Python3红楼梦人名出现次数统计分析
Posted 诸子流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3红楼梦人名出现次数统计分析相关的知识,希望对你有一定的参考价值。
一、程序说明
本程序流程是读取红楼梦txt文件----使用jieba进行分词----借助Counter读取各人名出现次数并排序----使用matplotlib将结果可视化
这里的统计除了将“熙凤”出现的次数合并到“凤姐”中外并没有其他处理,但应该也大体能反映人物提及次数情况
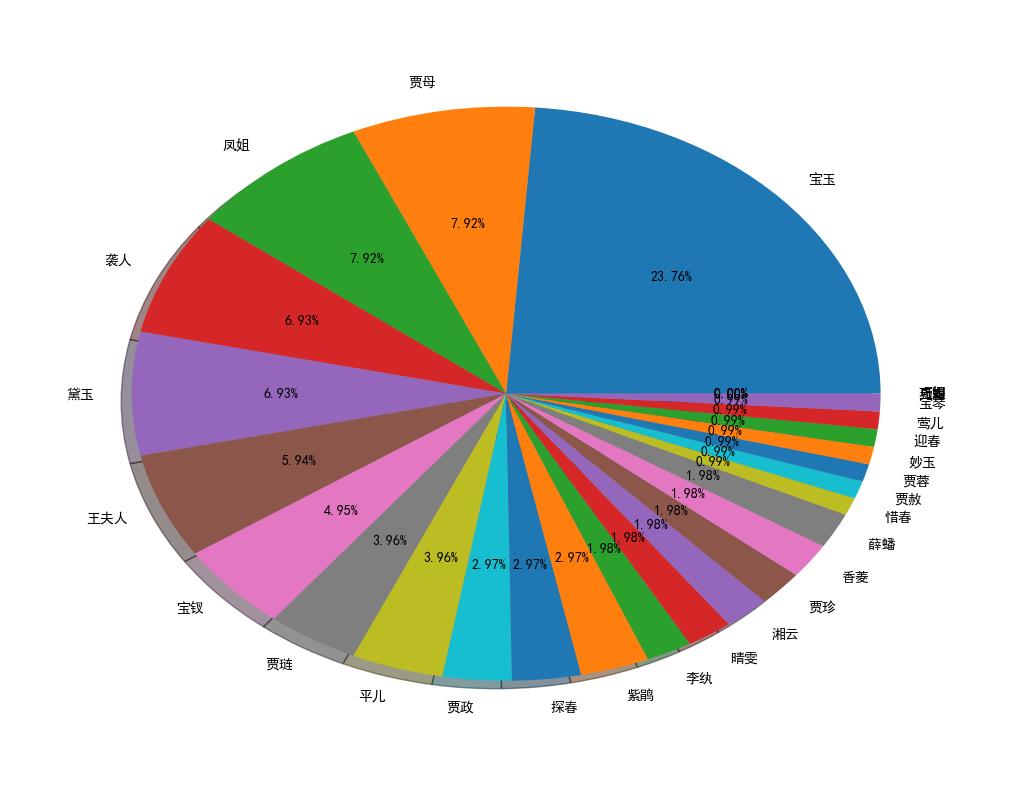
二、执行结果展示
条形图:

饼状图:
三、程序源代码
import jieba from collections import Counter import matplotlib.pyplot as plt import numpy as np class HlmNameCount(): # 此函数用于绘制条形图 def showNameBar(self,name_list_sort,name_list_count): # x代表条形数量 x = np.arange(len(name_list_sort)) # 处理中文乱码 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 绘制条形图,bars相当于句柄 bars = plt.bar(x,name_list_count) # 给各条形打上标签 plt.xticks(x,name_list_sort) # 显示各条形具体数量 i = 0 for bar in bars: plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), \'%d\' % name_list_count[i], ha=\'center\', va=\'bottom\') i += 1 # 显示图形 plt.show() # 此函数用于绘制饼状图 def showNamePie(self, name_list_sort, name_list_fracs): # 处理中文乱码 plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 绘制饼状图 plt.pie(name_list_fracs, labels=name_list_sort, autopct=\'%1.2f%%\', shadow=True) # 显示图形 plt.show() def getNameTimesSort(self,name_list,txt_path): # 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名 for k in name_list: jieba.add_word(k) # 打开并读取txt文件 file_obj = open(txt_path, \'rb\').read() # jieba分词 jieba_cut = jieba.cut(file_obj) # Counter重新组装以方便读取 book_counter = Counter(jieba_cut) # 人名列表,因为要处理凤姐所以不直接用name_list name_dict ={} # 人名出现的总次数,用于后边计算百分比 name_total_count = 0 for k in name_list: if k == \'熙凤\': # 将熙凤出现的次数合并到凤姐 name_dict[\'凤姐\'] += book_counter[k] else: name_dict[k] = book_counter[k] name_total_count += book_counter[k] # Counter重新组装以使用most_common排序 name_counter = Counter(name_dict) # 按出现次数排序后的人名列表 name_list_sort = [] # 按出现次数排序后的人名百分比列表 name_list_fracs = [] # 按出现次数排序后的人名次数列表 name_list_count = [] for k,v in name_counter.most_common(): name_list_sort.append(k) name_list_fracs.append(round(v/name_total_count,2)*100) name_list_count.append(v) # print(k+\':\'+str(v)) # 绘制条形图 self.showNameBar(name_list_sort, name_list_count) # 绘制饼状图 self.showNamePie(name_list_sort,name_list_fracs) if __name__ == \'__main__\': # 参与统计的人名列表,可修改成自己想要的列表 name_list = [\'宝玉\', \'黛玉\', \'宝钗\', \'元春\', \'探春\', \'湘云\', \'妙玉\', \'迎春\', \'惜春\', \'凤姐\', \'熙凤\', \'巧姐\', \'李纨\', \'可卿\', \'贾母\', \'贾珍\', \'贾蓉\', \'贾赦\', \'贾政\', \'王夫人\', \'贾琏\', \'薛蟠\', \'香菱\', \'宝琴\', \'袭人\', \'晴雯\', \'平儿\', \'紫鹃\', \'莺儿\'] # 红楼梦txt文件所在路径,修改成自己文件所在路径 txt_path = \'F:/PycharmProjects/tutorial/hlm.txt\' hnc = HlmNameCount() hnc.getNameTimesSort(name_list,txt_path)
参考:
https://github.com/fxsjy/jieba
https://docs.python.org/3/library/collections.html#collections.Counter
以上是关于Python3红楼梦人名出现次数统计分析的主要内容,如果未能解决你的问题,请参考以下文章