Kafka 通过python简单的生产消费实现
Posted xibuhaohao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka 通过python简单的生产消费实现相关的知识,希望对你有一定的参考价值。
使用CentOS6.5、python3.6、kafkaScala 2.10 - kafka_2.10-0.8.2.2.tgz (asc, md5)
一、下载kafka
下载地址
https://kafka.apache.org/downloads
里面包含zookeeper
二、安装Kafka
1、安装zookeeper
mkdir /root/kafka/
tar -vzxf kafka_2.10-0.8.2.2

cd /root/kafka/kafka_2.10-0.8.2.2
cat config/zookeeper.properties | grep -v \'#\' >> config/zk.properties
mkdir -p /home/kafka/zk
vi zk.properties
dataDir=/home/kafka/zk #因为zookeeper变更为zk,所以需要在这里修改一下
启动zookeeper(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/zookeeper-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/zk.properties &
2、安装Kafka
cd /root/kafka/kafka_2.10-0.8.2.2
cat config/server.properties | grep -v \'#\' >> config/kafka_01.properties
启动Kafka(后台启动)
/root/kafka/kafka_2.10-0.8.2.2/bin/kafka-server-start.sh /root/kafka/kafka_2.10-0.8.2.2/config/kafka_01.properties &
三、新建Kafka topic
1、新建topic
cd /root/kafka/kafka_2.10-0.8.2.2
./bin/kafka-topics.sh --create --zookeeper 192.168.50.33:2181 --replication-factor 1 --partitions 1 --topic test
2、查看topic
./bin/kafka-topics.sh --list --zookeeper 192.168.50.33:2181
四、kafka生产者脚本
1、安装python的Kafka模块
pip3 install kafka-python(之前已安装)

2、kafka生产者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
\'\'\'
使用kafka的生产模块
\'\'\'
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers=\'{kafka_host}:{kafka_port}\'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort
))
try:
parmas_message = json.dumps(params)
producer = self.producer
producer.send(self.kafkatopic, parmas_message.encode(\'utf-8\'))
producer.flush()
except KafkaError as e:
print(e)
def main():
\'\'\'
测试consumer和producer
:return:
\'\'\'
# 测试生产模块
producer = Kafka_producer("127.0.0.1",9092,"test")
for i in range(1000000000000):
params = \'test---\' + str(i)
print(params)
producer.sendjsondata(params)
time.sleep(1)
if __name__ == \'__main__\':
main()
import os
print(os.uname)
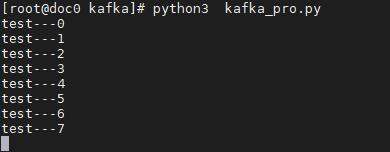
五、kafka消费者脚本
from kafka import KafkaProducer
from kafka import KafkaConsumer
from kafka.errors import KafkaError
import json
import time
\'\'\'
使用Kafka—python的消费模块
\'\'\'
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.groupid = groupid
self.consumer = KafkaConsumer(self.kafkatopic, group_id=self.groupid,
bootstrap_servers=\'{kafka_host}:{kafka_port}\'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort))
try:
for message in self.consumer:
# print json.loads(message.value)
yield message
except KeyboardInterrupt as e:
print(e)
def main():
\'\'\'
测试consumer和producer
:return:
\'\'\'
# 测试消费模块
# 消费模块的返回格式为ConsumerRecord(topic=u\'ranktest\', partition=0, offset=202, timestamp=None,
# \\timestamp_type=None, key=None, value=\'"{abetst}:{null}---0"\', checksum=-1868164195,
# \\serialized_key_size=-1, serialized_value_size=21)
consumer = Kafka_consumer(\'127.0.0.1\',
9092,
"test",
\'test-python-test\')
message = consumer.consume_data()
for i in message:
print(i.value)
if __name__ == \'__main__\':
main()
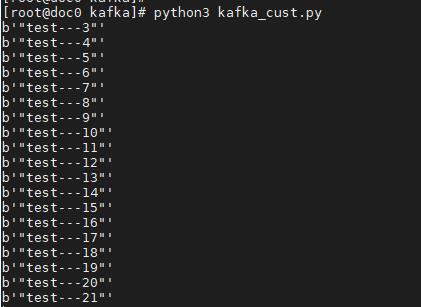
以上是关于Kafka 通过python简单的生产消费实现的主要内容,如果未能解决你的问题,请参考以下文章