并发编程-线程与锁
Posted maoqifan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程-线程与锁相关的知识,希望对你有一定的参考价值。
1. 什么是线程?
线程的状态与进程的状态非常相似,但线程是在进程内运行的轻量级实体。线程与进程的主要区别是线程共享相同的地址空间,而进程具有独立的地址空间。这意味着在进程中运行的每个线程都可以访问相同的变量和数据结构,而在不同进程中运行的线程则不能访问彼此的变量和数据结构。
在上下文切换期间,线程的状态信息存储在线程控制块 (TCB) 中,其中包括寄存器值、程序计数器 (PC) 和其他与线程相关的状态信息。当操作系统需要切换到另一个线程时,它会保存当前线程的状态并将控制传递给另一个线程的TCB。然后,操作系统会将该线程的状态信息从其TCB中恢复,使该线程可以继续执行。
由于在线程之间进行上下文切换时不需要更改地址空间,因此在切换线程时比在切换进程时更快。这使得多线程应用程序能够更高效地利用处理器的并发性能。
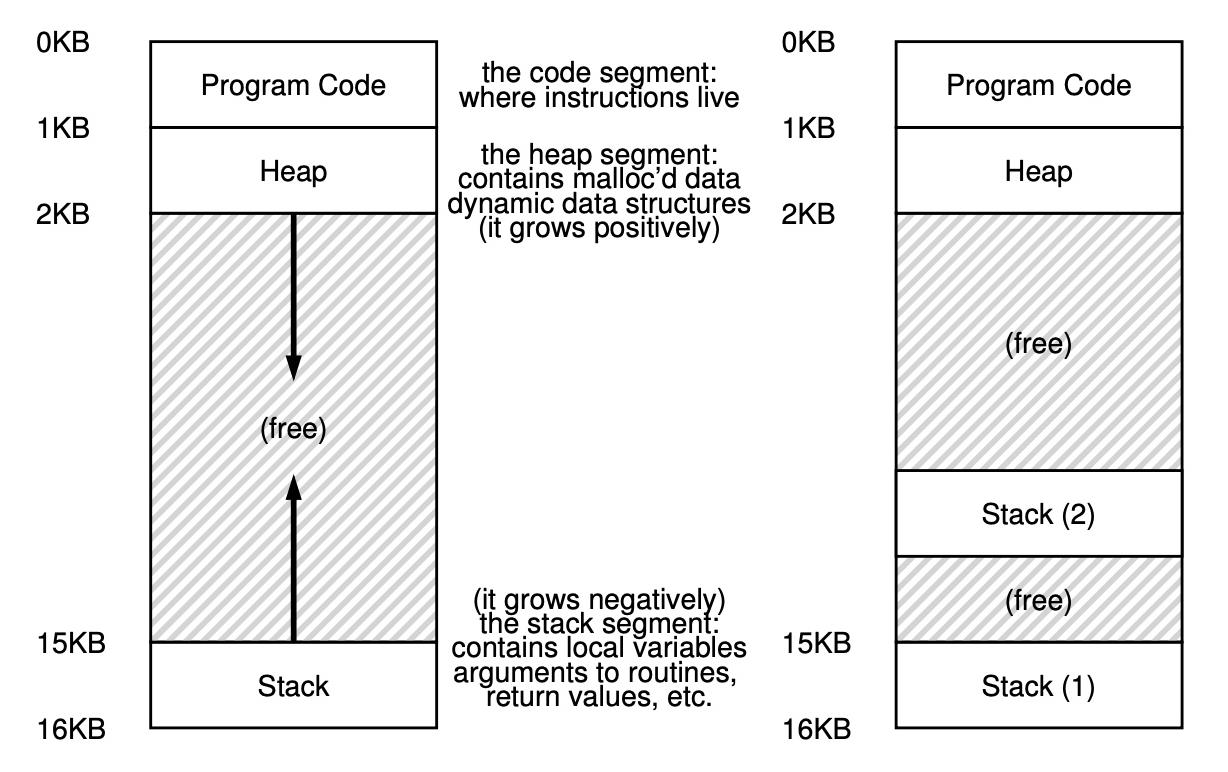
下面的图片摘自《Operating System: Three Easy Pieces》《Operating System: Three Easy Piece,通过该图片,我们知道了几件事:
- 简化了的线程的地址空间包含三部分即:Program Code(程序/指令)、Heap(堆) and Stack(栈),其中堆是主动扩展的(包含动态分配的数据以及动态数据结构)而栈则是被动扩展(包括在栈上分配的变量、参数、返回值和我们放在栈上的其他东西都将被放置在有时称为线程本地存储的地方,即相关线程的栈)。
- 多线程相对于单线程,多的就是本地栈即每一个线程维护一个栈,栈上的数据不共享;多个线程共享同一片堆内存(数据共享)。
2. 为什么使用线程?
