算法表达式生成器
Posted 404 NotFound
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法表达式生成器相关的知识,希望对你有一定的参考价值。
1.算法简介及二分法
1.什么是算法:
算法就是解决问题的有效方法 不是所有的算法都很高效也有不合格的算法
2.算法应用场景:
各种软件、网站推送
成像算法(AI相关)
几乎涵盖了我们日常生活中的方方面面
3.算法工程师要求
待遇非常好 但是要求也非常高
4.算法部门
不是所有的互联网公司都养得起算法部分 只有大型互联网公司才有
算法部门类似于药品研发部分
5.二分法
是算法中最简单的算法 甚至都称不上是算法
"""
二分法使用要求
待查找的数据集必须有序
二分法的缺陷
针对开头结尾的数据 查找效率很低
常见算法的原理以及伪代码
二分法、冒泡、快拍、插入、堆排、桶排、数据结构(链表 约瑟夫问题 如何链表是否成环)
"""
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
def get_middle(l1, target_num):
middle_index = len(l1) // 2
if len(l1) == \'0\':
print(\'很抱歉您要找的数据没有\')
if target_num > l1[middle_index]:
right_l1 = l1[middle_index + 1::]
print(right_l1)
return get_middle(right_l1, target_num)
elif target_num < l1[middle_index]:
left_l1 = l1[:middle_index:]
print(left_l1)
return get_middle(left_l1, target_num)
else:
print(\'恭喜你,找到了\')
get_middle(l1, 1232)
2.三元表达式
原代码:
user_pwd = \'123\'
if user_pwd == \'123\':
print(\'密码输入正确\')
else:
print(\'密码输入错误\')
1.代码简单并且只有一行,可以直接在冒号后面编写
user_pwd == \'123\'
if user_pwd == \'123\':print(\'密码输入正确\')
else:print(\'密码输入错误\')
2.三元表达式:
语法结构:
数据值1 if 条件 else 数据值2
条件成立则使用数据值1,条件不成立则使用数据值2
user_pwd = \'123\'
res = \'密码输入正确\' if user_pwd == \'123\' else \'密码输入错误\'
