python2.7 urllib2 爬虫
Posted 开源、架构、Linux C/C++/python AI BI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python2.7 urllib2 爬虫相关的知识,希望对你有一定的参考价值。
# _*_ coding:utf-8 _*_
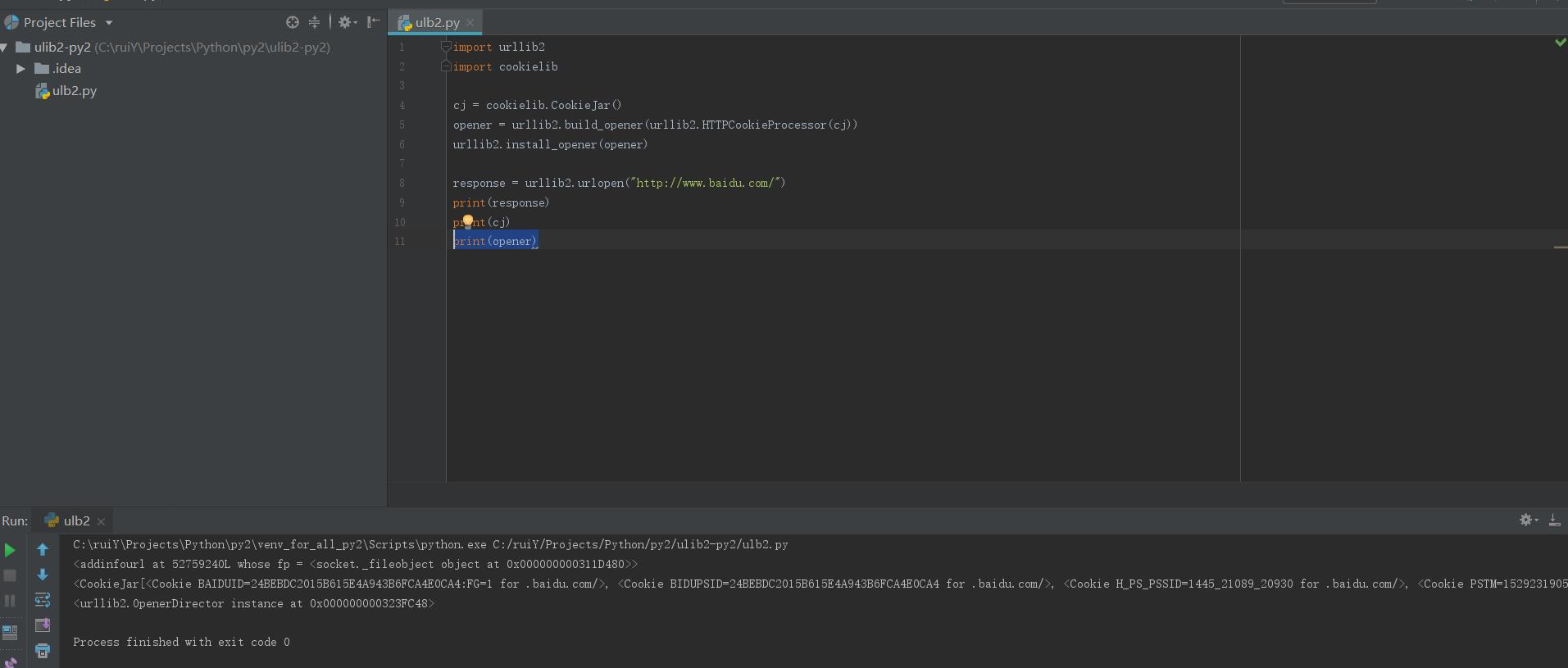
import urllib2
import cookielib
import random
import re
from bs4 import BeautifulSoup
import datetime
dax = datetime.datetime.now().strftime(\'%Y-%m-%d\')
print(dax)
url = \'http://ww=singlemessage&isappinstalled=0\'
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
request = urllib2.Request(url)
headers = [
\'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)\',
\'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)\',
\'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11\',
\'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0\',
\'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\'
]
hds = random.choice(headers)
# print(hds)
request.add_header(\'User-Agent\',\'%s\' % hds)
#response = urllib2.urlopen("http://www.hn1m=singlemessage&isappinstalled=0")
response = urllib2.urlopen(request)
cont = response.read()
#print(cont)
soup = BeautifulSoup(cont,\'html.parser\',from_encoding=\'utf-8\')
# print(soup)
# listyj = soup.find_all(\'dl\')
# for listyjx in listyj:
# print(listyjx.name,listyjx.attrs,listyjx.gettext())
# # if dax in listyjx:
# # print(listyjx)
以上是关于python2.7 urllib2 爬虫的主要内容,如果未能解决你的问题,请参考以下文章