李航统计学习概述
Posted chenfengshijie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了李航统计学习概述相关的知识,希望对你有一定的参考价值。
监督学习
感知机
-
概念:
-
感知机模型的基本形式是:
\\(f(x) = sign(w \\cdot x + b)\\)
其中,\\(x\\) 是输入样本的特征向量,\\(w\\) 是权值向量,\\(b\\) 是偏置量,\\(w \\cdot x\\) 表示向量 \\(w\\) 和 \\(x\\) 的点积。\\(sign\\) 函数表示符号函数,当输入大于 0 时输出 1,否则输出 -1。
-
-
要求模型必须线性可分
K近邻
-
基本思想:是对于一个新的输入样本,在训练数据集中找出与之最邻近的k个样本,并将其预测结果作为该样本的输出。
-
步骤
- 计算测试样本与训练样本集中每个样本的距离;
- 选取距离最近的k个训练样本;
对于分类问题,采用投票法,即将k个样本中出现最多的类别作为预测结果;对于回归问题,采用平均值,即将k个样本的输出值的平均值作为预测结果。
-
选取最近的k个样本一般采用kd树来进行实现。
kd树采取方差最大的那一变量(的中位数)进行分割
kd树的查询首先寻找到该点所在的子节点的部分。然后逐渐向上递归比较父节点和父节点的另一个子节点是否在某个领域(当前的最小距离)内具有交际。
朴素贝叶斯
- 假设每个特征之间相互独立。即\\(P(X_1,X_2,X_3,...,X_n|Y)=P(X_1|Y)*P(X_2|Y)*...*P(X_n|Y)\\)
- 后验概率最大化,无论是采用极大似然估计或者贝叶斯估计,都可以推导出相应的公式。
- 假设有 \\(n\\) 个特征和 \\(m\\) 个类别,我们需要分类一个新的样本 \\(x\\),其中 \\(x_i\\) 表示第 \\(i\\) 个特征的取值。根据贝叶斯定理,可以计算出给定样本 \\(x\\) 属于第 \\(j\\) 个类别的后验概率 \\(P(C_j | x)\\),即:
其中,\\(P(C_j)\\) 表示类别 \\(j\\) 在训练集中的先验概率,\\(P(x | C_j)\\) 表示样本 \\(x\\) 在给定类别 \\(j\\) 的条件下的概率密度函数(通常假设为高斯分布,或者直接使用频率代替概率),\\(P(x)\\) 表示样本 \\(x\\) 在所有类别下的概率。由于分母 \\(P(x)\\) 对于所有类别来说都是相同的,因此可以省略,只需要计算分子即可。此时,\\(P(C_j | x)\\) 可以看作样本 \\(x\\) 属于类别 \\(j\\) 的“置信度”,将样本分配给概率最大的类别即可。
决策树
- 分为三个步骤:特征选择、树的生成和剪枝。
- 需要了解下面几个概念:
-
不同的决策树算法就是基于上述不同的指标来进行特征的选择。
-
剪枝算法:首先定义一个损失函数\\(L(T)=\\sum_t=1^|T|N_tH_t(T)+\\alpha|T|,其中T为子节点,N_t为子节点的样本点数量。\\)对于决策树每一个子节点,如果多个子节点的损失大于父节点将他们吸收的损失,那么父节点就合并所有的子节点,并向上计算,可以通过递归(或者非递归)的动态规划进行解决。
logitics和最大熵模型
类似感知机,只是将最终的函数由sign改为了logistics。
支持向量机
首先了解以下概念:
- 函数间隔.\\(y|wx+b|\\)
- 几何间隔.\\(y\\frac|wx+b||w|\\)
- 线性支持向量机就是要最大几何间隔。
- 拉格朗日对偶原理和拉格朗日乘子法。拉格朗日对偶
- 支持向量
- 合页函数最优化求解和支持向量的原问题的等价性
- SMO启发式方法
AdaBoost
假定具备一个弱分类器(该分类准确率仅仅比随机猜测的概率高一些),AdaBoost通过综合多种分类器的线性叠加,从而实现一个强分类器。
AdaBoost具有两种等价的解释:
- 通过调整训练数据的权重(增加错误样例的权重,减小正确样例的权重),从而训练得到不同的弱分类器\\(G_1,G_2...G_m和相应的权重\\alpha_1...\\alpha_m\\),最终线性叠加得到\\(f=\\alpha_1G_1+...+\\alpha_mG_m\\).
- AdaBoost等价于不断求解残差的拟合。
EM算法
EM算法用的特别广泛,需要完全理解它的推导过程。
- EM算法的推导
- EM算法求解高斯混合模型
- EM算法的推广,F函数。
隐马尔可夫模型
- 三个基本问题:预测、评估和学习
- 前向、后向算法
- 维特比算法,本质上三个算法都是动态规划