这里其实OSTEP的作者说了好长一段,我认为其实总结起来就是一点:
使用多线程可以并行(并发)的处理事情。比如说单线程时,一个时间点你只能处理一个请求,而多线程则可以同时处理多个请求。
3. 如何创建线程?
3.1 使用pthread创建线程
这里,我用C语言标准库pthread来实现线程的创建,代码如下。在我之后的博客我会详解java的线程操作,到那时我还会再用java来演示线程的创建。
#include <stdio.h>
#include <pthread.h>
void *mythread(void *arg)
printf("%s\\n", (char *)arg);
return NULL;
int main(void)
pthread_t p1, p2;
puts("main begin");
pthread_create(&p1, NULL, mythread, "A");
pthread_create(&p2, NULL, mythread, "B");
// join waits for the thread to finish
pthread_join(p1, NULL);
pthread_join(p2, NULL);
puts("main end");
return 0;
上面就是一段很简单的线程创建代码,首先我定义了一个函数,这个函数的返回值是个无类型指针(这意味着我可以通过 return (void *)ret_val 就返回任何我想要的数据类型,如果不了解c的语法可以bing或者chatgpt一下),接着在主线程中我定义了两个pthread_t类型的变量p1和p2,然后我使用pthread_create()函数创建线程,最后我使用pthread_join()等待线程p1终止其执行,然后再让线程p2继续执行(如果不了解这两个api可以通过man指令查看一下pthread里面的函数定义),运行结果如下。

乍一看,这两个线程井然有序地运行着,事实果真如此吗?我们试着用脚本运行这个程序1000次,让我们看看运行结果:

看第29-32行,P2线程竟然先于P1线程运行完成。现在,大家可能开始觉得并发编程有点反直觉了,不急,我们再写个例子,大家会觉得更反直觉。
3.2 使用多线程更改共享数据
我们现在使用线程p1和p2来对公共变量counter进行累加。按道理说,p1执行1e7次加操作,p2执行1e7次加操作,最后counter的结果应该是2e7才对,那么事实是这样吗?让我们来试试。
#include <stdio.h>
#include <pthread.h>
static volatile int counter = 0;
