c++中,float double区别
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c++中,float double区别相关的知识,希望对你有一定的参考价值。
表示的范围?
用法上的区别,各自都是该何时使用?
区别:
一、精度的区别
float为单精度,内存中占4个字节,有效数位是7位。
double为双精度,占8个字节,有效数位是16位。
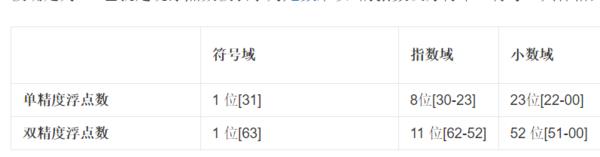
二、指数和尾数长度的区别
float指数长度为8位,尾数长度23位。
double指数长度为11位,尾数长度52位。
三、取值范围的区别
float的取值范围为3.4E-38~3.4E+38。
double的取值范围为1.7E-308~1.7E+308。
四、IEEE的区别
float的IEEE为1,遵从的是IEEE R32.24 。
double的IEEE为1,但遵从的是IEEE R64.53。
扩展资料
浮点型变量:
实型变量分为两类:单精度型和双精度型,
其类型说明符为float 单精度说明符,double 双精度说明符。在Turbo C中单精度型占4个字节(32位)内存空间,其数值范围为3.4E-38~3.4E+38,只能提供七位有效数字。双精度型占8 个字节(64位)内存空间,其数值范围为1.7E-308~1.7E+308,可提供16位有效数字。
实型变量说明的格式和书写规则与整型相同。
例如: float x,y; (x,y为单精度实型量)
double a,b,c; (a,b,c为双精度实型量)
实型常数不分单、双精度,都按双精度double型处理。
参考资料来源:百度百科—float
参考资料来源:百度百科—double
参考资料来源:百度百科—浮点型数据
参考技术Afloat和double都是C++中的浮点型数据类型,三者的区别是:
1、精度是不同的。
浮点类型是单精度浮点数,双类型是双精度浮点数。
2、分配存储空间。
c++编译器为浮点类型分配4字节,为双类型分配8字节。
3、有效位的个数是不同的。
Float可以提供6位有效数字,double可以提供15位有效数字。
扩展资料:
数据介绍
1、转换成十进制
它由0-9位数字和小数点组成。例如,0.0,。255.789, 0.13, 5.0, 300, -267.8230都是合法的实数。
2、指数形式
它由十进制数字、顺序码的符号“e”或“e”以及顺序码(只能是整数,并且可以签名)组成。
其一般形式为en(一个十进制数,n为十进制整数),其值为a*10, n如:2.1 E 5(等于5的2.1 * 10),3.7依照(等于二十3.7 * 10)的力量,0.5 E 7(等于0.5 * 10的7次方),0.5 E 7(等于0.5 * 10的7次方),-2.8依照(等于- 2.8依照(= - 2.8 * 10-2th权力)。
下面是不合法的实数345 E(没有decidecimal点)7(十进制数在E 7(E秩序象征7)E-5(5号(5号(没有秩序的象征)5(这项研究的结果如下:1。No) 2.7E(无订单编号)。
标准C允许浮点数使用后缀。后缀“f”或“f”表示该数字是浮点数。例如,356f和356。是等价的。例2.2说明了这种情况:
Void main()
Printf ("% f\\ n% f\\ n", 356。,356 f);
Void指定main不返回任何值,并且printf显示结果的结尾
浮点变量:
实变量分为单精度变量和双精度变量。
类型描述符是浮动单精度描述符和双精度双精度描述符。在Turbo C中,单精度类型占用内存空间4字节(32位),其数值范围为3.4E-38-3.4E+38,只能提供7位有效数字。双精度类型占用内存空间8字节(64位)。其数值范围为1.7E-308-1.7E+308,可提供16位有效数字。
实变量具有与整数相同的格式和编写规则。
例如,浮动x, y;(x, y为单精度实型量)
双a b c;(a、b、C为双精度实型量)
实型常数按双精度处理,不需要单精度或双精度。
参考文献:
百度百科-浮点型数据
float和double都是C++中的浮点型数据类型,它们的区别:
一、精度的区别
float为单精度,内存中占4个字节,有效数位是7位。
double为双精度,占8个字节,有效数位是16位。
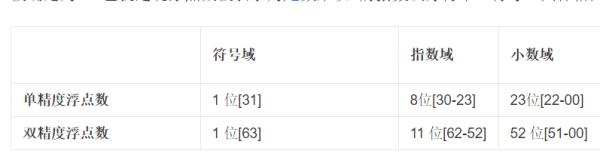
二、指数和尾数长度的区别
float指数长度为8位,尾数长度23位。
double指数长度为11位,尾数长度52位。
三、取值范围的区别
float的取值范围为3.4E-38~3.4E+38。
double的取值范围为1.7E-308~1.7E+308。
四、IEEE的区别
float的IEEE为1,遵从的是IEEE R32.24 。
double的IEEE为1,但遵从的是IEEE R64.53。
参考资料来源:百度百科——浮点型数据
参考技术C1、精度不同
float类型是单精度浮点数,double类型是双精度浮点数。
2.分配的存储空间
