Jenkins:python-unitest选择失败的版本号进行重跑失败的用例
Posted channy14
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Jenkins:python-unitest选择失败的版本号进行重跑失败的用例相关的知识,希望对你有一定的参考价值。
Jenkins配置:
1.增加字符参数FAIL_VERSION,默认为no

2.buid的时候,加一个判断,当有输入版本号的时候走重跑的路
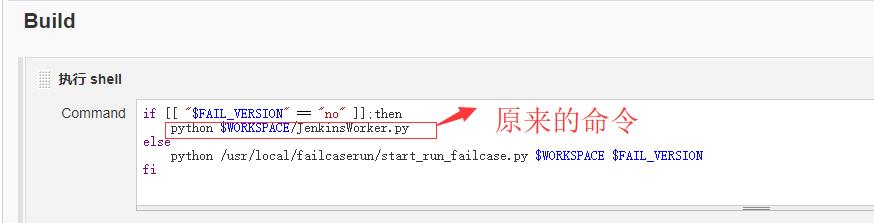
if [[ "$FAIL_VERSION" == "no" ]];then python $WORKSPACE/JenkinsWorker.py else python /usr/local/failcaserun/start_run_failcase.py $WORKSPACE $FAIL_VERSION fi
源码如下:
FailCaseRun.py


#coding=utf-8 import os,sys from lxml import etree from BaseFun import excuteSuiteExportReport, analysisResult import HTMLTestRunner,unittest resultlogpath = sys.argv[1] def analysisResult(test_result): """分析测试报告""" failure_count = test_result.failure_count error_count = test_result.error_count print("用例执行失败个数为%s" % failure_count) print("用例执行错误个数为%s" % error_count) if failure_count == 0 and error_count == 0: print "正常退出" else: print "异常退出" raise Exception("用例执行失败") def parsing(): """解析测试结果报告""" print "分析的测试报告为:" + resultlogpath #默认是XML解析器,碰到不规范的html文件时就会解析错误,增加解析器 parser = etree.HTMLParser(encoding=\'utf-8\') html = etree.parse(resultlogpath, parser=parser) return html def get_failcasecount_and_failsuitelist(): """获取失败的用例数量和失败的suite列表""" html= parsing() #获取用例执行结果,如:Status: Pass 19 Failure 11 Error 2 status = html.xpath(\'//div[@class="heading"]/p/text()\')[2] ##获取失败用例数情况 status_list = status.strip().split(\' \') if "Failure" not in status_list and "Error" not in status_list: #无失败和错误的用例 fail_casecount = 0 elif "Failure" in status_list or "Error" not in status_list: #有失败无错误的用例 failure_count_index = status_list.index("Failure") + 1 fail_casecount = status_list[failure_count_index] elif "Failure" not in status_list or "Error" in status_list: #无失败有错误的用例 failure_count_index = status_list.index("Error") + 1 fail_casecount = status_list[failure_count_index] elif "Failure" in status_list and "Error" in status_list: #有失败和错误的用例 failure_count_index = status_list.index("Failure") + 1 error_count_index = status_list.index("Error") + 1 fail_casecount = status_list[failure_count_index] + status_list[error_count_index] else: raise AssertionError(resultlogpath +"测试报告中无用例执行成功/失败信息,请确认") print "测试报告中用例执行结果:" + status + "; 失败用例数:" + str(fail_casecount) fail_suitelist = [] if fail_casecount != 0: fail_suitecount = len(html.xpath(\'//tr[@class="failClass"]\')) for i in range(fail_suitecount): fail_suitelist.append(html.xpath(\'//tr[@class="failClass"]/td[1]\')[i].text) print "测试报告中失败的suite:" + str(fail_suitelist) return int(fail_casecount),fail_suitelist else: print "测试报告中无失败用例,不需要重跑" def get_failcaselist(): """获取该失败的用例列表""" # fail_casecount = get_failcasecount_and_failsuitelist()[0] fail_suitelist = get_failcasecount_and_failsuitelist()[1] fail_suitecount = len(fail_suitelist) fail_caselist = [] fo_html = open(resultlogpath, \'rb\') i = -1 fail_caseinfo_andsuite_list = [None] * fail_suitecount for j in range(fail_suitecount): fail_caseinfo_andsuite_list[j] = [] for line in fo_html: if "<tr class=\'errorClass\'>" in line or "<tr class=\'failClass\'>" in line: i = i + 1 if "<td class=\'failCase\'><div class=\'testcase\'>" in line or "<td class=\'errorCase\'><div class=\'testcase\'" in line: # 获取失败的用例所在行 casename_tmp = line.strip().split("<div class=\'testcase\'>")[1].split("</div>")[0] suite_and_case_info_tmp = {\'suitename\':fail_suitelist[i],\'casename\':casename_tmp} fail_caseinfo_andsuite_list[i].append(suite_and_case_info_tmp) for k in range(fail_suitecount): for tmp in fail_caseinfo_andsuite_list[k]: fail_caselist.append(tmp) # print fail_caselist return fail_caselist def run_failcase(): """主程序,进行重跑操作""" fail_caselist = get_failcaselist() print "失败的case列表:",fail_caselist suite = unittest.TestSuite() for tmp in fail_caselist: suitename = tmp[\'suitename\'] casename = tmp[\'casename\'] suite.addTest(eval(suitename)(casename)) test_result = excuteSuiteExportReport(\'index.html\', suite) analysisResult(test_result) if __name__ == \'__main__\': run_failcase() # get_failcasecount_and_failsuitelist()
start_run_failcase.py
#coding=utf-8 import os,sys #重跑程序所在系统路径 path=\'/usr/local/failcaserun\' script_name = \'FailCaseRun.py\' FailCaseRun = os.path.join(path,script_name) def import_module_in_workspace(workspace_path,script_path_in_workspace): """将工作目录下的MyTestCase_开头的py文件导入到重跑的脚本中,在获取失败suite列表的时候需要用到""" #读取文件的所有内容 fp = file(FailCaseRun) lines = [] for line in fp: lines.append(line) fp.close() #获取目录下MyTestCase_开头的文件名 for tmp in os.listdir(workspace_path): if \'MyTestCase_\' in tmp and \'pyc\' not in tmp: tmp_name = tmp.split(\'.\')[0] tmp_import_module = \'import \' + tmp_name + \'\\n\' lines.insert(1, tmp_import_module) # 在第二行插入 import 模块名,获取suitelist的时候需要用到 s = \'\'.join(lines) fp = file(script_path_in_workspace, \'w\') # 原脚本导入工作目录下的模块后,保存到workspace下 fp.write(s) fp.close() def get_faillog_path(version,workspace_path): """依据重跑的版本号及工作路径获取失败用例的日志路径""" workspace_par_path = os.path.dirname(workspace_path) faillog_path = os.path.join(workspace_par_path,\'builds/\'+version+ \'/htmlreports/HTML_Report/index.html\') if not os.path.exists(faillog_path): raise AssertionError("指定的版本号不存在,请检查文件是否存在:" + faillog_path) return faillog_path if __name__ == \'__main__\': workspace_path = sys.argv[1] run_version = sys.argv[2] print "重跑用例信息,工作路径:" + workspace_path +",版本号:" +run_version script_path_in_workspace = workspace_path + \'/\' + script_name import_module_in_workspace(workspace_path,script_path_in_workspace) faillog_path = get_faillog_path(run_version,workspace_path) print(\'python \' + script_path_in_workspace + \' \' + faillog_path) os.system(\'python \' + script_path_in_workspace + \' \' + faillog_path)
以上是关于Jenkins:python-unitest选择失败的版本号进行重跑失败的用例的主要内容,如果未能解决你的问题,请参考以下文章