- Baum-Welch算法求解学习问题
条件随机场
- 势函数的定义和条件随机场的定义
- 使用前向后向算法求解概率
- 学习算法,使用迭代尺度、拟牛顿进行学习
无监督学习
聚类算法
- 层次化聚类
- k均值聚类
奇异值分解
矩阵的SVD分解,并对\\(\\Sigma\\)进行截断(取前k个奇异值)
主成分分析
SVD的应用
潜在语义分析
概率潜在语义分析
马尔可夫蒙特卡洛方法
-
拒绝采样法
-
Metropolis-Hasting采用法
- 初始化:给定样本起始值 \\(x^(0)\\)
- 对于 \\(t=1,2,\\ldots,T\\),进行如下迭代:
从给定的候选分布 \\(q(x^(t)|x^(t-1))\\) 中抽取一个样本 \\(x^\\prime\\)
计算接受概率 $$\\alpha=\\min(1,\\fracp(x\\prime)p(x)\\fracq(x(t-1)|x\\prime)q(x\\prime|x))$$ - 以概率 \\(\\alpha\\) 接受样本 \\(x^\\prime\\),即 \\(x^(t)=x^\\prime\\),否则拒绝样本 \\(x^\\prime\\),即 \\(x^(t)=x^(t-1)\\)
- 返回样本集合 \\(x^(1),x^(2),\\ldots,x^(T)\\)
其中,\\(T\\) 是迭代次数,\\(x^(t)\\) 表示第 \\(t\\) 次迭代后的样本值,\\(p(x)\\) 表示目标概率分布,\\(q(x^(t)|x^(t-1))\\) 表示给定上一个状态 \\(x^(t-1)\\) 的条件下,生成下一个状态 \\(x^(t)\\) 的候选分布,\\(\\alpha\\) 表示接受候选状态的概率,即 \\(x^(t)\\) 作为下一个状态的概率,\\(\\min1,\\cdots\\) 保证了接受概率不会大于 \\(1\\),从而保证了接受的状态总是有意义的。
-
吉布斯采用法
吉布斯采样(Gibbs Sampling)是一种基于马尔可夫链蒙特卡罗(MCMC)方法的采样算法,用于从多维分布中抽取样本。它通过迭代更新每个维度的条件概率分布来得到样本。吉布斯采样的公式如下:
- 初始化:给定样本起始值 \\(x^(0)=(x_1^(0),x_2^(0),\\ldots,x_n^(0))\\)
对于 \\(t=1,2,\\ldots,T\\),进行如下迭代:
对于第 \\(i\\) 维,计算条件概率 \\(p(x_i|x_1^(t),\\ldots,x_i-1^(t),x_i+1^(t-1),\\ldots,x_n^(t-1))\\) - 从条件概率分布 \\(p(x_i|x_1^(t),\\ldots,x_i-1^(t),x_i+1^(t-1),\\ldots,x_n^(t-1))\\) 中抽取一个样本,即 \\(x_i^(t+1)\\sim p(x_i|x_1^(t),\\ldots,x_i-1^(t),x_i+1^(t-1),\\ldots,x_n^(t-1))\\)
- 返回样本集合 \\(x^(1),x^(2),\\ldots,x^(T)\\)
其中,\\(T\\) 是迭代次数,\\(x_i^(t)\\) 表示第 \\(t\\) 次迭代后第 \\(i\\) 维的值,\\(p(x_i|x_1^(t),\\ldots,x_i-1^(t),x_i+1^(t-1),\\ldots,x_n^(t-1))\\) 表示在给定其他维度取值的情况下第 \\(i\\) 维的条件概率分布。
吉布斯采样的核心思想是,通过条件概率分布来描述多维分布的联合概率分布,从而能够通过单个维度的条件概率来更新样本值,避免了计算联合概率分布的复杂度。通过多次迭代,吉布斯采样可以得到服从多维分布的样本集合,从而可以用于估计多维分布的各种性质。需要注意的是,吉布斯采样的收敛性和稳定性是需要保证的,否则会导致采样结果不准确或者不收敛。针对不同的问题和数据分布,需要进行适当的调整和优化。
- 初始化:给定样本起始值 \\(x^(0)=(x_1^(0),x_2^(0),\\ldots,x_n^(0))\\)
潜在迪利克雷分配
PageRank算法
其中,\\(PR(p_i)\\) 表示网页 \\(p_i\\) 的PageRank值,\\(d\\) 是一个常数,称为阻尼因子,通常取值为 0.85。\\(N\\) 是网页总数,\\(M(p_i)\\) 表示指向网页 \\(p_i\\) 的所有网页集合,\\(L(p_j)\\) 表示网页 \\(p_j\\) 指向的网页数。
统计学习方法(李航)
统计学习方法概论:
(一),统计学习
1,统计学习的特点