void *mythread(void *arg)
printf("%s: begin\\n", (char *)arg);
int i;
for (i = 0; i < 1e7; ++i)
counter++;
printf("%s: end\\n", (char *)arg);
return NULL;
int main(void)
pthread_t p1, p2;
pthread_create(&p1, NULL, mythread, "A");
pthread_create(&p2, NULL, mythread, "B");
printf("main start with counter = %d\\n", counter);
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main end with counter = %d\\n", counter);
return 0;
执行结果如下:
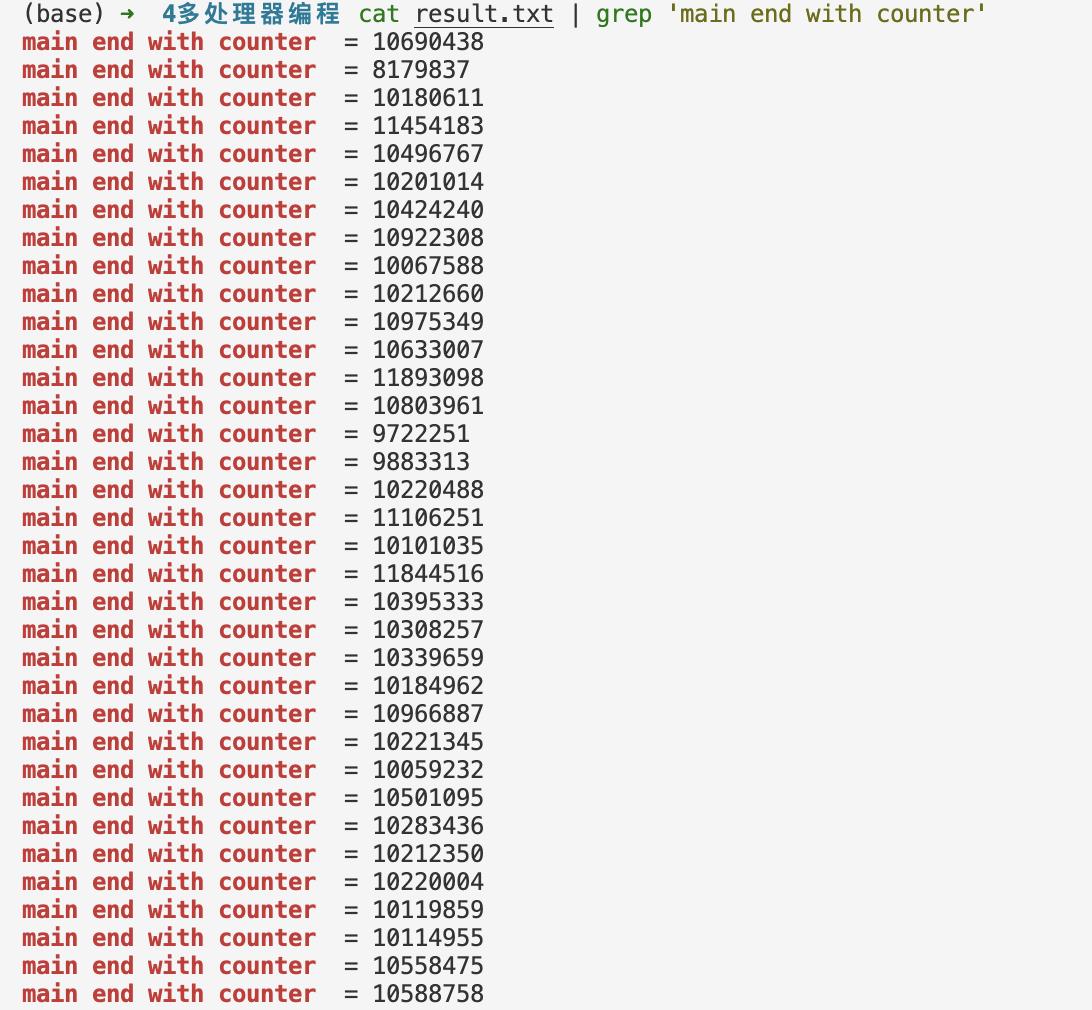
我们执行脚本运行该程序1000次后,发现除了2e7这个结果,什么稀奇古怪的结果都有,那么这是为什么呢?为了知道这段程序究竟干了什么,我们使用 gcc -g target.c 来编译这个程序接着使用 objdump -d a.out( -d选项表示以反汇编(disassemble)的形式显示二进制文件的内容)查看内容,部分内容如下:

框框中就是执行counter+1操作的汇编指令(我的电脑是mac,所以不同的指令集可能会有些区别),让我们来解读一下这3条指令
- 将内存地址
%rbp-12处的32位整数值移动到寄存器%eax中。 - 将寄存器
%eax中的值加上1,然后将结果存回寄存器%eax中。 - 将寄存器
%eax中的值移动到内存地址%rbp-12处。
那么,为什么总是得不到2e7这个正确的结果呢?我们假设p1现在准备给counter的值加1,首先,p1读取到当前的counter值(我们假设为100),按照上面的命令p1现在把这个值放入 %eax寄存器中,然后给 %eax寄存器中保存的值+1,那么此时 %eax寄存器里的值是101对吧?此时,定时器中断,OS把当前的运行线程的状态保存起来。不巧!p2这个时候先运行了,他和p1做了同样的事,最后成功使得counter的值从100变成了101。此时,p1重新运行,将 %eax寄存器里的值放回内存地址,这样counter的值还是101。从上面的分析我们可以看出,p1和p2都对counter执行了+1操作,但是counter的值最终只增加了1,这就是导致我们最后没法得到正确结果2e7的真正原因!
