python基础07
Posted 水无
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python基础07相关的知识,希望对你有一定的参考价值。
Python基础学习07-模块
模块
一、模块基础
1、定义
模块:用来从逻辑上组织python代码(变量、函数、类、逻辑:目的是实现一个功能 ),本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test)
包:用来从逻辑上组织模块的,本质就是一个目录(必须带有一个__init__.py的文件)
2、导入方法
import module_name (导入一个模块)
import module_name_1,module_name_2(导入多个模块用逗号分隔)
from module_name import * (导入模块内的全部方法、变量、函数)
from module_name import logger as logger_module (当导入模块中的函数或变量与本模块中的函数或变量冲突时用as重命名)
3、import的本质:
import 模块的本质:
import module_name 其本质是:将module_name.py文件解释运行了一遍,并把这个模块运行的结果赋值给了module_name这个变量
from module_name import x 其本质是:将 module_name.py中的代码里的x变量,放到了当前位置,执行了一遍
导入模块的本质就是找到模块并把python文件解释一遍
import module_name,一定要找到一个名为module_name.py的文件,找文件一定要知道文件夹路径(一般默认查找:当前路径、sys.path)
import os
os.path.abspath(__file__) #获取当前文件的绝对路径
os.path.dirname(os.path.abspath(__file__)) #获取当前文件的目录名
os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #获取上一级目录名
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #追加到环境变量列表的结尾
import 包的本质:
导入包的本质就是找到包执行该包下的__init__.py文件
import package #相当于run __init__.py 因此若想导入一个包下的模块,需要修改这个包的__init__.py文件
#在__init__.py文件中from . import module_name
模块的分类:
a、标准库:内置模块,python解释器自带,拿过来就用
b、开源模块:第三方模块
c、自定义模块:自己定义的模块
二、内置模块
1、time与datetime模块
在Python中,通常有这几种方式来表示时间:
a、格式化的时间字符串(Format String)
b、时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
c、结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)


1 import time 2 print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:2018-05-24 20:48:10 3 print(time.time()) # 时间戳:1527166090.1953392 4 print(time.localtime()) #本地时区的struct_time:time.struct_time(tm_year=2018, tm_mon=5, tm_mday=24, tm_hour=20, tm_min=48, tm_sec=10, tm_wday=3, tm_yday=144, tm_isdst=0) 5 print(time.gmtime()) #UTC时区的struct_time:time.struct_time(tm_year=2018, tm_mon=5, tm_mday=24, tm_hour=12, tm_min=48, tm_sec=10, tm_wday=3, tm_yday=144, tm_isdst=0)
1 %a Locale’s abbreviated weekday name. 2 %A Locale’s full weekday name. 3 %b Locale’s abbreviated month name. 4 %B Locale’s full month name. 5 %c Locale’s appropriate date and time representation. 6 %d Day of the month as a decimal number [01,31]. 7 %H Hour (24-hour clock) as a decimal number [00,23]. 8 %I Hour (12-hour clock) as a decimal number [01,12]. 9 %j Day of the year as a decimal number [001,366]. 10 %m Month as a decimal number [01,12]. 11 %M Minute as a decimal number [00,59]. 12 %p Locale’s equivalent of either AM or PM. (1) 13 %S Second as a decimal number [00,61]. (2) 14 %U Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3) 15 %w Weekday as a decimal number [0(Sunday),6]. 16 %W Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3) 17 %x Locale’s appropriate date representation. 18 %X Locale’s appropriate time representation. 19 %y Year without century as a decimal number [00,99]. 20 %Y Year with century as a decimal number. 21 %z Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. 22 %Z Time zone name (no characters if no time zone exists). 23 %% A literal \'%\' character.
