针对移动端与嵌入式视觉应用的卷积神经网络MobileNet系列解析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了针对移动端与嵌入式视觉应用的卷积神经网络MobileNet系列解析相关的知识,希望对你有一定的参考价值。
参考技术A
MobileNet V1 (2017)
(1)MobileNets基于一种流线型结构使用深度可分离卷积来构造轻型权重深度神经网络,核心部件就是 深度可分离卷积
(2)MobileNet是一种基于深度可分离卷积的模型,深度可分离卷积是一种将标准卷积分解成深度卷积以及一个1x1的卷积即逐点卷积
(3)深度卷积针对每个单个输入通道应用单个滤波器进行滤波,然后逐点卷积应用1x1的卷积操作来结合所有深度卷积得到的输出
(4)对深度卷积,它的卷积核厚度不是输入张量的通道数,而是1,输出通道就是卷积核数目。经典卷积的卷积核厚度默认是图片的通道数
(5)可分离卷积tf内置函数: tf.layers.separable_conv2d
公式计算:
MobileNet V2 (2018)
(1)Mobilenet V2实在Mobilenet V1的基础上发展而来,V2 主要引入了两个改动:Linear Bottleneck 和 Inverted Residual Blocks。两个改动分别对应V1和Resnet
(2)MobileNetV1遗留的问题
(3) 对比 MobileNet V1 与 V2 的微结构
(4) 对比 ResNet 与 MobileNet V2 的微结构
MobileNet V3 (2019)
论文地址:https://arxiv.org/pdf/1905.02244.pdf
(1)具体的内容可以看论文,这里我只是重点说明其中的激活函数改进(swish/h-swish)和网络结构改进(bneck)
(2)激活函数:作者发现一种新出的激活函数swish x 能有效改进网络精度
但就是计算量太大了,于是作者对这个函数进行了数值近似:
近似结果:
(3)网络结构:在大体思路上引用mobilenet v2的结构pw-dw-pw,其中激活函数添加了h-swish,同时在v2基础上添加了Squeeze excitation layer,具体的设置可查阅论文中的网络参数图对照,
其中Squeeze excitation layer
Squeeze excitation layer是引入基于squeeze and excitation结构的轻量级注意力模型SENet
论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507
图像分类ShuffleNet: 一个极端高效的移动端卷积神经网络
码字不易,欢迎点赞。文章同步发布在公众号:CV前沿
在上一篇文章中,我们已经介绍了一种针对移动端和嵌入式设备的卷积神经网络—-MobileNet。今天我们要介绍的是旷视科技在2017年12月份提出的更加高效的移动端卷积神经网络—-ShuffleNet。
在ShuffleNet网络中使用了两个创新的操作:
-
pointwise group convolution(逐点组卷积)
-
channle shuffle(通道混洗)
概要来说,逐点组卷积是降低了逐点卷积(也即是1*1卷积)的计算复杂度; 同时为了消除多个组卷积堆叠产生的副作用,采用通道混洗的操作来改善跨特征通道的信息流动。使得ShuffleNet网络在保持准确率的情况下,极大的降低了计算成本。ShuffleNet网络在ImageNet竞赛和MS COCO竞赛中均表现了比其他移动端先进网络更优越的性能。
逐点组卷积
我们在文章中介绍移动端不同类型的卷积操作时,其中讲到了普通卷积、组卷积和逐点组卷积这几个概念。
这里再简单回顾一下,组卷积是在输入特征图的通道方向执行分组;逐点组卷积本只是组卷积的一种特殊形式,特殊的地方在于它的卷积核的核大小为1*1。如下图所示。

那么为什么ShuffleNet网络要使用逐点组卷积呢?