print(res)
"""
当结果是二选一的情况下,使用三元表达式较为简洁,并且不推荐多个三元表达式嵌套
"""
3.列表生成式
1.要求:name_list = [\'jason\', \'kevin\', \'oscar\', \'tony\', \'jerry\']
给列表中所有人名的后面加上_NB的后缀
方法1:for 循环
name_list = [\'jason\', \'kevin\', \'oscar\', \'tony\', \'jerry\']
l1 = []
for i in name_list:
new_i = i + \'_NB\' # 或new_i = f\'name_NB\'
l1.append(new_i)
print(l1) # [\'jason_NB\', \'kevin_NB\', \'oscar_NB\', \'tony_NB\', \'jerry_NB\']
方法2:列表生成式
list = [\'jerry\', \'liming\', \'jenny\', \'danny\', \'oscar\']
list = [name + \'666\' for name in list]
print(list) # [\'jason_NB\', \'kevin_NB\', \'oscar_NB\', \'tony_NB\', \'jerry_NB\']
"""
只适用于字符串,其它数据类型不适用
"""
2.给列表中指定的元素(字符串)加上指定的后缀
name_list = [\'jason\', \'kevin\', \'oscar\', \'tony\', \'jerry\']
name_list = [name + \'NB\' for name in name_list if name == \'jason\']
print(name_list) # [\'jasonNB\']
3.在name !== \'jerry\'的情况下,如果name == \'jason\',打印\'大佬\',其他的打印小赤佬
name_list = [\'jason\', \'kevin\', \'oscar\', \'tony\', \'jerry\']
new_list = [\'大佬\' if name == \'jason\' else \'小赤佬\' for name in name_list if name != \'jerry\']
print(new_list) # [\'大佬\', \'小赤佬\', \'小赤佬\', \'小赤佬\']
"""
列表生成式内的变量使用完会即刻销毁,在生成式外使用会直接报错:
a = [b for b in range(3)]
print(b) # 报错
"""
4.字典生成式
