python爬虫框架scrapy初试(二点一)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫框架scrapy初试(二点一)相关的知识,希望对你有一定的参考价值。
功能:爬取某网站部分新闻列表和对应的详细内容。
列表页面http://www.zaobao.com/special/report/politic/fincrisis
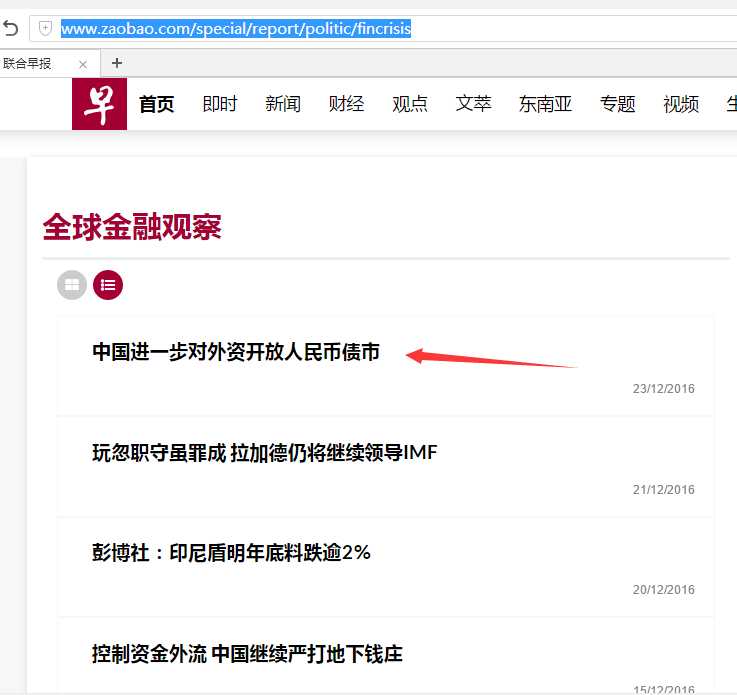
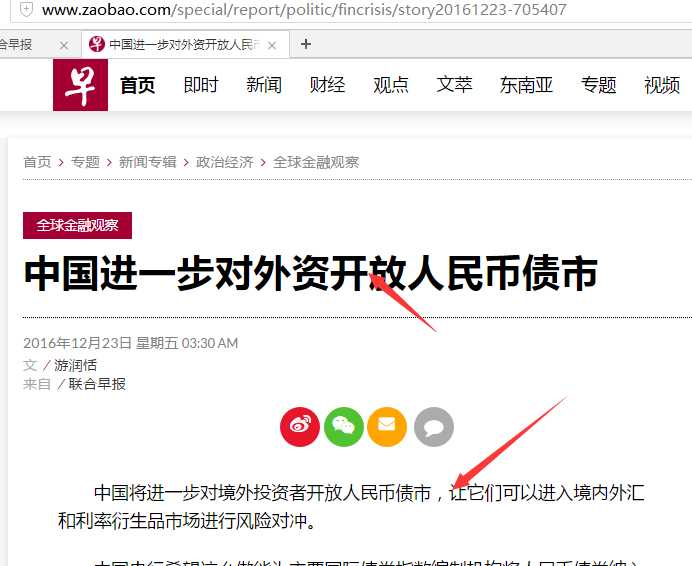
实现代码:
import scrapy
class ZaobaoSpider(scrapy.Spider):
name = ‘zaobao‘
start_urls=["http://www.zaobao.com/special/report/politic/fincrisis"]
def parse(self,response):
for href in response.xpath(‘//*[@id="DressUp"]/div[2]/div[1]/div/div/div/a/@href‘):
