python 斗图图片爬虫
Posted canmeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 斗图图片爬虫相关的知识,希望对你有一定的参考价值。
捣鼓了三小时,有一些小Bug,望大佬指导
废话不说,直接上代码:
#!/usr/bin/python3 # -*- coding:UTF-8 -*- import os,re,requests from urllib import request,parse class Doutu_api(object): def __init__(self): self.api_html = r‘http://www.doutula.com/search?keyword=%s‘ self.headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ‘ ‘(KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36‘} self.path = os.path.dirname(os.path.realpath(__file__))+‘\\temp‘ def make_path(self,path=‘‘):#返回假为已创建,否则创建新文件夹 self.path = self.path+‘\\‘+path if os.path.exists(self.path): # 判断文件夹是否存在 return False else: os.mkdir(self.path) # 创建文件夹 return True def get_img_html(self,html): self.make_path(path=html) html = self.api_html%parse.quote(html) pattern = re.compile(u‘<a.*?class="col-xs-6 col-md-2".*?href="(.*?)".*?style="padding:5px;">.*?</a>‘,re.S) pattern_img = re.compile(u‘<td>.*?<img.*?src="(.*?)".*?alt="(.*?)".*?onerror=".*?">.*?</td>‘,re.S) try: req = request.Request(html, headers=self.headers) imgs = request.urlopen(req) imgs = imgs.read().decode(‘utf-8‘) imgs = re.findall(pattern, imgs) for img in imgs: req = request.Request(img, headers=self.headers) imgurl = request.urlopen(req).read().decode(‘utf-8‘) imgurl =re.findall(pattern_img, imgurl) with open(self.path+‘\\{}.png‘.format(imgurl[0][1].replace(‘/‘,‘-‘)), ‘wb‘) as file: response = requests.get(imgurl[0][0]).content # 下载图片 file.write(response) # 读取图片 print(‘已完成下载,图片地址:‘,self.path) except Exception as e: print(e) return None doutu = Doutu_api() doutu.get_img_html(input(‘斗图内容关键字:‘))
测试成功
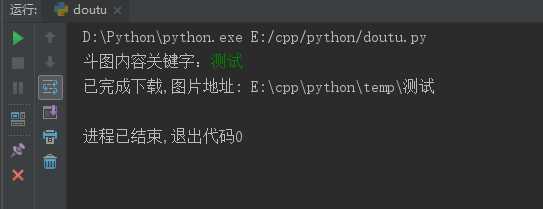
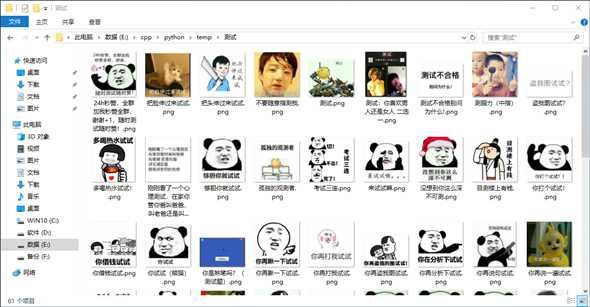
以上是关于python 斗图图片爬虫的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫入门教程 13-100 斗图啦表情包多线程爬取
斗图斗不过小伙伴?python多线程爬取斗图网表情包,助你成为斗图帝!