Python—文件
Posted 王陸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python—文件相关的知识,希望对你有一定的参考价值。
1 def fileCopy(src, dst, srcEncoding, dstEncoding): 2 with open(src, \'r\', encoding=srcEncoding) as srcfp: 3 with open(dst, \'w\', encoding=dstEncoding) as dstfp: 4 dstfp.write(srcfp.read()) 5 fileCopy(\'sample.txt\', \'sample_new.txt\', \'cp936\', \'utf8\')
一.文件基础和基本操作。
1.什么是文件?
为了长期保存数据以便重复使用、修改和共享,必须将数据以文件的形式存储到外部存储介质(如磁盘、U盘、光盘等)或云盘中。
文件:存储在外部介质上的数据或信息的集合 。
程序中的源程序 数据中保存着数据 图像中的像素数据 …
有序的数据序列。
2.文件中的编码
文本显示:计算机显示功能的基本问题
编码:信息从一种形式转换为另一种形式的过程
列如:ASCII码、Unicode、UTF-8…
3.常用的编码
ASCII码:是标准化字符集 7个二进制位编码,表示128个字符, ord()和chr()函数查看
Unicode:跨语言、 跨平台进行文本转换和处理,对每种语言中字符设定统一且唯一的二进制编码,每个字符两个字节长 65536 个字符的编码空间,“ 严” :Unicode的十六进制数为4E25
UTF-8编码:可变长度的Unicode的实现方式 ,“ 严” :十六进制数为E4B8A5Unicode
GBK编码 :《汉字内码扩展规范》 双字节编码
Python中字符串类型未编码 编码encode() 解码decode()

4.文件的分类:
按文件中数据的组织形式把文件分为文本文件和二进制文件
a.文本文件
文本文件存储的是常规字符串,以ASCII码方式存储。如英文字母、汉字、数字字符串。由若干文本行组成,通常每行以换行符\'\\n\'结尾。文本文件可以使用字处理软件如gedit、记事本进行编辑。
b.二进制文件
二进制文件把对象内容以字节串(bytes)进行存储,无法用记事本或其他普通字处理软件直接进行编辑,通常也无法被人类直接阅读和理解,需要使用专门的软件进行解码后读取、显示、修改或执行。常见的如图形图像文件、音视频文件、可执行文件、资源文件、各种数据库文件、各类office文档等都属于二进制文件。
优点: 更加节省空间 采用二进制无格式存储 表示更为精确
注意:
文本文件是基于字符定长的ASCII;
二进制文件编码是变长的,灵活利用率要高;
不同的二进制文件解码方式是不同的。
5.文件的操作流程
a.打开文件
建立磁盘上的文件与程序中的对象相关联
通过相关的文件对象获得
b.文件操作
读取
写入
定位
其他:追加、 计算等
c.关闭文件
切断文件与程序的联系
写入磁盘,并释放文件缓冲区
6.文件的打开
文件对象名=open(文件名[, 打开方式[, 缓冲区]])
a.文件名:指定了被打开的文件名称。
b.打开模式:指定了打开文件后的处理方式,见表7-1。
c.缓冲区:指定了读写文件的缓存模式。0表示不缓存,1表示缓存,如大于1则表示缓冲区的大小。默认值是缓存模式。
d.open( )函数返回1个文件对象,该对象可以对文件进行各种操作。
例如: f1 = open( \'file1.txt\', \'r\' ) f2 = open( \'file2.txt\', \'w\')
文件打开模式:表7-1,例7-1 文件对象属性
7.文件的对象
文件的打开方式

