简单理解python的垃圾回收机制
Posted 数据是宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单理解python的垃圾回收机制相关的知识,希望对你有一定的参考价值。
关键词:垃圾回收、引用计数、分代回收、标记-清除
前言:理解python中变量的定义:抽象理解python中变量的定义过程
1、垃圾回收机制的基本组成:
python采用的是以引用计数为主,以分代回收和标记清除为辅的垃圾回收机制
2、详细分析垃圾回收机制:
(1)首先是引用计数:
在python中,每创建一个对象,那么python解释器会自动为其设置一个特殊的变量,这个变量称为引用计数(初始值默认是1)。一旦有一个新变量指向这个对象,那么这个引用计数的值就会加1。如果引用计数的值为0。那么python解释器的内存管理系统就会自动回收这个对象所占的内存空间,删除掉这个对象。
①引用计数+1的情况:
对象被创建,例如a = "laoliang"对象被引用,例如b = a对象被作为参数,传入到一个函数中,例如fun(a)对象作为一个元素,存储在容器中,例如data_list=[a,b]
②引用计数-1的情况:
对象的别名被显式销毁,例如del a对象的别名被赋予新的对象,例如a = 24一个对象离开它的作用域,例如func函数执行完毕时,func函数中的局部变量(全局变量不会)对象所在的容器被销毁,或从容器中删除对象
③查看一个对象的引用计数:
import sys a = "hello laoliang" sys.getrefcount(a)
注意:查看a对象的引用计数时,比正常计数大1,因为调用函数的时候传入a,这会让a的引用计数+1。
(2)既然已经有引用计数了,那么为什么还要提出分代回收呢?
原因就是引用计数没办法解决“循环引用”的情况。
①“循环引用”分析:
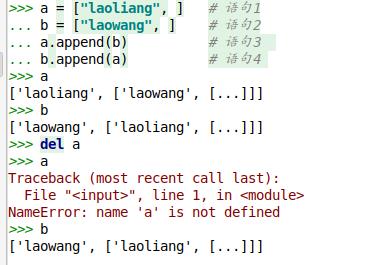
a = ["laoliang", ] # 语句1 b = ["laowang", ] # 语句2 a.append(b) # 语句3 b.append(a) # 语句4
# 此时对象的值:a = ["laoliang", b] b = ["laowang", a] del a # 语句5 del b # 语句6
# 执行完语句5和语句6是希望同时删除掉a对象和b对象
分析:

执行完语句1到语句4之后,会形成上图左边所示的对象引用关系。
由上图可知,在执行“del a”语句之后,只是删除了对象的引用,也就是此时a变量这个名字被删除,也就是此时对象[b, "laoliang"]的引用计数减1;执行"del b"语句也是同样的情况。
此时对象[b, "laoliang"]中有一个引用,指向了[a, "laowang"],所以此时[b, "laoliang"]的引用计数不为0,所以存在于内存中,不真正被删除。[a, "laowang"]也是一个道理。但是,此时,由于显式指向它们的变量已经不存在了,所以也没办法删除了,就会导致它们一直存在于内存空间中。 这就是循环引用出现的问题。 此时,单靠引用计数没办法解决问题。所以便提出了分代回收。
②分代回收:
注意:在分代回收中,如果某对象的引用计数为0,那么它所占的内存空间同样也会被python解释器回收。
a、此时在python中每创建一个对象,那么就会把对象添加到一个特殊的“链表”中,这个链表称为"零代链表"。每当创建一个新的对象,那么就会将其添加到零代链表中。当这个"零代链表"中的对象个数达到某一个指定的阀值的时候,python解释器就会对这个"零代链表"进行一次“扫描操作”。这个“扫描操作”所做的工作是查找链表中是否存在循环引用的对象,如果在扫描过程中,发现有互相引用的对象,那么会让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到“一代链表”中。
b、同样,python解释器也会在一定的情况下,也扫描“一代链表”,判断其中是否存在互相引用的对象。如果存在,那么同样也是让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到“二代链表”中。
c、同样,python解释器也会在一定的情况下,也会扫描"二代链表",判断其中是否存在互相引用的对象。如果存在,那么同样也是让这些对象的引用计数都减少1。此时,如果某些对象引用计数变成0,那么就会被python解释器回收其所占用的内存空间;如果对象的引用计数仍然不为0,那么会把此时存活的对象迁移到一个新的特殊的内存空间。此时重新进行"零代链表 -> 一代链表 -> 二代链表"的循环。
这就是python的分代回收机制。
(3)那么既然已经有分代回收了,那么为什么又要提出标记-清除呢?
原因就是分代回收没办法解决“误删”的情况。
①“误删”分析:
a = ["laoliang", ] # 语句1 b = ["laowang", ] # 语句2 a.append(b) # 语句3 b.append(a) # 语句4
# 此时对象的值:a = ["laoliang", b] b = ["laowang", a]。 ["laoliang", b]、["laowang", a]的引用计数都为2 del a # 语句5
# 此时["laoliang", b]的引用计数为1, ["laowang", a]的引用计数为2
# 执行完语句5只希望删除a对象
如果按照分代回收的方式来处理上述语句。那么,python解释器在执行完语句5之后。在一定的情况下进行查找循环引用对象的时候,会发现此时["laowang", a]对象和["laoliang", b]对象存在互相引用的情况。所以此时就会让这两个对象的引用计数减1。此时,["laoliang", b]对象的引用计数为0,所以["laoliang", b]对象被真正删除,但是其实此时["laowang", a]对象中是有一个变量引用原来的["laoliang", b]对象的。如果["laoliang", b]对象被真正删除的话,那么此时["laowang", a]对象中的a变量就没有用了,就没有办法访问了。但是其实我们是希望它有用的,所以这个时候就出现“误删”的情况了。所以此时就需要结合“标记-清除”来解决问题了。
②标记-清除:
- 此时同样是检测链表中的相互引用的对象,然后让它们的引用计数减1之后;
- 但是此时会将所有的对象分为两组:死亡组(death_group)和存活组(survival_group),把引用计数为0的对象添加进死亡组,其它的对象添加进存活组;
- 此时会对存活组的对象进行分析,只要对象存活,那么其内部的对象当然也必须存活。如果发现内部对象死亡,那么就会想方设法让其活过来,通过这样子就能保证不会删错对象了。
3、综上所述:
以上是关于简单理解python的垃圾回收机制的主要内容,如果未能解决你的问题,请参考以下文章