Python — pandas
Posted 深度机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python — pandas相关的知识,希望对你有一定的参考价值。
Pandas有两种数据结构:Series和DataFrame。
1、Series
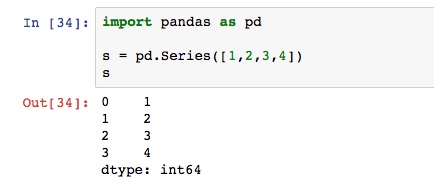
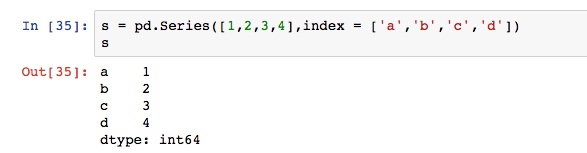
Series类似于一维数组,和numpy的array接近,由一组数据和数据标签组成。数据标签有索引的作用。数据标签是pandas区分于numpy的重要特征。索引不一定是从0开始的数字,它可以被定义。
Series有自动对齐索引的功能,当自定义的索引qinqin和字典队员不上时,会自动选择NaN,即结果为空,表示缺失。缺失值的处理会在后续讲解。
2、DataFrame
Series是一维的数据结构,DataFrame是一个表格型的数据结构,它含有不同的列,每列都是不同的数据类型。我们可以把DataFrame看作Series组成的字典,它既有行索引也有列索引。想象得更明白一点,它类似一张excel表格或者SQL,只是功能更强大。
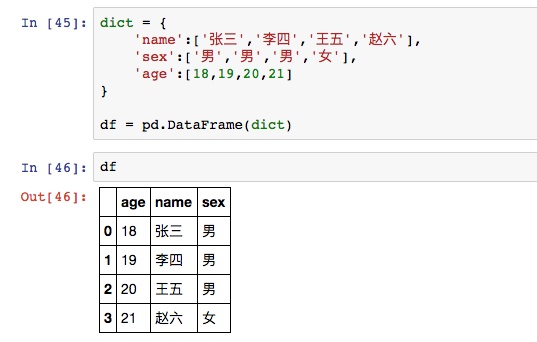
在构建DataFrame时,最最最常用的就是先创建一个data,data一般可以是字典和数组,再用a=DataFrame(data)来转换为DataFrame结构。在DataFrame(data)时也可以同时传入index和columns参数,两个参数必须是列表型。
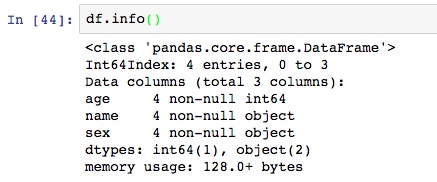
DataFrame中可以通过info函数直接查看数据类型和统计。列名后面是列的非空值统计量,以及数据类型,最后一行是DataFrame占用的内存大小,对于pandas来说,千万行几百兆的数据也是不再话下的。
1).构建DataFrame最常见的方法是传入一个由等长列表或数组组成的字典: 例如: data={ \'name\':[\'bon\',\'kate\',\'jun\',\'sam\'], \'stature\':[\'102\',\'112\',\'136\',\'90\'], \'grade\':[\'70\',\'76\',\'98\',\'88\'] } frame=DataFrame(data) DataFrame会自动加上索引,得到的结果为: name stature grade 0 bon 102 70 1 kate 112 76 2 jun 136 98 3 sam 90 88 2).也可以为DataFrame指定索引 frame2=DataFrame(data,columns=[\'name\',\'grade\',\'stature\',\'birthdate\'], index=[\'one\',\'two\',\'three\',\'four\']) 跟Series中一样若在对应的列中找不到数据,就会产生缺失值NaN. name grade stature birthdate one bon 70 102 NaN two kate 76 112 NaN three jun 98 136 NaN four sam 88 90 NaN 3).取值和赋值 查看列:可用类似字典的方式获取一个Series(即一个列的值),如:frame2[\'name\']; 查看行:可用索引字段ix来获取某行的值,如:frame2.ix[\'three\']; 可用frame2[\'birthdate\']=1990来直接对某一列进行赋值; 4).删除某一列的值 del frame2[\'name\'] 5)将嵌套型字典转化为DataFrame型时,外层的键作为列,内层的键作为行索引 例如: data={ \'newyork\':{\'2001\':51,\'2002\':76}, \'houston\':{\'2001\':49,\'2002\':90}, } DataFrame(data)得到结果为: newyork houston 2001 51 49
2002 76 90
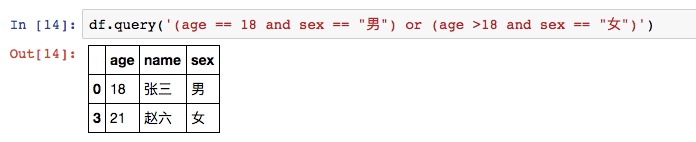
pandas中可以用query函数以类SQL语言执行查询。query中可以直接使用列名。
以上是关于Python — pandas的主要内容,如果未能解决你的问题,请参考以下文章