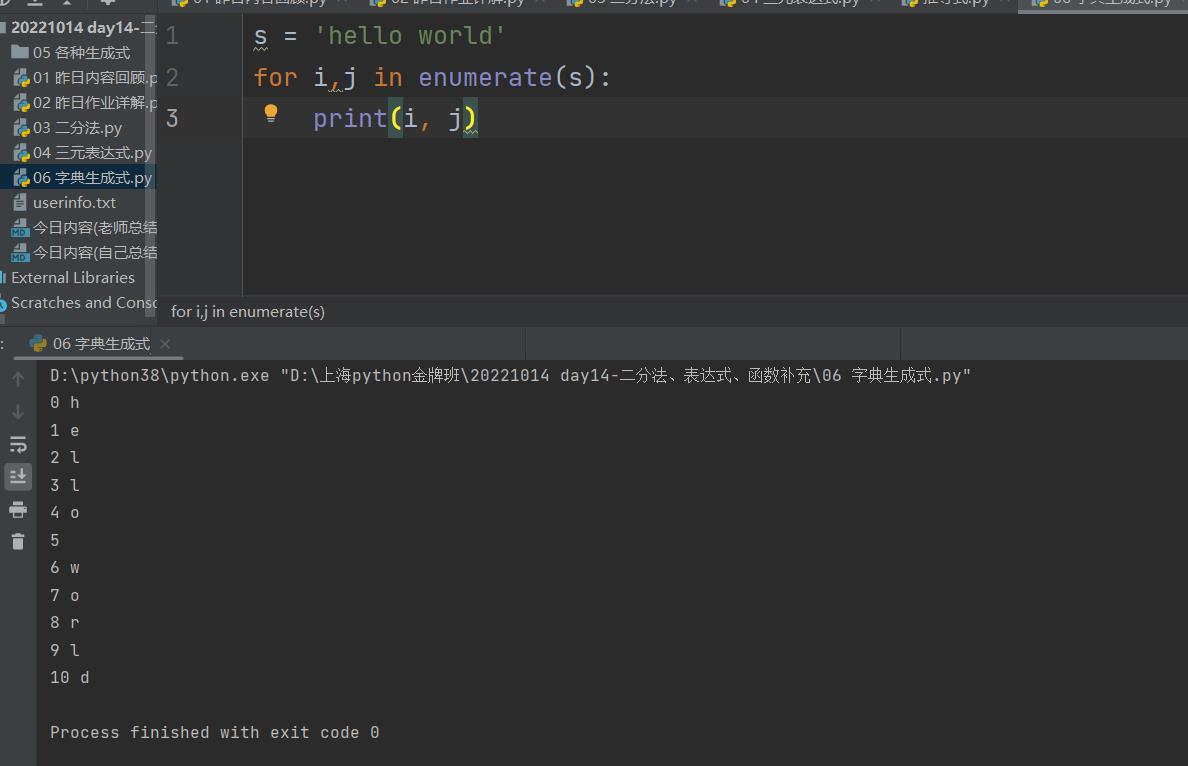
1.enumerate()中添加数据类型可以进行for循环,打印这两个数据发现是索引值和数据的元素。
s = \'hello world\'
for i,j in enumerate(s):
print(i, j)
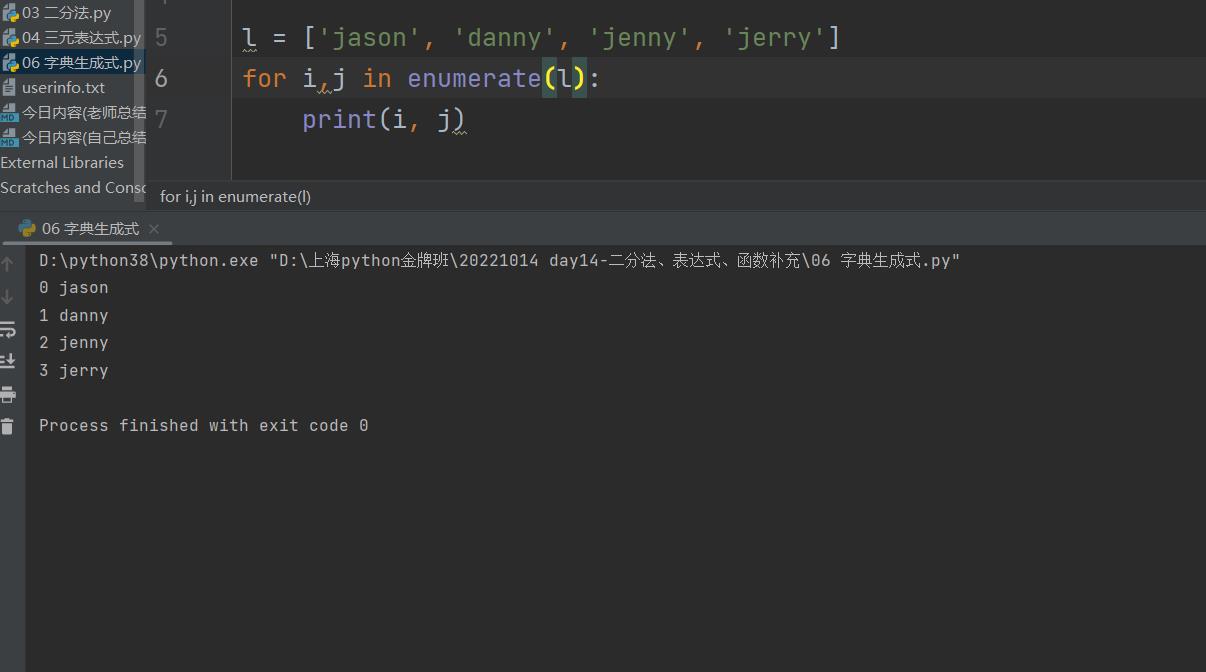
l = [\'jason\', \'danny\', \'jenny\', \'jerry\']
for i,j in enumerate(l):
print(i, j)
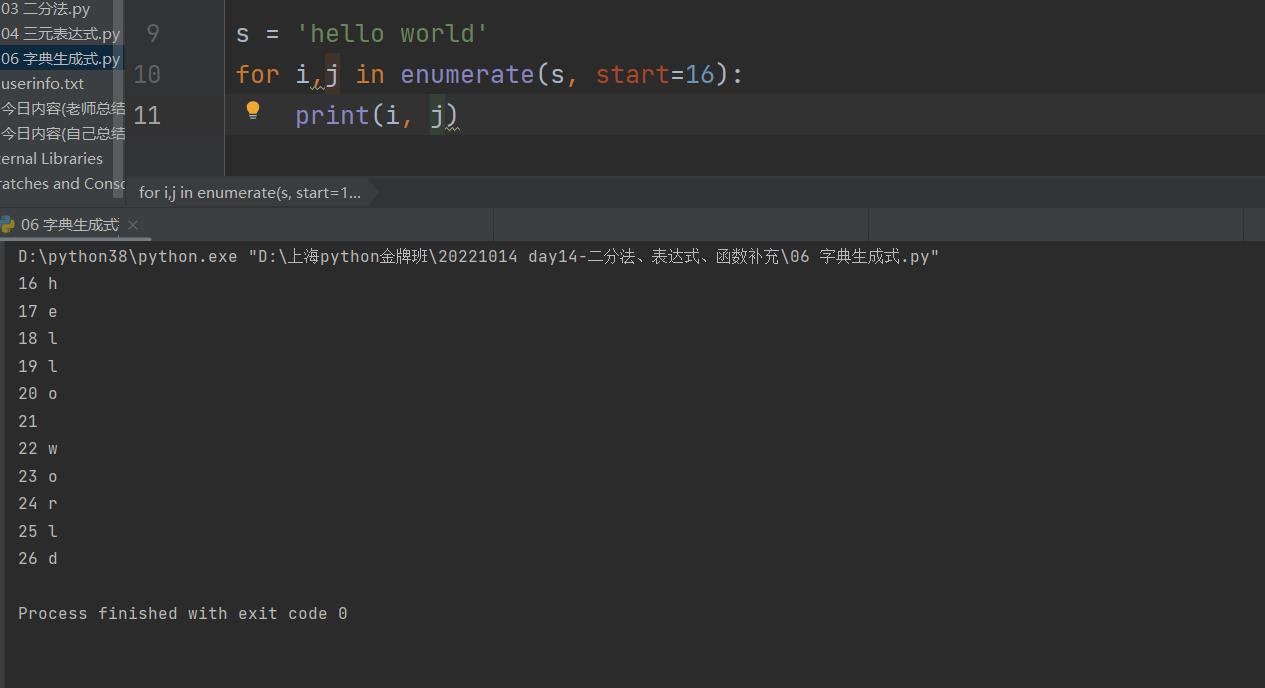
"""也可以指定起始位数"""
s = \'hello world\'
for i,j in enumerate(s, start=16):
print(i, j)
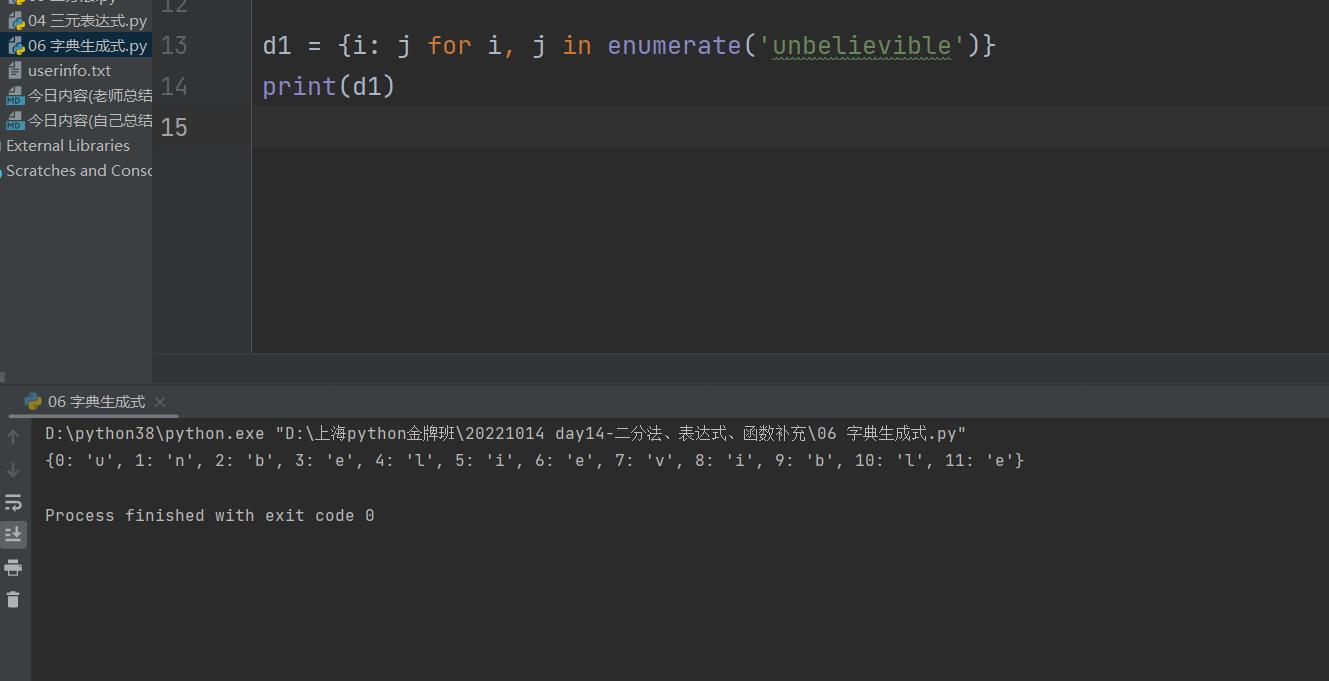
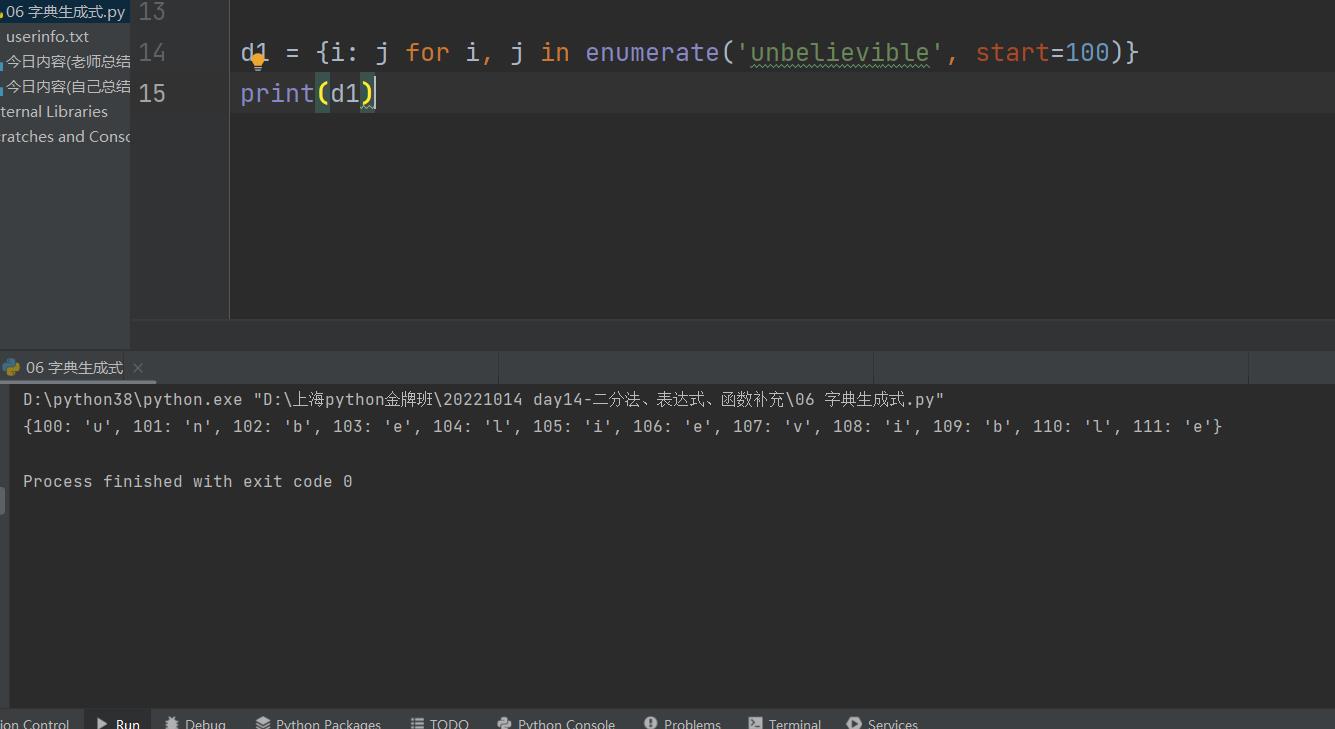
2.也可以放在字典中,构成一个字典
d1 = i: j for i, j in enumerate(\'unbelievible\')
print(d1) # 0: \'u\', 1: \'n\', 2: \'b\', 3: \'e\', 4: \'l\', 5: \'i\', 6: \'e\', 7: \'v\', 8: \'i\', 9: \'b\', 10: \'l\', 11: \'e\'
"""
也可以指定起始位数
"""
d1 = i: j for i, j in enumerate(\'unbelievible\', start=100)
print(d1)
5.集合生成式
集合属性:去重、无序
res = i for i in \'hello\'
print(res) # \'l\', \'h\', \'o\', \'e\'
6.匿名函数
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a,b:a+b
匿名函数一般不单独使用 需要配合其他函数一起用
7.常见的内置函数
1.map() 映射
"""
map不改原数据类型,而是形成一个新的列表,所以打印的时候要用print(list())
"""
l1 = [1, 2, 3, 4, 5]
res = map(lambda x:x+1, l1)
print(list(res)) # [2, 3, 4, 5, 6]
或列表生成式也可以达到目的:
l1 = [1, 2, 3, 4, 5]
l1 = [i + 1 for i in l1]
print(l1) # [2, 3, 4, 5, 6]
res = map(lambda x, y: (x - y, x + y), [4, 5, 6], [1, 3, 2])
