网站程序怎么判断是访客还是蜘蛛在访问?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网站程序怎么判断是访客还是蜘蛛在访问?相关的知识,希望对你有一定的参考价值。
网站程序怎么判断是访客还是蜘蛛访问? 然后针对蜘蛛访问显示不同的内容,也访客访问显示内容不同?
你确定要这么做?这是明摆着欺骗蜘蛛的无知,而且它现在已经学会怎么查看是否欺骗它了。根据不同的程序有不同的实现方法,需要程序员来写。给你一个php的参考一下<?php
$flag = false;
$tmp = $_SERVER['HTTP_USER_AGENT'];
if(strpos($tmp, 'Googlebot') !== false)
$flag = true;
else if(strpos($tmp, 'Baiduspider') >0)
$flag = true;
else if(strpos($tmp, 'Yahoo! Slurp') !== false)
$flag = true;
else if(strpos($tmp, 'msnbot') !== false)
$flag = true;
else if(strpos($tmp, 'Sosospider') !== false)
$flag = true;
else if(strpos($tmp, 'YodaoBot') !== false || strpos($tmp, 'OutfoxBot') !== false)
$flag = true;
else if(strpos($tmp, 'Sogou web spider') !== false || strpos($tmp, 'Sogou Orion spider') !== false)
$flag = true;
else if(strpos($tmp, 'fast-webcrawler') !== false)
$flag = true;
else if(strpos($tmp, 'Gaisbot') !== false)
$flag = true;
else if(strpos($tmp, 'ia_archiver') !== false)
$flag = true;
else if(strpos($tmp, 'altavista') !== false)
$flag = true;
else if(strpos($tmp, 'lycos_spider') !== false)
$flag = true;
else if(strpos($tmp, 'Inktomi slurp') !== false)
$flag = true;
if($flag == false)
//header("Location: url" . $_SERVER['REQUEST_URI']);
require_once("cd.htm");
// 自动转到rul 对应的网页
// $_SERVER['REQUEST_URI'] 为域名后面的路径
// 或 换成 header("Location: 具体的url");
exit();
else
require_once("news1.htm");
?> 参考技术A 最好不要这样作弊,会被查出来且被严厉惩罚的。
搜索引擎也可能派出匿名蜘蛛或者进行类似于正常访客的访问。
你无法完全排除和判断这种情况。
MapReduce 编程模板编写分析网站基本指标UV程序
1.网站基本指标的几个概念
PV: page view 浏览量
页面的浏览次数,用户每打开一次页面就记录一次。
UV:unique visitor 独立访客数
一天内访问某站点的人数(以cookie为例) 但是如果用户把浏览器cookie给删了之后再次访问会影响记录。
VV: visit view 访客的访问次数
记录所有访客一天内访问了多少次网站,访客完成访问直到浏览器关闭算一次。
IP:独立ip数
指一天内使用不同ip地址的用户访问网站的数量。
2.编写MapReduce编程模板
Driver
package mapreduce;
?
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
?
public class MRDriver extends Configured implements Tool {
?
public int run(String[] args) throws Exception {
//创建job
Job job = Job.getInstance(this.getConf(),"mr-demo");
job.setJarByClass(MRDriver.class);
?
//input 默认从hdfs读取数据 将每一行转换成key-value
Path inPath = new Path(args[0]);
FileInputFormat.setInputPaths(job,inPath);
?
//map 一行调用一次Map方法 对每一行数据进行分割
job.setMapperClass(null);
job.setMapOutputKeyClass(null);
job.setMapOutputValueClass(null);
?
//shuffle
job.setPartitionerClass(null);//分组
job.setGroupingComparatorClass(null);//分区
job.setSortComparatorClass(null);//排序
?
//reduce 每有一条key value调用一次reduce方法
job.setReducerClass(null);
job.setOutputKeyClass(null);
job.setOutputValueClass(null);
?
//output
Path outPath = new Path(args[1]);
//this.getConf()来自父类 内容为空可以自己set配置信息
FileSystem fileSystem = FileSystem.get(this.getConf());
//如果目录已经存在则删除
if(fileSystem.exists(outPath)){
//if path is a directory and set to true
fileSystem.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job, outPath);
//submit
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0:1;
}
?
public static void main(String[] args) {
Configuration configuration = new Configuration();
try {
int status = ToolRunner.run(configuration, new MRDriver(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
?
Mapper
public class MRModelMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 实现自己的业务逻辑
*/
}
}
Reduce
public class MRModelReducer extends Reducer<Text,LongWritable,Text,LongWritable> {
?
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
/**
* 根据业务需求自己实现
*/
}
}
3. 统计每个城市的UV数
分析需求:
UV:unique view 唯一访问数,一个用户记一次
map:
key: CityId (城市id) 数据类型: Text
value: guid (用户id) 数据类型:Text
shuffle:
key: CityId
value: {guid guid guid..}
reduce:
key: CityId
value: 访问数 即shuffle输出value的集合大小
output:
key : CityId
value : 访问数
MRDriver.java mapreduce执行过程
package mapreduce;
?