C++编译器为floatL类型分配4字节,而为double类型则分配8字节。
3.拥有的有效数字位数不同
float可提供6位有效数字,而double则可以提供15位有效数字。

扩展资料
float和double的存储方式:
float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*10^0 ,而120.5可以表示为:1.205*10^2 ,。
而计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001*2^3 。
1110110.1可以表示为1.1101101*2^6 ,任何一个数都的科学计数法表示都为1.xxx* 2^n, 尾数部分就可以表示为xxxx,第一位都是1嘛,将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit。
参考资料:百度百科-C++
参考技术D区别
1、表示的范围区别。
(1)单精度浮点型(float )专指占用32位的存储空间,字节数4,可以表示十进制的6或7位有效数字。
(2)双精度型(double)占用64位的存储空间,字节数8,可以表示十进制的15或16位有效数字。
2、用法区别。
(1)单精度浮点型(float ):当你需要小数部分并且对精度的要求不高时,单精度浮点型的变量是有用的。
(2)双精度型(double):当你需要保持多次反复迭代的计算的精确性时,或在操作值很大的数字时,双精度型是最好的选择。
3、运算速度、消耗内存不同。double消耗内存是float的两倍,double的运算速度比float慢得多。

拓展资料:
1、.单精度浮点型(float)和双精度型(double)是浮点型的两种类型。浮点数表示法利用科学计数法来表达实数(real),当计算的表达式有精度要求时被使用。例如,计算平方根,或超出人类经验的计算如正弦和余弦,它们的计算结果的精度要求使用浮点型。
2、C标准规定的浮点型有float、double、long double,和整型一样,既没有规定每种类型占多少字节,也没有规定采用哪种表示形式。大部分平台的浮点数实现遵循IEEE 754,float型通常是32位,double型通常是64位。 long double型通常是比double型精度更高的类型,但各平台的实现有较大差异。
参考资料:百度百科-浮点型
c#中decimal ,double,float的区别
转自:http://www.cnblogs.com/lovewife/articles/2466543.html
单精度就是指4个字节的浮点数,即float
双精度就是指8个字节的浮点数,即double
decimal是高精度
浮点型
|
Name |
CTS Type |
Description |
Significant Figures |
Range (approximate) |
|---|---|---|---|---|
|
float |
System.Single |
32-bit single-precision floating point |
7 |
±1.5 × 10?45 to ±3.4 × 1038 |
|
double |
System.Double |
64-bit double-precision floating point |
15/16 |
±5.0 × 10 ?324 to ±1.7 × 10308 |
如果我们在代码中写一个12.3,编译器会自动认为这个数是个double型。所以如果我们想指定12.3为float类型,那么你必须在数字后面加上F/f:
float f = 12.3F;
decimal类型
作为补充,decimal类型用来表示高精度的浮点数
|
Name |
CTS Type |
Description |
Significant Figures |
Range (approximate) |
|---|---|---|---|---|
|
decimal |
System.Decimal |
128-bit high precision decimal notation |
28 |
±1.0 × 10?28 to ±7.9 × 1028 |
从上表可以看出,decimal的有效位数很大,达到了28位,但是表示的数据范围却比float和double类型小。decimal类型并不是C#中的基础类型,所以使用的时候会对计算时的性能有影响。
我们可以像如下的方式定义一个decimal类型的浮点数:
decimal d = 12.30M;
对decimal、float、double错误的认识
在精确计算中使用浮点数是非常危险的,尽管C#在浮点数运算时采取了很多措施使得浮点数运算的结果看起来是非常正常的。但实际上如果不清楚浮点数的特性而贸然使用的话,将造成非常严重的隐患。
考虑下面的语句:
double dd = 10000000000000000000000d;
dd += 1;
Console.WriteLine ( "0:G50", dd );
输出是什么?谁知道?