print(list(res)) # [(3, 5), (2, 8), (4, 8)]
res = map(lambda x, y: x + y, [1, 2, 3, 4], [4, 8, 2, 4])
print(list(res)) # [5, 10, 5, 8]
\'\'\'
map还可以转化数据类型,并返回一个列表
\'\'\'
res = map(int, 1,2,3,4)
print(list(res)) # [1, 2, 3, 4]
2.max()\\min()
2.1 求列表l1 = [11, 36, 32, 82, 5, 78, 236, 893, 567]的最大值
方法1:用for循环求出列表的最大值:
l2 = []
l1 = [11, 36, 32, 82, 5, 78, 236, 893, 567]
l2.append(l1[0])
for i in l1:
if i > l2[0]:
l2.append(i)
del l2[0]
print(l2[0]) # 893
方法2:用max()
l1 = [11, 36, 32, 82, 5, 78, 236, 893, 567]
print(max(l1)) # 893
2.2 找出薪资最高的人并返回:
dict =
\'jason\': 100000,
\'jerry\': 5000,
\'oscar\': 10000,
\'kitty\': 20000
方法1:
dict =
\'jason\': 100000,
\'jerry\': 5000,
\'oscar\': 10000,
\'kitty\': 20000
def index(a):
return dict.get(a)
res = max(dict, key=index) # 传了函数修改了比较的依据,如果不传则会按照字符编码顺序比较
print(res) # jason
方法2:
res = max(dict, key=lambda k : dict.get(k))
print(res) # jason
for循环只会遍历字典的键,字典的键是字母开头,只能根据ASCII字符编码的顺序来比较,其中A-Z位数为:65-90,a-z位数为 97-122,
2.3如果可迭代对象为空,max()函数应该采用default参数
l1 = []
print(max(l1,default=-1)) # -1
3.reduce()函数:python3中需要从模块中调用,python2中可以直接调用。化多为一,lambda定义一个函数,reduce()按照定义的函数计算一个结果
from functools import reduce
l1 = [11, 36, 32, 82, 5, 78, 236, 893, 567]