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
?
public class MRDriver extends Configured implements Tool {
?
public int run(String[] args) throws Exception {
//创建job
Job job = Job.getInstance(this.getConf(),"mr-demo");
job.setJarByClass(MRDriver.class);
?
//input 默认从hdfs读取数据 将每一行转换成key-value
Path inPath = new Path(args[0]);
FileInputFormat.setInputPaths(job,inPath);
?
//map 一行调用一次Map方法 对每一行数据进行分割
job.setMapperClass(MRMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
?
/* //shuffle
job.setPartitionerClass(null);//分组
job.setGroupingComparatorClass(null);//分区
job.setSortComparatorClass();//排序
*/
//reduce
job.setReducerClass(MRReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
?
//output
Path outPath = new Path(args[1]);
FileSystem fileSystem = FileSystem.get(this.getConf());
if(fileSystem.exists(outPath)){
//if path is a directory and set to true
fileSystem.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job, outPath);
//submit
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0:1;
}
?
public static void main(String[] args) {
Configuration configuration = new Configuration();
try {
int status = ToolRunner.run(configuration, new MRDriver(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
MRMapper.java
package mapreduce;
?
import java.io.IOException;
?
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
?
public class MRMapper extends Mapper<LongWritable,Text,Text,Text> {
private Text mapOutKey = new Text();
private Text mapOutKey1 = new Text();
//一行调用一次Map方法 对每一行数据进行分割
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//获得每行的值
String str = value.toString();
//按空格得到每个item
String[] items = str.split("\\t");
if (items[24]!=null) {
this.mapOutKey.set(items[24]);
if (items[5]!=null) {
this.mapOutKey1.set(items[5]);
}
}
context.write(mapOutKey, mapOutKey1);
}
}
MPReducer.java
package mapreduce;
?
import java.io.IOException;
import java.util.HashSet;
?
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
?
public class MRReducer extends Reducer<Text, Text, Text, IntWritable>{
?
//每有一个key value数据 就执行一次reduce方法
@Override
protected void reduce(Text key, Iterable<Text> texts, Reducer<Text, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
HashSet<String> set = new HashSet<String>();
for (Text text : texts) {
set.add(text.toString());
}
context.write(key,new IntWritable(set.size()));
}
}
4.MapReduce执行wordcount过程理解
input:默认从HDFS读取数据
Path inPath = new Path(args[0]); FileInputFormat.setInputPaths(job,inPath);
将每一行数据转换为key-value(分割),这一步由MapReduce框架自动完成。
输出行的偏移量和行的内容
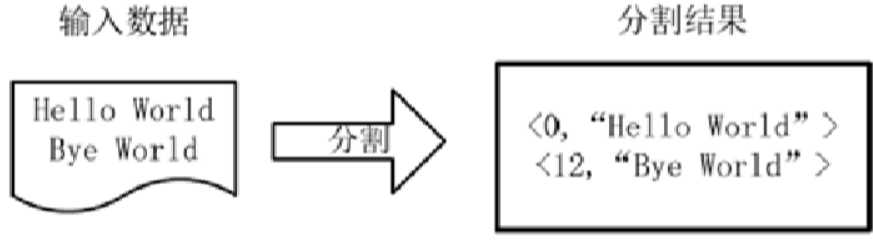
mapper: 分词输出
数据过滤,数据补全,字段格式化
输入:input的输出
将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对。
一行调用一次map方法。
统计word中的map:
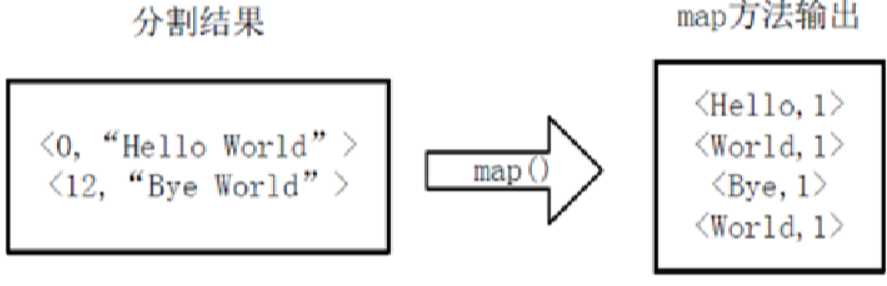
shuffle: 分区,分组,排序
输出:
<Bye,1>
<Hello,1>
<World,1,1>
得到map输出的<key,value>对,Mapper会将他们按照key进行排序,得到mapper的最终输出结果。
Reduce :每一条Keyvalue调用一次reduce方法
将相同Key的List<value>,进行相加求和
output:将reduce输出写入hdfs
以上是关于网站程序怎么判断是访客还是蜘蛛在访问?的主要内容,如果未能解决你的问题,请参考以下文章
PHP判断访客是不是是谷歌蜘蛛 如果是就不域名跳转如果不是就跳转域名 怎么实现呢 跪求啊
我想在网站中加入访问量统计功能,就是让访客了解网站的访问量,请问如何实现