上面我们演示的这个情况有个名字叫作race condition(竞争条件),也就是说代码执行的结果是不确定的,就比如上面的例子中,p1在使counter+1的过程中刚好遇到了上下文切换导致了意外(或者意料之中)的发生。因为执行这段代码的多个线程会导致竞争条件,所以我们称这段代码为临界区(critical section)。 临界区是一段访问共享变量(或更一般地,共享资源)的代码,并且不能由多个线程同时执行。所以,现在我们希望做的事就是当p1执行这段代码时,p2不能和p1同时执行这段代码,我们称这种情况为互斥(mutual exclusion).
4. 锁
4.1 什么是锁
在3.2节的最后,我们说了我们希望p1和p2对临界区的访问是互斥的。锁就是用来做这件事的,我们可以在p1或者p2进入临界区之前加锁,退出临界区时解锁,这样不就实现了p1和p2的互斥了吗?
那么回到本节的题目:什么是锁?最简单的锁其实就是一个变量,因此要使用一个锁,你就必须声明某种锁变量(e.g.pthread.h里的互斥锁pthread_mutex_t,后面会讲到)。 这个锁变量(或简称“lock”)在任何时刻都保持着锁的状态。 它要么是可用的(或着说这把锁是未锁定的或空闲的),因此没有线程持有锁;要么已获取(或锁定或持有),因此恰好有一个线程持有锁,并且可能在临界区中执行操作。
关于锁的lock()和unlock()。比如,p1执行lock()表示寻求(acquire)这把锁,那么如果这把锁已经被别的线程p2持有了,那么p1就需要一直等(自旋),等到p2释放了这把锁,lock()函数在会返回,p1才能拿到锁进入临界区。
下面这段话引自《Operating System: Three Easy Pieces》,我认为很有意义,感兴趣的读者可以阅读一下:
Locks provide some minimal amount of control over scheduling to programmers. In general, we view threads as entities created by the programmer but scheduled by the OS, in any fashion that the OS chooses. Locks yield some of that control back to the programmer; by putting a lock around a section of code, the programmer can guarantee that no more than a single thread can ever be active within that code. Thus locks help transform the chaos that is traditional OS scheduling into a more controlled activity.
4.2 使用pthread_mutex_t
讲了上面这么多,下面呢我们使用pthread.h中定义的互斥锁来对我们上面的代码进行改写,看看加了锁后的代码的执行结果是否如我们所愿。代码如下:
#include <stdio.h>
#include <pthread.h>
#include <assert.h>
#include <stdlib.h>
// 共享变量
static volatile int count = 0;
// 锁
pthread_mutex_t m_lock = PTHREAD_MUTEX_INITIALIZER;
// 上锁
void my_pthread_mutex_lock(pthread_mutex_t *mutex)
int rc = pthread_mutex_lock(mutex);
assert(rc == 0);
// 释放锁
void my_pthread_mutex_unlock(pthread_mutex_t *mutex)
int rc = pthread_mutex_unlock(mutex);
assert(rc == 0);
void *mythread(void *arg)
int i;
// 上锁
my_pthread_mutex_lock(&m_lock);
// 全局变量+1
for (i = 0; i < 1e7; ++i)
// 自增
++count;
// 释放锁
my_pthread_mutex_unlock(&m_lock);
return NULL;
int main(void)
pthread_t a, b;
pthread_create(&a, NULL, mythread, \'A\');
pthread_create(&b, NULL, mythread, \'B\');
pthread_join(a, NULL);
pthread_join(b, NULL);
printf("count -> %d", count);
return 0;
同样的,我们把上面的代码执行1000次后,观测结果如下:

在这段命令行中,我利用脚本 test.sh执行 a.out 1000次并利用 grep -c 命令统计出1000行结果中出现了多少次2e7,结果1000代表我们每一次运行都获得了正确的结果!