res = reduce(lambda a, b : a * b, l1)
print(res) # 48425057425704960
from functools import reduce
l1 = [11, 36, 32, 82, 5, 78, 236, 893, 567]
res = reduce(lambda a, b: a + b, l1)
print(res) # 1940
作业
\'\'\'
1.先编写校验用户身份的装饰器
2.然后再考虑如何保存用户登录状态
3.再完善各种需求
\'\'\'
user_data =
\'1\': \'name\': \'jason\', \'pwd\': \'123\', \'access\': [\'1\', \'2\', \'3\'],
\'2\': \'name\': \'kevin\', \'pwd\': \'321\', \'access\': [\'1\', \'2\'],
\'3\': \'name\': \'oscar\', \'pwd\': \'222\', \'access\': [\'1\']
def login_auth(mode):
def outer(func):
def inner(*args, **kwargs):
user_name = input(\'请输入您的用户名>>>:\').strip()
user_pwd = input(\'请输入您的密码>>>:\').strip()
if mode == \'1\':
for data in user_data: # data: \'1\', \'2\', \'3\'
name1 = user_data.get(data).get(\'name\')
pwd1 = user_data.get(data).get(\'pwd\')
if user_name == name1 and user_pwd == pwd1:
print(\'登陆成功\')
res = func(*args, **kwargs)
return res
else:
print(\'登陆失败\')
elif mode == \'2\':
if user_name == user_data.get(\'1\').get(\'name\') and user_pwd ==user_data.get(\'1\').get(\'pwd\') or user_name == user_data.get(\'2\').get(\'name\') and user_pwd ==user_data.get(\'2\').get(\'pwd\'):
print(\'登陆成功\')
is_login = True
res = func(*args, **kwargs)
return res