这要从ResNext讲起。
我们知道,ResNext就是对ResNet的残差单元进行了微创新,创新点就是组卷积,从而提升了网络的精度。ResNet和ResNext的残差单元如下所示。

ResNet unit 结构图
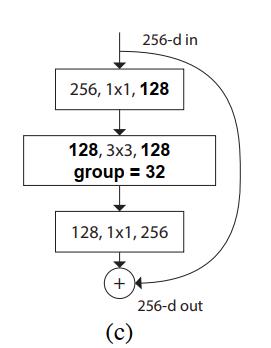
ResNext unit 结构图
但对于ResNext的一个残差单元来说,逐点卷积(1*1卷积)占整个残差单元计算量的93.4%,可见逐点卷积的计算成本是很高的。那么在小型网络中,为了符合移动端设备上有限的计算资源,代价昂贵的逐点卷积会导致网络整体变窄(每层通道数变少),进而可能带来精度的大幅度下降。
总结来说,由于逐点卷积的昂贵的计算开销,使得网络在满足设备计算资源情况下,无法满足精度需求。从而这种网络结构不适应于移动端和嵌入式设备。
为了解决这个问题,本文提出了逐点组卷积。逐点组卷积的特点是通过保证每个卷积操作仅仅是作用在对应的输入通道组,使得大大减少了计算量。
我们根据对组卷积的知识,假设组个数为 g g g, 那么逐点组卷积相对于逐点卷积,计算量下降了 g g g倍。
但是,如果多个组卷积堆叠在一起,会产生一个副作用:某个通道的输出结果,仅来自于一小部分输入通道。如下图图(a)。
这个副作用会导致在组与组之间信息流动的阻塞,以及表达能力的弱化。
那么我们如何解决这个问题呢? 这用到了本文的第二个创新—通道混洗。
通道混洗
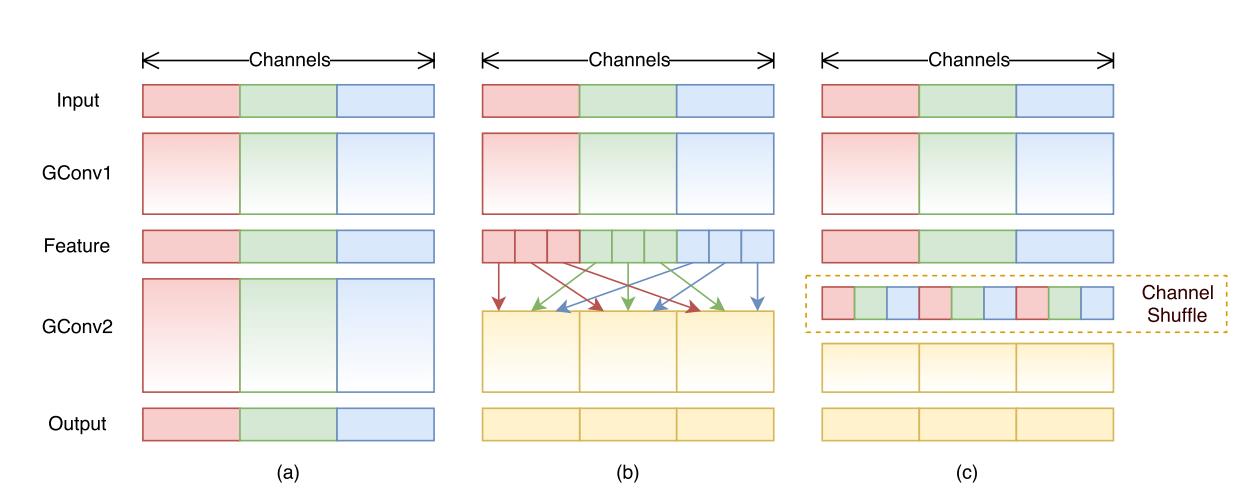
如图所示。通过对比图(a)和图(b),我们在第一个逐点组卷积之后,对输出的结果的通道次序进行打乱,比如原始在通道维度上的索引是0,1,2,3,4,5,6,7,8;那么打乱后变为了0,3,6,1,4,7,2,5,8。
经过这样打乱之后,输出通道就不再仅仅来自于是一小部分输入通道,也会来自其他的通道。即输出通道和输入通道完全的关联了。形成的效果如图(c)所示。
通道混洗的操作实现了多组卷积层的跨组信息流动。
ShuffleNet Unit
利用逐点组卷积和通道打乱的操作,我们可以建立一个针对于小型网络特别设计的ShuffleNet unit。

最初设计是一个残差块(residual block)如图(a)所示。
然后在(a)的残差分支中,对于其中的3 * 3卷积层,我们应用一个计算成本低的3 * 3 的DW卷积。
然后我们替换了第一个逐点卷积,改为逐点组卷积,后面跟一个通道混洗操作。如图(b)所示。
图(b)中的第二个逐点组卷积的目的是为了恢复输出通道数量(升维),从而和输入通道数量一致,以便能够实现与捷径分支的输出结果进行相加操作。(相加要求两个分支的特征图在宽度、高度和深度均一致)
这就形成了一个完整的ShuffleNet unit了。
此外,我们知道卷积神经网络都需要有降采样操作,一种实现方式是采用最大池化层,另一种做法是使用stride=2的卷积来实现。