time模块
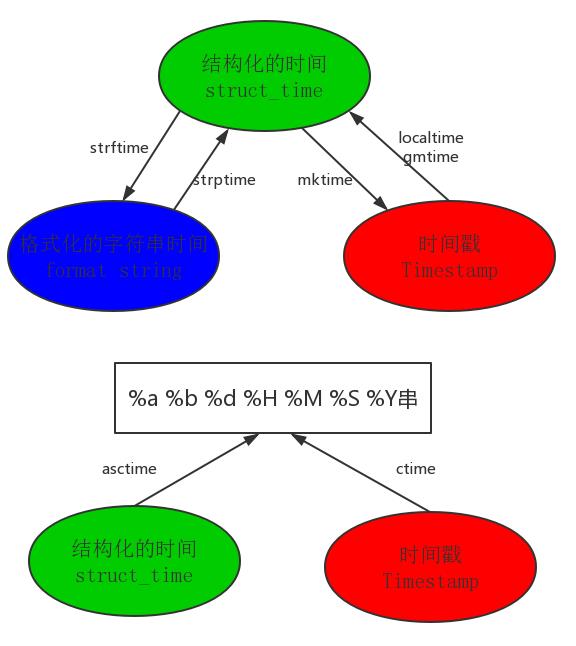
1 import time 2 print(time.time()) #获取时间戳:1527167372.0 3 time.sleep(0.1) #休眠0.1s 4 5 print(time.gmtime(1527167372.0)) #将时间戳转换为结构化的时间:(转换成的是utc时区的时间)如果参数未提供,则以当前时间为准 6 # time.struct_time(tm_year=2018, tm_mon=5, tm_mday=24, tm_hour=13, tm_min=9, tm_sec=32, tm_wday=3, tm_yday=144, tm_isdst=0) 7 print(time.localtime(1527167372.0)) # #将时间戳转换为结构化的时间:(转换成的是本地时区的时间)如果参数未提供,则以当前时间为准 8 #time.struct_time(tm_year=2018, tm_mon=5, tm_mday=24, tm_hour=21, tm_min=9, tm_sec=32, tm_wday=3, tm_yday=144, tm_isdst=0) 9 10 print(time.mktime(time.localtime()))#将一个结构化的时间转化为时间戳:1527167372.0 11 12 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2018-05-24 21:18:02 13 # strftime(format[, t]) : 把一个代表时间的元组或者结构化的时间(如由time.localtime()和 time.gmtime()返回)转化为格式化的时间字符串。 14 # 如果t未指定,将传入time.localtime()。如果元组中任何一个元素越界,ValueError的错误将会被抛出。 15 16 print(time.strptime(\'2018-05-24 21:21:00\', \'%Y-%m-%d %X\')) #把一个格式化时间字符串转化为结构化的时间。实际上它和strftime()是逆操作。 17 #time.struct_time(tm_year=2018, tm_mon=5, tm_mday=24, tm_hour=21, tm_min=21, tm_sec=0, tm_wday=3, tm_yday=144, tm_isdst=-1) 18 #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 19 20 print(time.asctime())#Thu May 24 21:21:01 2018 21 # 把一个表示时间的元组或者struct_time表示为这种形式:\'Thu May 24 21:21:01 2018\',如果没有参数,将会将time.localtime()作为参数传入。 22 23 print(time.ctime()) # Thu May 24 21:21:01 2018 24 print(time.ctime(time.time())) # Thu May 24 21:21:01 2018 25 # 把一个时间戳转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。 26 # 它的作用相当于time.asctime(time.localtime(secs))。
datetime模块
1 #时间加减 2 import datetime,time 3 4 print(datetime.datetime.now()) #返回 2018-05-24 21:39:23.444828 5 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2018-05-24 6 print(datetime.datetime.now() ) 7 print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 8 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 9 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 10 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 11 12 c_time = datetime.datetime.now() #2018-05-24 21:39:23.445329 13 print(c_time.replace(minute=3,hour=2)) #时间替换 2018-05-24 02:03:23.445329
2、random模块
1 import random 2 3 print(random.random())#(0,1) 大于0且小于1之间的小数 :0.39322977107276613 4 print(random.randint(1,4)) #[1,4] 大于等于1且小于等于4之间的整数 5 print(random.randrange(1,4)) #[1,4) 大于等于1且小于4之间的整数 6 print(random.choice([1,\'aa\',[4,5]]))#1或者aa或者[4,5] 7 print(random.sample([1,\'aa\',[4,5]],2))#列表元素任意2个组合 8 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 9 item=[2,4,6,7,9] 10 random.shuffle(item) #打乱item的顺序,相当于"洗牌" 11 print(item)
1 import random 2 checkcode = \'\' 3 for i in range(4): 4 current = random.randrange(0,4) 5 if current != i: 6 temp = chr(random.randint(65,90)) 7 else: 8 temp = random.randint(0,9) 9 checkcode += str(temp) 10 print(checkcode)
3、os模块
