如何用EXCEL统计上班时间
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用EXCEL统计上班时间相关的知识,希望对你有一定的参考价值。
IN OUT IN OUT 06:42 12:01 12:36 17:34 06:50 12:03 12:41 18:02 06:43 12:00 13:18 17:42 ------------------------------------------- 我有这样的一个表格... 我想把时间统一一下.比如规定7:00上班 那些7点前打卡的..统一到7点... 17:34下班的..算成17:30 再计算出工时.. 车间上班时间是 8:00-12:00 13:30-17:30 8小时 其他上班时间算加班... 好急啊... 大家帮帮忙啊
EXCEL中求时间差,可以直接相减:=B2-A2,并下拉填充;

求时间总和直接用求和函数SUM:=SUM(C2:C9);

是不是感觉到明显不符,这是因为,默认的时间格式是不超过24小时的,24小时以上的都按24的倍数,进到日期“天”上去了,时间只为除以24的余数,如要表示出总小时数,右击--设置单元格格式--数字--自定义--类型输入:[h]:mm;
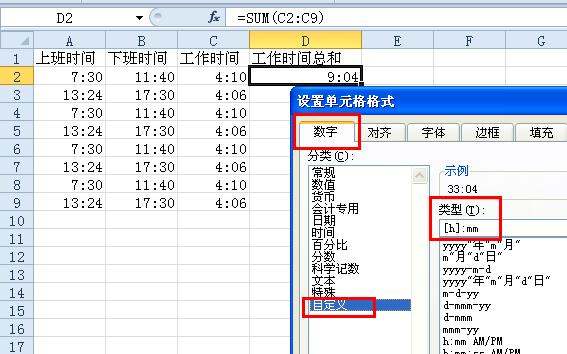
这样就显示出所有的小时数。

E2=MIN(B2,"12:00")-MAX(A2,"8:00")+MIN(D2,"17:30")-MAX(C1,"13:30")
F列加班时间:
F2=B2-A2+D2-C2-E2
将EF列单元格格式设为"时间"格式.
如何用python实现两个文件重复数据筛选并统计
文件1:MD5码,名字,IP
文件2:MD5码,ID,名字
我想把两个文件的MD5码做对比,看看文件1的MD5码在第二个文件中是否存在,若存在输出到文件3,然后输出统计总数,请问该怎么做?求大神指导,本人一直用excel,但数据量太大(5000万),想用Python·解决,谢谢!!!!我的分全拿出来悬赏了,希望大家能给代码让我自己运行试试看。久一点无所谓。谢谢
对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在我们需要统计这个列表里的重复项,并且重复了几次也要统计出来。
方法1:
?
1234
mylist = [1,2,2,2,2,3,3,3,4,4,4,4]myset = set(mylist) #myset是另外一个列表,里面的内容是mylist里面的无重复 项for item in myset: print("the %d has found %d" %(item,mylist.count(item)))
方法2:
?
123456
List=[1,2,2,2,2,3,3,3,4,4,4,4]a = for i in List: if List.count(i)>1: a[i] = List.count(i)print (a)
利用字典的特性来实现。
方法3:
?
123
>>> from collections import Counter>>> Counter([1,2,2,2,2,3,3,3,4,4,4,4])Counter(1: 5, 2: 3, 3: 2)
这里再增补一个只用列表实现的方法:
?
12345678910
l=[1,4,2,4,2,2,5,2,6,3,3,6,3,6,6,3,3,3,7,8,9,8,7,0,7,1,2,4,7,8,9] count_times = []for i in l : count_times.append(l.count(i)) m = max(count_times)n = l.index(m) print (l[n])
其实现原理就是把列表中的每一个数出现的次数在其对应的位置记录下来,然后用max求出出现次数最多的位置。
只用这段代码的话,有一个缺点,如果有多个结果,最后的现实的结果只是出现在最左边的那一个,不过解决方法也很简单 参考技术A
5000w建议你还是用数据库~如果你打算长久用的话.
单单是下面的代码, 就要好几秒
for i in range(100000000):a = 1
else:
print("ok")
最坏的5000w*5000w=2500000000000000
可能需要几个月的时间...
参考技术B #!/usr/bin/env python3file_ip = 'a.txt'
file_id = 'b.txt'
file_result = 'c.txt'
f2 = set()
with open(file_id) as f:
for line in f.readlines():
s = line.strip()
if s:
md5 = s.split(',')[0]
f2.add(md5)
total = 0
with open(file_ip) as f, open(file_result, 'w') as wf:
for line in f.readlines():
s = line.strip()
if s and s.split('\\n')[0] in f2:
total += 1
wf.write(s)
print('total:', total) 参考技术C
我没看到悬赏分
悬赏分不如RMB有吸引力
以上是关于如何用EXCEL统计上班时间的主要内容,如果未能解决你的问题,请参考以下文章