在ShuffleNet unit中,同样是采用的stride=2的卷积。如图(c)所示。具体做法是分别在捷径分支的分支设置stride=2和主分支的3*3 DW卷积中设置stride=2,从而既能够实现降采样的操作,同时又能够实现两个分支输出结果的融合。
这里还需要注意的两点是:
-
捷径分支上它采样的是3 * 3的平均池化。
-
融合没有采用相加的方法,而是通道方向的拼接。文中介绍到这样是为了更容易以很少的计算量来扩大通道维度。
与ResNet,ResNext计算量的对比
假设输入特征图形状是 c ∗ h ∗ w c*h*w c∗h∗w,以及bottleneck 模块的通道数是m,那么三个网络的残差单元的计算量分别是:
ResNet unit:
1 ∗ 1 ∗ c ∗ m ∗ h ∗ w + 3 ∗ 3 ∗ m ∗ m ∗ h ∗ w + 1 ∗ 1 ∗ m ∗ c ∗ h ∗ w = h w ( 2 c m + 9 m 2 ) 1*1*c*m*h*w+3*3*m*m*h*w+1*1*m*c*h*w = hw(2cm+9m^2) 1∗1∗c∗m∗h∗w+3∗3∗m∗m∗h∗w+1∗1∗m∗c∗h∗w=hw(2cm+9m2)
ResNext unit:
1
∗
1
∗
c
∗
m
∗
h
∗
w
+
(
3
∗
3
∗
m
∗
m
∗
h
∗
w
)
/
g
+
1
∗
1
∗
m
∗
c
∗
h
∗
w
=
h
w
(
2
c
m
+
9
m
2
/
g
)
1*1*c*m*h*w+(3*3*m*m*h*w)/g+1*1*m*c*h*w = hw(2cm+9m^2/g)
1∗1∗c∗m∗h∗w+(3∗3∗m∗m∗h∗w)/g+1∗1∗m∗c∗h∗w=hw(2cm+9m2/g)
ShuffleNet unit:
(
1
∗
1
∗
c
∗
m
∗
h
∗
w
)
/
g
+
3
∗
3
∗
m
∗
h
∗
w
+
(
1
∗
1
∗
m
∗
c
∗
h
∗
w
)
/
g
=
h
w
(
2
c
m
/
g
+
9
m
)
(1*1*c*m*h*w)/g+3*3*m*h*w+(1*1*m*c*h*w)/g = hw(2cm/g+9m)
(1∗1∗c∗m∗h∗w)/g+3∗3∗m∗h∗w+(1∗1∗m∗c∗h∗w)/g=hw(2cm/g+9m)
可见,ShuffleNet unit需要的计算量最小。
换句话说,在给定的有限的计算资源下,ShuffleNet 能够使用更宽的特征图。
作者发现这对于小型网络来说至关重要。因为通常小型网络通常有很少的通道数来处理信息。
完整的网络结构

如图所示。可以看出,ShuffleNet 主要是由ShuffleNet unit 堆叠而成,并划分了Stage2、Stage3、Stage4三个阶段。在每个阶段的第一个模块中设置stride=2,从而实现降采样的功能。然后从一个阶段到下一个阶段,会实现通道数的加倍。