文件对象属性

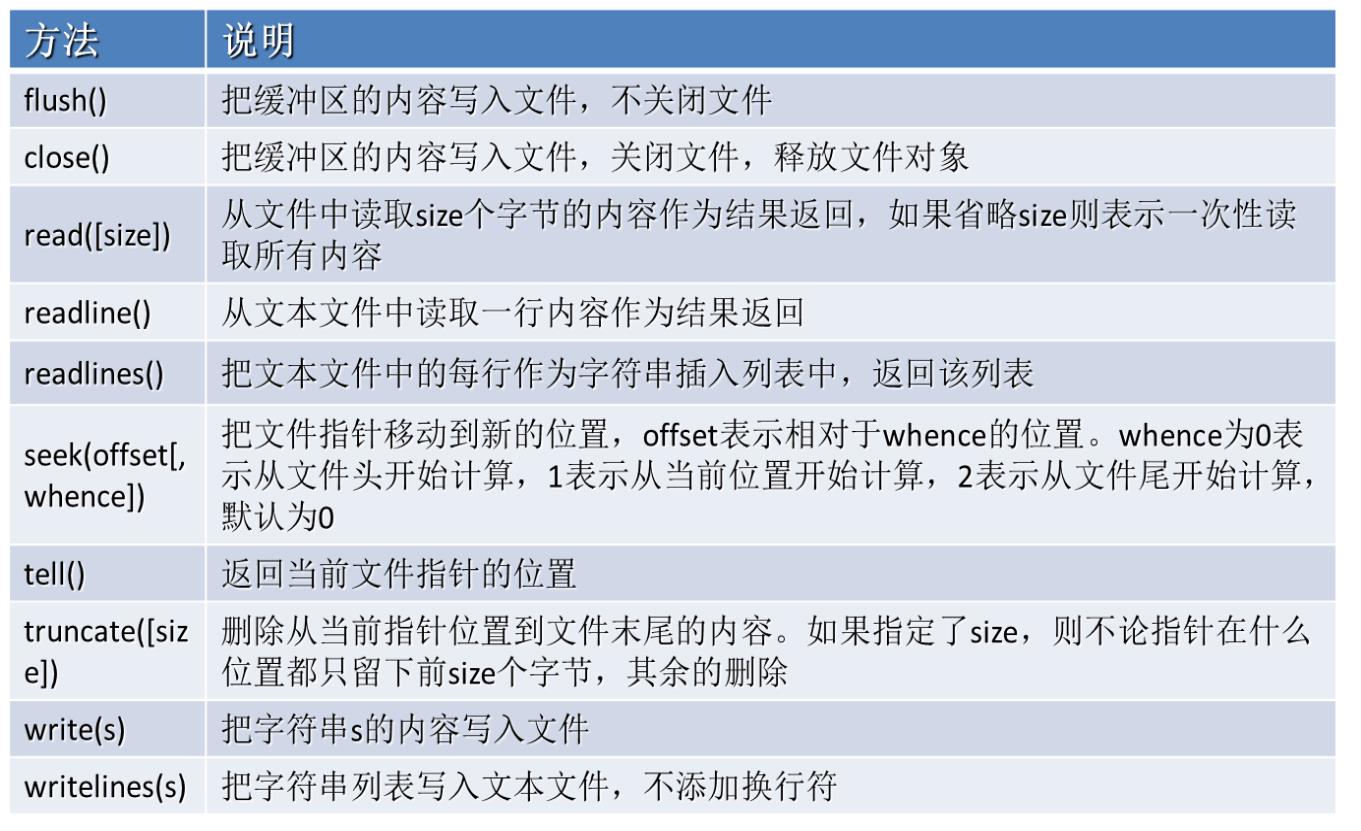
8.文件对象的常用方法(读写函数)
9.操作实例
a.向文本文件中写入内容
1 f=open(\'sample.txt\', \'a+\') 2 s= \'文本文件的读取方法\\n文本文件的写入方法\\n\' 3 f.write(s) 4 f.close()
更建议这样写:
1 s= \'文本文件的读取方法\\n文本文件的写入方法\\n\' 2 with open(\'sample.txt\',\'a+\') as f: 3 f.write(s)
使用with自动关闭资源。可以在代码块执行完毕后还原进入该代码块时的现场。 不论何种原因跳出with块,总能保证文件被正确关闭。
在实际开发中,读写文件应优先考虑使用上下文管理语句with,关键字with可以自动管理资源,可以在代码块执行完毕后自动还原进入该代码块时的上下文,常用于文件操作、数据库连接、网络连接、多线程与多进程同步时的锁对象管理等场合。
with open(filename, mode, encoding) as fp: #这里写通过文件对象fp读写文件内容的语句
上下文管理语句with还支持下面的用法:
1 with open(\'test.txt\', \'r\') as src, open(\'test_new.txt\', \'w\') as dst:#读写合并 2 dst.write(src.read())
b.随机产生10个数并写入文件中
1 import random 2 alist=[random.randint(1,100) for i in range(10)] 3 data=[str(i)+\'\\n\' for i in alist] 4 with open(r\'D:\\data.txt\',\'w\') as fp: 5 fp.writelines(data)
c.读取文本文件的前五个字符
1 f=open( \'sample.txt\', \'r\') 2 s=f.read(5) #读取文件的前5个字符 3 f.close( ) 4 print(\'s=\',s) 5 print(\'字符串s的长度(字符个数)=\', len(s))
d.读取并显示文本文件的所有行
1 f=open(r\'D:\\Zen.txt\', \'r\') 2 while True: 3 line=f.readline() 4 if line==\'\': 5 break 6 print(line) 7 f.close()
或者可以写成这样
1 f=open(r\'D:\\Zen.txt\', \'r\') 2 li=f.readlines() 3 for line in li: 4 print(line) 5 f.close()
e.将一个CP936编码格式的文本文件中的内容全部复制到另一个使用UTF8编码的文本文件中。
以上是关于Python—文件的主要内容,如果未能解决你的问题,请参考以下文章