full_url = response.urljoin(href.extract())
yield scrapy.Request(full_url,callback=self.parse_news) #将列表url返回给parse_news函数进行详细爬取
def parse_news(self,response):
yield {
‘title‘:response.xpath(‘//*[@id="MainCourse"]/div/h1‘).extract(),‘body‘:response.xpath(‘//*[@id="FineDining"]‘).extract(),
‘link‘:response.url
}
运行方法:
scrapy runspider zao.py -o ac.csv #-o 输出为文件,保存格式为csv格式
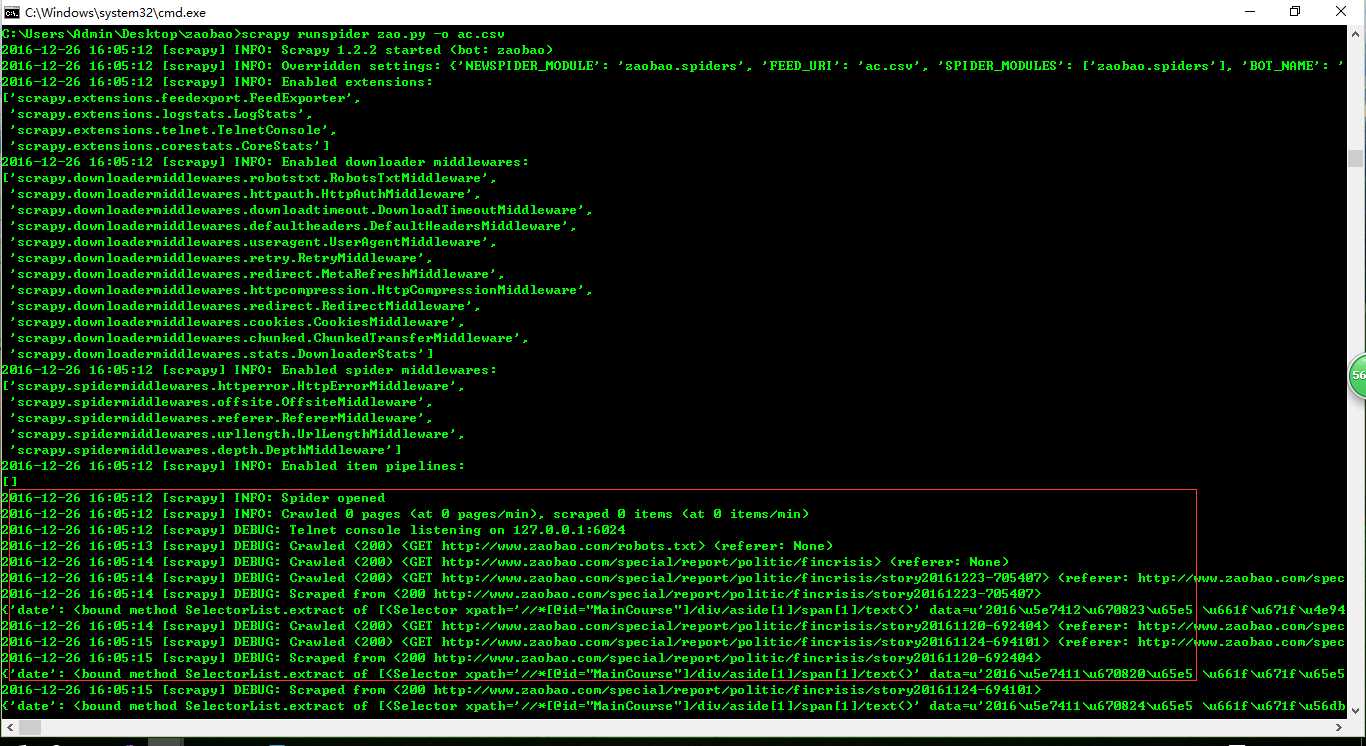
结果:
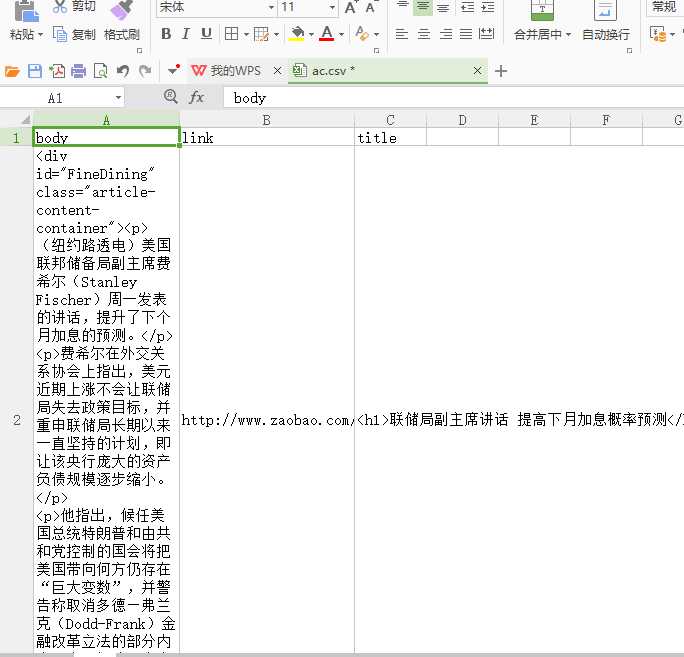
以上是关于python爬虫框架scrapy初试(二点一)的主要内容,如果未能解决你的问题,请参考以下文章