在ShuffleNet unit 中,组个数 g g g代表着逐点卷积的连接稀疏程度。在上图中展示了不同的组数量的方案,同时通过调整输出通道数(网络的宽窄),来使得整体的计算量大致相同。那么对于一个给定的计算量约束, g g g越大,那么就可以设置越多的卷积核,产生越多的输出通道。从而帮助编码更多的信息。
最后,和MobileNet一样,ShuffleNet 也有一个宽度系数,来灵活调整整个网络的参数和计算量。
实验
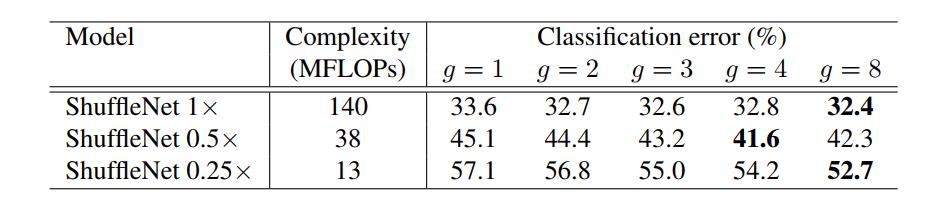
实验1 group 数量
-
在三个不同宽度系数下,分组数量 g > 1 g>1 g>1的效果始终比 g = 1 g=1 g=1的效果好。
-
对于1倍宽度系数,分组数组 g = 8 g=8 g=8相比 g = 1 g=1 g=1分类错误率下降1.2百分点;而对于0.25倍宽度系数,下降了4.4个百分点。可见越小的网络,越能够从分组数组的增加中收益。
-
对于给定的有限计算量,更大的分组数量允许更多的特征图通道,因此,我们猜测宽的特征图带来的网络性能增加,是由于编码了更多的信息。
实验2 有无通道混洗

实验显示,包含通道混洗的网络,均比不包含通道混洗的网络的效果好。
实验3 与MobileNet 的对比

已知MobileNet 同样是专注于移动端的高效的卷积神经网络。具体分析如下:
- 图中每一行都是相近的计算复杂度下两个模型的对比,分别有520、300、140、40这四个复杂度。可以直观的看到,无论哪个复杂度,ShuffleNet 在ImageNet 分类竞赛上的分类错误率均低于MobileNet。
- 考虑到ShuffleNet 有50层,而MobileNet 只有28层,在最后一行中ShuffleNet通过将自身网络的Stage2到Stage4中的block 删除了一半,形成了一个只有26层的 ShuffleNet 0.5× shallow (g = 3) ,与相似复杂度下的0.25 MobileNet-224 进行对比,发现效果仍然比MobileNet 效果好。可见是网络结构的优势,而不是网络层次深度的原因。
小结
ShuffleNet 针对现大多数模型采用的逐点卷积存在的问题,提出了逐点组卷积和通道混洗的处理方法,并基于这两个操作提出了一个ShuffleNet unit,最后在多个竞赛中证明了这个网络的效率和精度。
本文介绍到这里就结束了,下一篇会介绍ShuffleNetV2,让我们拭目以待。
码字不易,欢迎点赞
文章同步发布在公众号:CV前沿
以上是关于针对移动端与嵌入式视觉应用的卷积神经网络MobileNet系列解析的主要内容,如果未能解决你的问题,请参考以下文章
图像分类ShuffleNet: 一个极端高效的移动端卷积神经网络
图像分类ShuffleNet: 一个极端高效的移动端卷积神经网络
图像分类ShuffleNet: 一个极端高效的移动端卷积神经网络