输出是:1000000000000000000000000
这就是浮点数精度损失的问题,最重要的是,在精度损失的时候,不会报告任何的错误,也不会有任何的异常产生。
浮点数的精度损失可能在很多地方出现,例如d * g / g 不一定等于d,d / g * g也不一定等于d。
还有两个非常危险的错误认识!!
1、decimal不是浮点型、decimal不存在精度损失。
下面有段程序大家可以去看看结果是什么。记住!所有的浮点型变量都存在精度损失的问题,而decimal是一个不折不扣的浮点型,不论它精度有多高,精度损失依然存在!
decimal dd = 10000000000000000000000000000m;
dd += 0.1m;
Console.WriteLine ( "0:G50", dd );
2、decimal所能储存的数比double大,从double到decimal的类型转换不会出现任何问题。
微软在decimal的帮助上真的要好好反省了。实际上只有从整形到decimal的转换才是扩大转换,decimal的精度比double大,但所能储存的最大数却比double要小。
“decimal 类型是适合财务和货币计算的 128 位数据类型。”
当然,decimal在大多数情况下是安全的,但浮点数在理论上是不安全的。
至于精度误差造成的显示问题,则是很容易修补的。浮点数会带来的问题以及整型能避免的问题就是一个:
譬如说从A帐户转账到B帐户,经计算得出结果是3.788888888888888元,那么我们从A帐户扣除这么多钱,B帐户增加这么多钱,但事实上A帐户不一定会扣除准确的数值,例如A帐户的金额在100000000000,那么这个时候100000000000 - 3.788888888888888运算结果很有可能是99999999996.211111111111112。而这个时候B帐户的金额为0则很有可能加上准确的数值,如3.788888888888888,这样一来,0.011111111111112元钱就会不见了,日积月累的,差额就会越来越大。
double是64位的,比single-32位精度高
decimal128位高精度浮点数,常用于金融运算,不会出现浮点数计算的误差
,decimal 类型具有更高的精度和更小的范围,这使它适合于财务和货币计算。
早上刚到办公室,就被中试室打来电话叫去,原来软件在测试过程中发现了个小问题:软件读出来的数据比设备LCD上显示数据小了 0.01 。
怎么会这样呢,数据类型我已经用了 double 型了整个数据长度也就6位,double型的数据有效数据位为7位,也够了阿,不明白。于是回来下断点跟踪。
前面double型在算的时候,是没问题的,数据是66.24,可是当我把66.24 乘上100后的处理结果就不对了:66.24*100.0d = 6623.9999…91,问题就出在这里了。查了msdn,Double型的数据:Double 值类型表示一个值介于 -1.79769313486232e308 和 +1.79769313486232e308 之间的双精度 64 位数字,浮点数只能近似于十进制数字,浮点数的精度决定了浮点数近似于十进制数字的精确程度。默认情况下,Double 值的精度是 15 个十进制位,但内部维护的最大精度是 17 位。所以就出现了乘上一百后,精度就不够了。又由于我们在处理数据时,是不允许四舍五入的,所以,经过单位转换后,软件中最终显示的数据为 66.23 ,比LCD上显示的66.24 小了 0.01。
因此,这之后就想到了应该用更高精度的 decimal 型。
|
类型 |
大致范围 |
精度 |
.NET Framework 类型 |
|
decimal |
±1.0 × 10e?28 至 ±7.9 × 10e28 |
28 到 29 位有效位 |
System.Decimal |
在声明decimal类型数据时,可以 a: decimal myData = 100,此时编译器隐式转换整型数100为 100.0m;当然也可以b: decimal myData = 100.0m,但是 如果是 decimal myData = 100.0d或者decimal myData = 100.0f,就不行了,因为100.0d或者100.0f,编译器认为是浮点数,而浮点数和decimal 类型之间不存在隐式转换;因此,必须使用强制转换在这两种类型之间进行转换。This is the important,否则编译器便报错。所以一般的财务软件在处理时,都会用decimal 类型。
好了,改用decimal 型之后,就OK 了,结果就完完整整地显示为 66.24 了。
以上是关于c++中,float double区别的主要内容,如果未能解决你的问题,请参考以下文章