elif user_name == user_data.get(\'3\').get(\'name\'):
print(\'您无权执行此操作\')
else:
print(\'用户名或密码错误\')
elif mode == \'3\':
if user_name == \'jason\' and user_pwd == \'123\':
print(\'登陆成功\')
is_login = True
res = func(*args, **kwargs)
return res
elif user_name == user_data.get(\'2\').get(\'name\') or user_name == user_data.get(\'3\').get(\'name\'):
print(\'您无权执行此操作\')
else:
print(\'登陆失败\')
return inner
return outer
@login_auth(\'1\')
def func1():
print(\'from func1\')
@login_auth(\'2\')
def func2():
print(\'from func2\')
@login_auth(\'3\')
def func3():
print(\'from func3\')
func_dict = \'1\':func1,
\'2\':func2,
\'3\':func3,
while True:
print(\'1\'
\'2\'
\'3\')
choice = input(\'请输入想要执行的编号\')
func_dict.get(choice)()
递归/匿名函数/三元表达式/列表生成式/字典生成式/二分算法
让在下揭开尔等的面纱,一探究竟:)
>>>递归:
递归是一个往复的过程,也就是由两个过程组成,一个是计算过程,一个是将值层层返回的过程,递归的奇妙之处,就在于自身调用自身,然后,过程遵循由复杂到简单,最终满足相应条件后,退出,返回结果.说了一大堆,不过直接上代码:
test_list = [1,[2,[3,[4,[5,[6,[7,[8,[9,[10,[11,[12,[13,[14,]]]]]]]]]]]]]] res = 0 def sum_list(test_list, res): for i in test_list: if type(i) == int: res += i if len(test_list) == 1: return res else: return sum_list(i,res) print(sum_list(test_list,res))
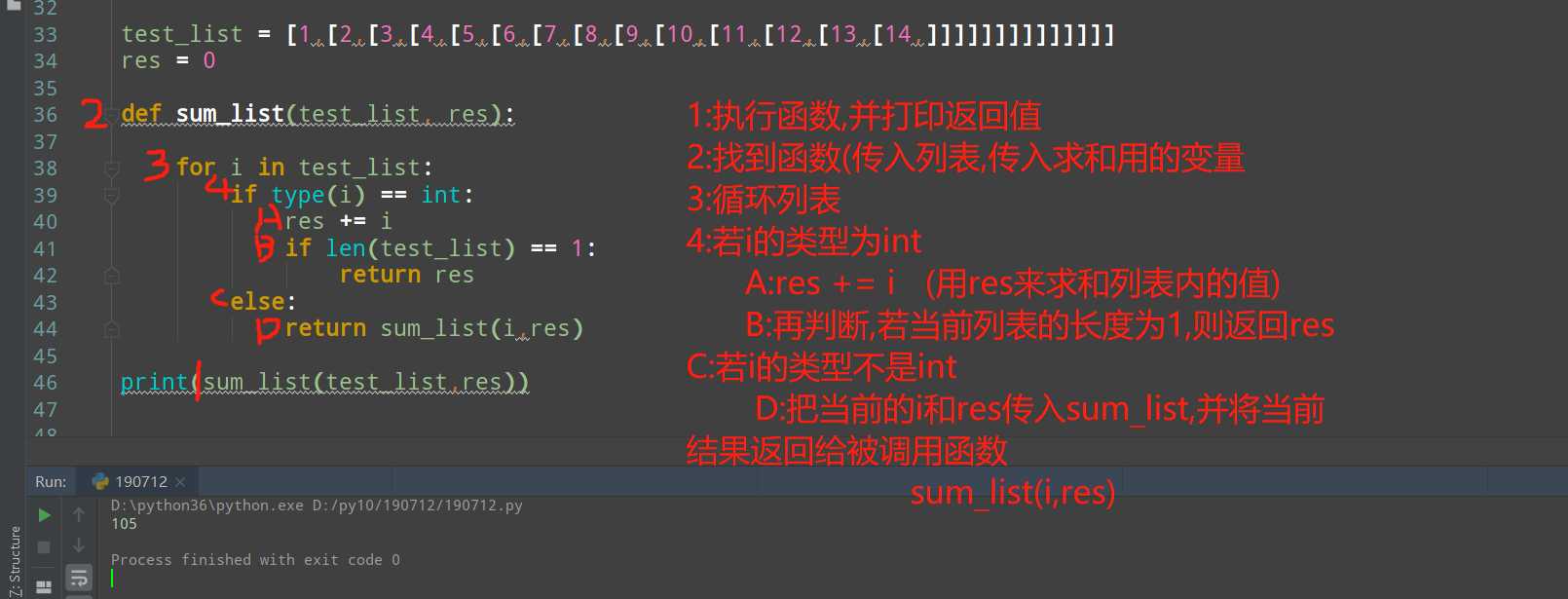
图中步骤D,请格外注意,若缺少,则导致最终结果无法返回.