1 import os 2 print(os.getcwd())# 获取当前工作目录,即当前python脚本工作的目录路径 3 print(os.chdir("\\zz")) #改变当前脚本工作目录;相当于shell下cd 4 print(os.curdir) # 返回当前目录: (\'.\') 5 print(os.pardir) # 获取当前目录的父目录字符串名:(\'..\') 6 os.makedirs(\'D:\\zz\\模块\\dirname1\\dirname2\') # 可生成多层递归目录 7 os.removedirs(\'D:\\zz\\模块\\dirname1\\dirname2\') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 8 os.mkdir(\'dirname\') # 生成单级目录;相当于shell中mkdir dirname 9 os.rmdir(\'dirname\') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 10 os.listdir(\'dirname\') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 11 os.remove() # 删除一个文件 12 os.rename("oldname","newname")# 重命名文件/目录 13 os.stat(\'path/filename\') # 获取文件/目录信息 14 print(os.sep ) # 输出操作系统特定的路径分隔符,win下为"\\\\",Linux下为"/" 15 print(os.linesep) # 输出当前平台使用的行终止符,win下为"\\r\\n",Linux下为"\\n" 16 print(os.pathsep) # 输出用于分割文件路径的字符串 win下为;,Linux下为: 17 print(os.name) # 输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\' 18 os.system("ipconfig /all") # 运行shell命令,直接显示 19 print(os.environ) #获取系统环境变量 20 print(os.path.abspath(__file__)) #返回path规范化的绝对路径,返回当前文件的绝对路径 21 print(os.path.split(\'\\zz\\作业\\模块\\os模块.py\')) #将path分割成目录和文件名二元组返回:(\'\\\\zz\\\\作业\\\\模块\', \'os模块.py\') 22 print(os.path.dirname(\'\\zz\\作业\\模块\\os模块.py\')) # 返回path的目录。其实就是os.path.split(path)的第一个元素 23 print(os.path.basename(\'\\zz\\作业\\模块\\os模块.py\')) # 返回path最后的文件名。如果path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 24 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False 25 os.path.isabs(path) #如果path是绝对路径,返回True 26 os.path.isfile(path)# 如果path是一个存在的文件,返回True。否则返回False 27 os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False 28 os.path.join(path1[, path2[, ...]])# 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 29 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 30 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间 31 os.path.getsize(path)# 返回path的大小
1 #方式一:推荐使用 2 import os 3 #具体应用 4 import os,sys 5 6 possible_topdir = os.path.normpath(os.path.join( 7 os.path.abspath(__file__), 8 os.pardir, #上一级 9 os.pardir, 10 os.pardir 11 )) 12 print(possible_topdir) 13 sys.path.insert(0,possible_topdir) 14 15 #方式二:不推荐使用 16 print(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
4、sys模块
1 import sys 2 print(sys.argv) #命令行参数List,第一个元素是程序本身路径 3 # sys.exit(0) #退出程序,正常退出时exit(0) 4 print(sys.version) #获取Python解释程序的版本信息 5 print(sys.path) #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 print(sys.platform ) #返回操作系统平台名称 7 sys.stdout.write(\'please:\') 8 val = sys.stdin.readline()[:-1]
5、shutil模块
高级的 文件、文件夹、压缩包 处理模块
1 import shutil 2 3 shutil.copyfileobj(fsrc, fdst[, length]) # 将文件内容拷贝到另一个文件中 4 shutil.copyfileobj(open(\'old.xml\',\'r\'), open(\'new.xml\', \'w\')) 5 6 shutil.copyfile(src, dst)# 拷贝文件 7 shutil.copyfile(\'f1.log\', \'f2.log\') #目标文件无需存在 8 9 shutil.copymode(src, dst)# 仅拷贝权限。内容、组、用户均不变# 10 shutil.copymode(\'f1.log\', \'f2.log\') #目标文件必须存在 11 12 shutil.copystat(src, dst)# 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags 13 shutil.copystat(\'f1.log\', \'f2.log\') #目标文件必须存在 14 15 shutil.copy(src, dst)# 拷贝文件和权限 16 shutil.copy(\'f1.log\', \'f2.log\') 17 18 shutil.copy2(src, dst)# 拷贝文件和状态信息 19 shutil.copy2(\'f1.log\', \'f2.log\') 20 21 shutil.ignore_patterns(*patterns) 22 shutil.copytree(src, dst, symlinks=False, ignore=None) 23 # 递归的去拷贝文件夹 24 shutil.copytree(\'folder1\', \'folder2\', ignore=shutil.ignore_patterns(\'*.pyc\', \'tmp*\')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除 25 26 shutil.rmtree(path[, ignore_errors[, onerror]])# 递归的去删除文件 27 shutil.rmtree(\'folder1\') 28 29 shutil.move(src, dst)# 递归的去移动文件,它类似mv命令,其实就是重命名。 