2,统计学习的对象

3,统计学习的目的

4,统计学习的方法(重点:模型的集合,策略(模型的选择),算法(模型的实现调优))

(二),监督学习重要概念
1,输入空间,特征向量空间,输出空间,预测问题分为(回归问题(输出为连续即可),分类问题,标注问题)


(三),统计学习三要素
1,模型
决策函数模型:
条件概率模型:
2,策略
2.1 损失函数:


2.2 经验风险最小化和结构最小化


如贝叶斯估计的最大后验概率就是一种结构风险最小化的一个例子,通过使用先验概率作为发现(复杂的模型先验概率大)
3,算法

(四)模型评估选择
1,训练误差和测试误差
2,过拟合



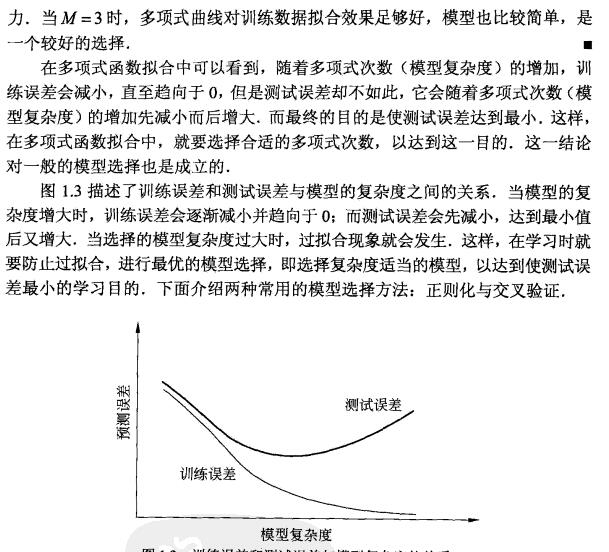
过拟合和欠拟合产生的原因及解决方式:
4,正则化:L1和L2范式
5,交叉验证:训练集,验证集,测试集
6,泛化误差,泛化误差上界
7,生成模型(朴素贝叶斯)和判别模型(决策树,支持向量机)

8,分类模型

9,标注问题

以上是关于李航统计学习概述的主要内容,如果未能解决你的问题,请参考以下文章