>>>匿名函数:
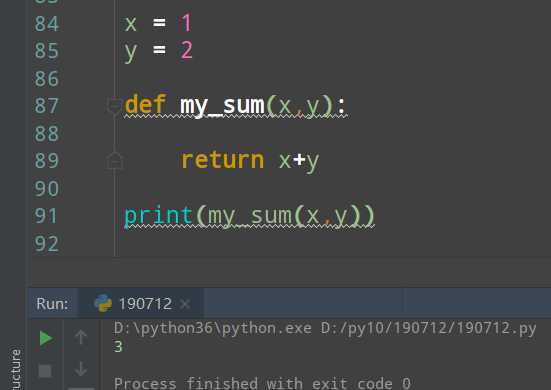
匿名函数的定义是:因为没有名字,所以不能被调用,在A处使用,就在A处编写,然后在A处执行,执行完毕返回结果后自动销毁.
x = 1 y = 2 def my_sum(x,y): return x+y
print(my_sum()) #下面这行代码的功能等价于上面的函数 print((lambda x,y:x+y)(x,y))
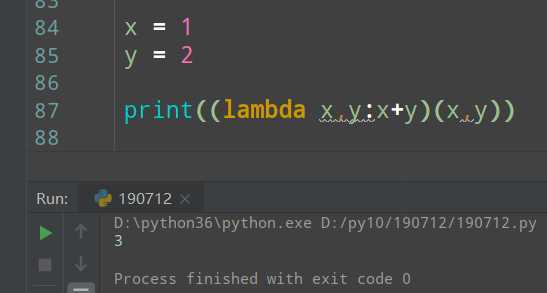
lambda一般和内置函数或自定义函数配合使用.
>>>三元表达式
三元表达式,比较简单粗暴.建议不要多个三元表达式嵌套在一起,因为会导致代码不易被阅读.
x = 1 y = 2 print(x if x > y else y) #如果x > y,则返回结果是x,否则返回y.在做简单判断时,非常实用.
>>>列表生成式
列表生成式,可以快速生成一个列表,也可以快速对一个列表的内容进行修改
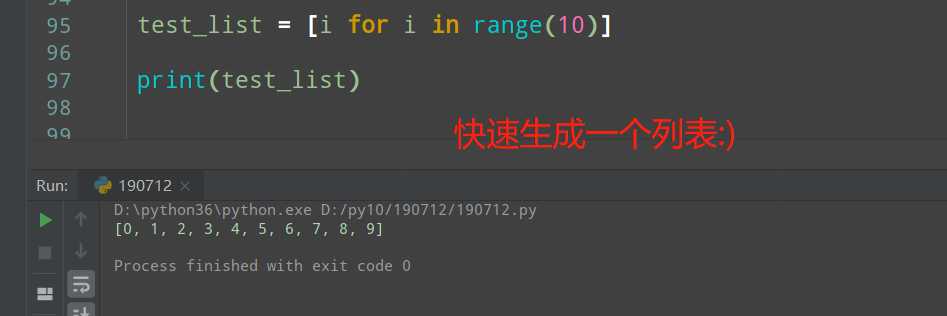