30 shutil.move(\'folder1\', \'folder3\') 31 32 33 34 shutil.make_archive(base_name, format,...) 35 \'\'\' 36 创建压缩包并返回文件路径,例如:zip、tar 37 创建压缩包并返回文件路径,例如:zip、tar 38 base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径, 39 如 data_bak =>保存至当前路径 40 如:/tmp/data_bak =>保存至/tmp/ 41 format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar” 42 root_dir: 要压缩的文件夹路径(默认当前目录) 43 owner: 用户,默认当前用户 44 group: 组,默认当前组 45 logger: 用于记录日志,通常是logging.Logger对象 46 \'\'\' 47 import shutil 48 ret = shutil.make_archive("data_bak", \'gztar\', root_dir=\'/data\') #将 /data 下的文件打包放置当前程序目录 49 rec = shutil.make_archive("/tmp/data_bak", \'gztar\', root_dir=\'/data\') #将 /data下的文件打包放置 /tmp/目录 50 # shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
6、json&pickle模块
eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1 import json 2 x="[null,true,false,1]" 3 print(eval(x)) #报错,无法解析null类型,而json就可以 4 print(json.loads(x))
一个软件/程序的执行就是在处理一系列状态的变化,在编程语言中,\'状态\'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好使用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
序列化:我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。在Python中叫pickling。
反序列化:反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
用处:1、持久保存状态;2、跨平台数据交互
python用于序列化的两个模块:
json:用于字符串 和 python数据类型间进行转换
pickle:用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
1 import json 2 data_obj = {\'name\':\'zz\',\'age\':13,\'sex\':\'M\'} 3 """ 4 dumps:序列化一个对象 5 sort_keys:根据key排序 6 indent:以4个空格缩进,输出阅读友好型 7 ensure_ascii: 可以序列化非ascii码(中文等) 8 """ 9 s_dumps = json.dumps(data_obj, sort_keys=True, indent=4, ensure_ascii=False) 10 print(s_dumps) 11 # ---------------------------------------------------分割线------------------------------------------------------------ 12 """ 13 dump:将一个对象序列化存入文件 14 dump()的第一个参数是要序列化的对象,第二个参数是打开的文件句柄 15 注意打开文件时加上以UTF-8编码打开 16 * 运行此文件之后在统计目录下会有一个data.json文件,打开之后就可以看到json类型的文件应该是怎样定义的 17 """ 18 with open("data.json", "w", encoding="UTF-8") as f_dump: 19 s_dump = json.dump(data_obj, f_dump, ensure_ascii=False) 20 print(s_dump) 21 # ---------------------------------------------------分割线------------------------------------------------------------ 22 """ 23 load:从一个打开的文件句柄加载数据 24 注意打开文件的编码 25 """ 26 with open("data.json", "r", encoding="UTF-8") as f_load: 27 r_load = json.load(f_load) 28 print(r_load) 29 # ---------------------------------------------------分割线------------------------------------------------------------ 30 """ 31 loads: 从一个对象加载数据 32 """ 33 r_loads = json.loads(s_dumps) 34 print(r_loads) 35 # ---------------------------------------------------分割线------------------------------------------------------------ 36 # 说明 37 # dct="{\'1\':111}"#json 不认单引号 38 # dct=str({"1":111})#报错,因为生成的数据还是单引号:{\'one\': 1} 39 dct=\'{"1":"111"}\' 40 print(json.loads(dct)) 41 # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads