, cell.attrs)
【讨论】:
谢谢,您的解决方案几乎奏效了。我说几乎是因为 cell.attrs 没有工作。经过一番研究,我发现了以下遍历属性的方法:**for attr, value in cell.attrs.iteritems(): print " attribute", attr, value** 我不得不使用 attrs 中的 iteritems(),因为如果我只有 cells.attrs,它就不起作用。【参考方案2】:
另类循环(动作在底部):
html='''<table id="myBSTable">
<tr>
<th>Column A1</th>
<th>Column B1</th>
<th>Column C1</th>
<th>Column D1</th>
<th>Column E1</th>
</tr>
<tr>
<td data="First Column Data"></td>
<td data="Second Column Data"></td>
<td title="Title of the First Row">Value of Row 1</td>
<td>Beautiful 1</td>
<td>Soup 1</td>
</tr>
<tr>
<td></td>
<td data-g="Second Column Data"></td>
<td title="Title of the Second Row">Value of Row 2</td>
<td>Selenium 1</td>
<td>Rocks 1</td>
</tr>
<tr>
<td></td>
<td></td>
<td title="Title of the Third Row">Value of Row 3</td>
<td>Pyhon 1</td>
<td>Boulder 1</td>
</tr>
<tr>
<th>Column A2</th>
<th>Column B2</th>
<th>Column C2</th>
<th>Column D2</th>
<th>Column E2</th>
</tr>
<tr>
<td data="First Column Data"></td>
<td data="Second Column Data"></td>
<td title="Title of the First Row">Value of Row 1</td>
<td>Beautiful 2</td>
<td>Soup 2</td>
</tr>
<tr>
<td></td>
<td data-g="Second Column Data"></td>
<td title="Title of the Second Row">Value of Row 2</td>
<td>Selenium 2</td>
<td>Rocks 2</td>
</tr>
<tr>
<td></td>
<td></td>
<td title="Title of the Third Row">Value of Row 3 2</td>
<td>Pyhon 2</td>
<td>Boulder 2</td>
</tr>
</table>'''
Soup = BeautifulSoup(html)
rows = Soup.findAll('tr')
for tr in rows:
for z in tr.children:
if z.name =='td':
do stuff1
if z.name == 'th':
do stuff2
【讨论】:
以上是关于python beautifulsoup应用问题?的主要内容,如果未能解决你的问题,请参考以下文章