4.3 锁的任务
锁最重要的任务就是实现互斥,即阻止多个线程同时进入临界区。除了实现互斥,锁还需要做到如下几件事:
- 不能有线程应为拿不到锁而饿死,导致这个线程永远也拿不到锁。
- 保证性能,特别是在多个线程竞争同一把锁的情况下。
4.4 各种锁的实现
4.4.1 控制中断
伪代码如下:
void lock()
DisableInterrupts();
void unlock()
EnableInterrupts();
这里的加锁表示禁止中断,解锁表示允许中断,这种方法只适用于单处理器的时代,并且这种方法还存在以下问题:
- 向程序提供了过高的权限(直接操作中断),如果该程序是恶意程序,那么就会发生不好的事(e.g.重启之前电脑变成砖)。
- 多处理器情况下不支持这种行为。
- 会导致一些严重的系统问题的发生。
综上所述,这个方法很蠢,我们来看下一个。
4.4.2 简单flag实现锁
这个想法很简单,我们假设lock是一个结构体,里面有一个变量flag,初始化时flag为0。当有线程accquire锁时(lock()操作),用一个while循环判断flag是不是为1(为1代表锁被别人占用了),为1就一直循环等待(自旋);不为1则将flag设为1,表示拿到锁。释放锁时则设置flag为0,代码如下:
typedef struct __lock_t int flag; lock_t;
void init(lock_t *mutex)
mutex->flag = 0;
void lock(lock_t *mutex)
while (mutex->flag == 1)
; // 自旋等待
mutex->flag = 1; // 拿到锁
void unlock(lock_t *mutex)
mutex->flag = 0; // 释放锁
这个想法主要有下面两个问题:
- 正确性:没有实现互斥,两个线程还是能同时进到临界区。
- 性能:拿到锁了还搁那自旋,浪费时间(直到上下文切换之前都没法执行自己的代码)
4.4.3 TestAndSet
来,我们先看看代码:
typedef struct __lock_t
int flag;
lock_t;
void init(lock_t *lock)
lock->flag = 0;
void lock(lock_t *lock)
while (TestAndSet(&lock->flag, 1) == 1) // 其实就这里和上面不一样
;
void unlock(lock_t *lock)
lock->flag = 0;
一看,哎你这个代码和上面的有甚么区别?答案是13的TestAndSet()函数,那么这个函数的定义是什么,这个函数有什么用呢? 我们通过以下 C 代码片段定义TestAndSet指令的作用:
int TestAndSet(int *old_ptr, int new)
int old = *old_ptr; // 获得old value
*old_ptr = new; // 用更新的值替换old value
return old; // 返回old value
上面这段代码是TestAndSet的C语言描述:某个线程p1申请锁所以调用 lock()当 lock->flag=1 时表示锁被占用而此时 TestAndSet()函数会返回1进而满足while的循环条件,就实现了p1的自旋等待;而当 lock->falg=0 时表示锁未被占用,TestAndSet()函数会使 lock->flag=1 并返回0,此时不满足while的循环条件,p1就可以拿到锁并进入临界区。而事实上,上面的TestAndSet()代码并不是原子的(Atomic),它在执行的过程中可能会发生中断,所以正确的TestAndSet()应该是一条原子指令(Atomic Instruction),在C语言代码中我们可以使用 asm volatile内嵌汇编代码,真正的TestAndSet()定义如下:
static inline int atomic_test_and_set(volatile int *addr, int newval)
int result;
asm volatile(
"lock xchg %0, %1"
: "+m"(*addr), "=a"(result)
: "1"(newval)
: "memory");
return result;
我们通过将检查old value和将old value更新为 new value 变成了原子操作,这样就实现了只有一个线程能拿到这把锁的效果,即同一时刻只有一个线程能进入临界区(即互斥)!
同样的,这个方法也有其缺陷,让我们来分析一下!
首先,这个锁它是一把公平锁吗?答案是否定的,自旋锁不提供任何公平保证。 事实上,在竞争中,一个线程可能永远旋转下去。 简单的自旋锁(如前所述)是不公平的,可能会导致饥饿(Starvation)。
4.4.4 Load-Linked and Store-Conditional
以下是wiki关于这对指令的介绍:
In computer science, load-linked/store-conditional ( LL/SC ), sometimes known as load-reserved/store-conditional ( LR/SC ), are a pair of instructions used in multithreading to achieve synchronization . Load-link returns the current value of a memory location, while a subsequent store-conditional to the same memory location will store a new value only if no updates have occurred to that location since the load-link. Together, this implements a lock-free, atomic, read-modify-write operation.