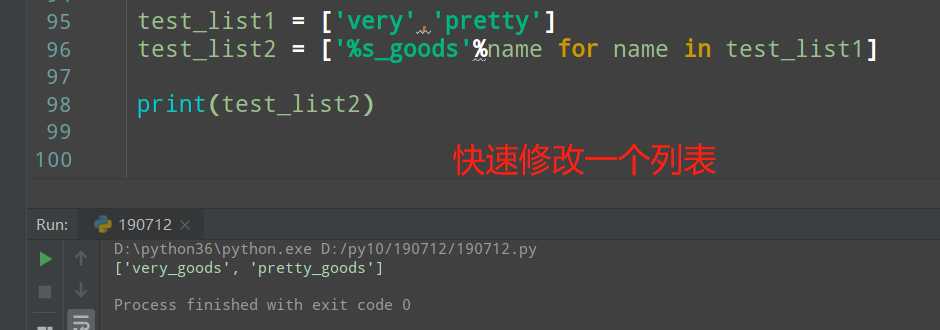
>>>字典生成式
字典生成式,可以快速生成一个字典,也可以快速对一个字典的内容进行修改
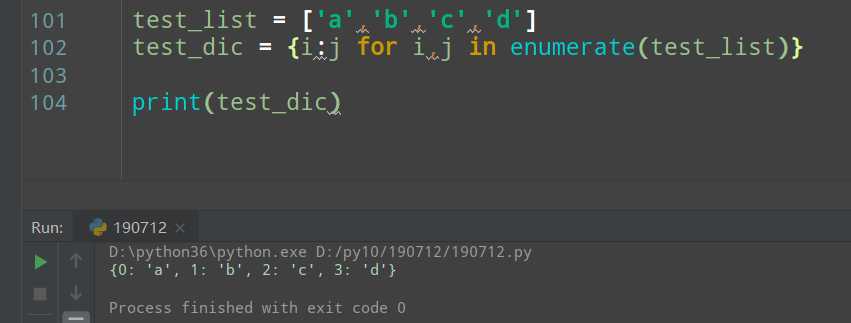
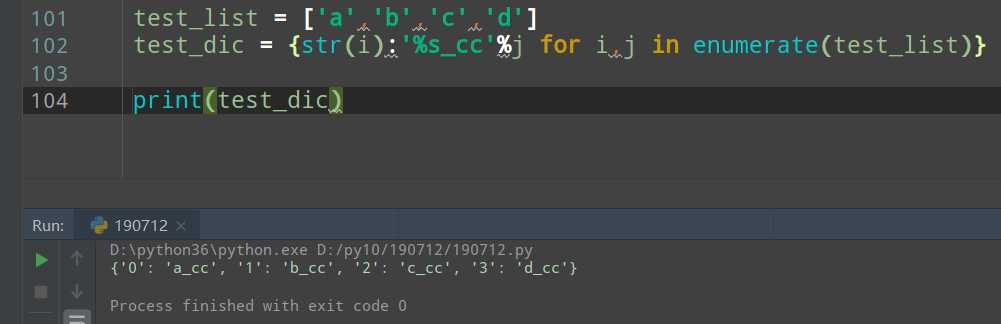
>>>二分算法
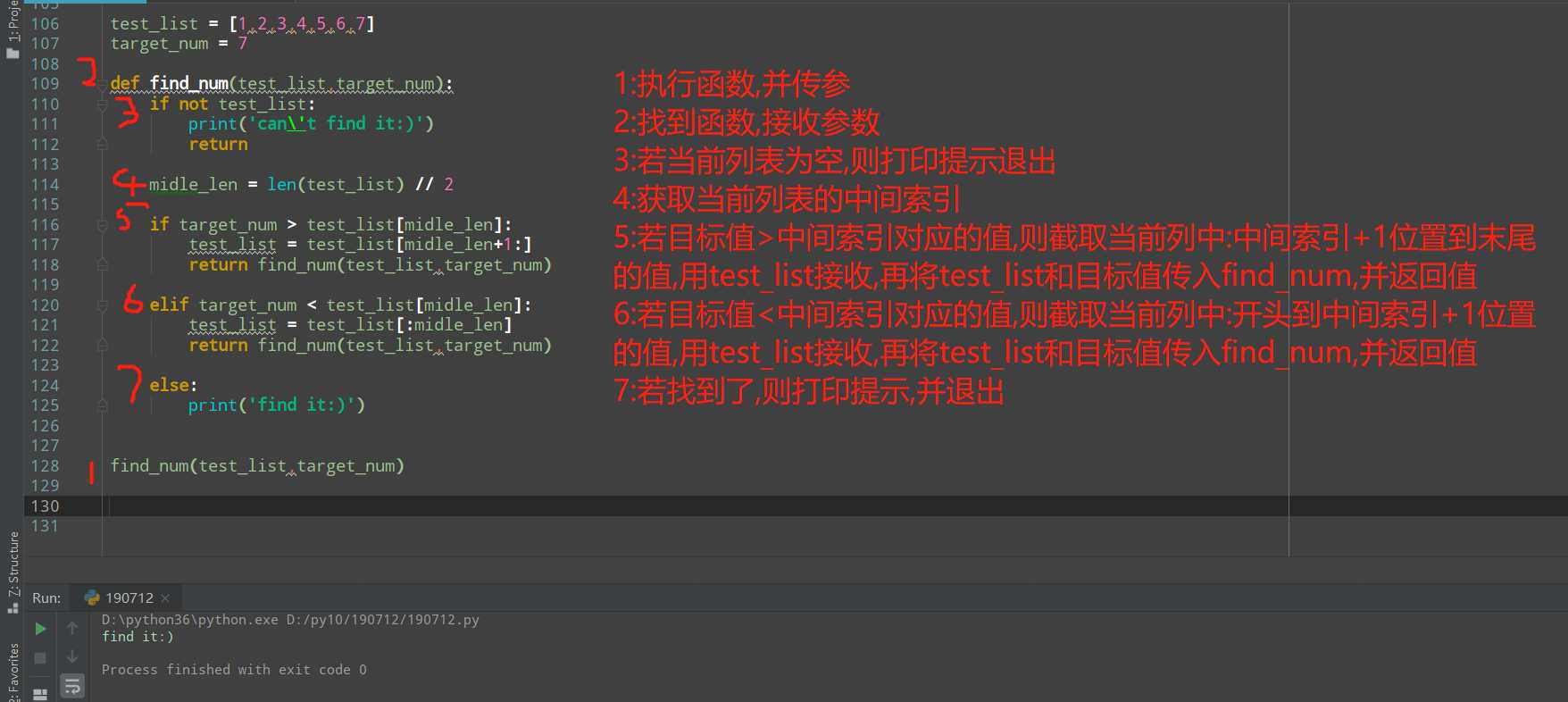
首先若要使用二分算法,列表必须是有序的.其原理,就是将事物细分在细分的结果中和目标值进行比对,从而实现对目标值的查找.且效率相对较高.
现有列表
test_liset = [1,2,3,4,5,6,7]
如果想确定4是不是在列表里,如果用for循环去将列表中的元素取出,再进行比较,找是同样可以找到,但是需要经历4次比较.
而使用二分算法,就不一样了,1次搞定,他每次都会取列表中间位置的值与目标值进行比较,然后根据结果,截取当前列表的不同区间,然后再用中间位置的值与目标值比较,直至列表内的值都比较完.
生命不息,学习不止:)
以上是关于算法表达式生成器的主要内容,如果未能解决你的问题,请参考以下文章