Load-Linked的操作与典型的加载指令非常相似,只是从内存中获取一个值并将其放入寄存器中。 关键区别在于 Store-Conditional,如果没有对地址进行干预存储(即Load-Linked后,地址处的值未被改变),它只会成功(并更新存储在刚刚加载链接的地址处的值)。 在成功的情况下,store-conditional 返回 1 并将 ptr 处的值更新为 value; 如果失败,则不更新 ptr 处的值并返回 0。其伪代码如下:
int LoadLinked(int *ptr)
return *ptr;
int StoreConditional(int *ptr, int value)
if (no update to * ptr since LoadLinked to this address)
*ptr = value;
return 1; // 成功
else
return 0; // 失败
类似TestAndSet指令,这对指令也是原子指令。接下来,我们看如何用这对指令实现一把锁:
void lock(lock_t *lock)
while (1)
while (LoadLinked(&lock->flag) || !StoreConditional(&lock->flag, 1));
// 只要当flag不为0或者更新flag值为1失败,就自旋直到flag为0且flag被成功更新为1后才停止自旋。
void unlock(lock_t *lock)
lock->flag = 0;
接下来,我们来试着理解一下这把锁为什么能实现互斥。当前有一线程p1试图获取锁,调用 LoadLinked()返回0,表示当前没有线程占用这把锁。接着,在 StoreConditional()被调用前,发生了中断。此时,p2也要获取锁,于是它试图调用 LoadLinked()并返回0。此时,两个线程都调用了 LoadLinked()并且准备调用 StoreConditional()。这对指令的关键特征是线程p1和p2中只有一线程会成功地将 flag更新为 1,从而获得锁; 另一个线程 尝试 StoreConditional()将失败(因为另一个线程通过 StoreConditional()更新了flag值)因此必须再次尝试获取锁。所以,这把锁可以实现互斥!
4.4.5 Fetch-And-Add和TicketLock
Fetch-And-Add同样是一条原子指令(意味着同样是硬件原语,Hardware Primitive)。它的功能是在返回特定地址上的旧值的同时对其自动递增,其伪代码如下:
int FetchAndAdd(int *ptr)
int old = *ptr;
*ptr = old + 1;
return old;
大家可能会疑惑为什么需要这条指令。答案是我们可以使用它实现Ticket Lock,什么是TicketLock呢?Ticket Lock 是 为了解决自旋锁的公平性问题,类似于现实中吃饭/买票的排队叫号 :锁拥有一个服务号,表示正在服务的线程,还有一个排队号;每个线程尝试获取锁之前先拿一个排队号,然后不断轮询锁的当前服务号是否是自己的排队号,如果是,则表示自己拥有了锁,不是则继续轮询。TicketLock代码如下:
typedef struct lock_t
int ticket; // 票,表示你所在的轮次
int turn; // 当前排到谁了
lock_t;
void lock_init(lock_t *lock)
lock->ticket = 0;
lock->turn = 0;
void lock(lock_t *lock)
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
; // spin
void unlock(lock_t *lock)
lock->turn = lock->turn + 1;
TicketLock与上面所有的锁最大的区别就是,它确保所有线程的进度。 一旦一个线程被分配了它的ticket,它将在未来的某个时间点被调度(一旦它前面的那些线程已经通过临界区并释放了锁)。我们前面讲过的锁可都不能保证这个哦~
4.5 自旋锁存在的问题及其改进
4.5.1 自旋锁的问题
好了,朋友们,我们看完了上面的这些锁是不是突然觉得锁也就那么回事呢?有没有想过他们有什么共同点?他们是不是都是自旋锁?一直自旋会不会浪费CPU资源?让我们分析一下!还是老演员线程p1和p2,如果我们的p1拿到了锁进入了临界区,此时发生了中断。注意!p1的锁还没有释放,此时p2开始运行它发现锁已经被占用了,于是他就开始自旋、自旋、自旋...除了自旋啥也做不了。幸运的是p1结束运行并释放了锁,我们的p2终于拿到了它梦寐以求的锁。以上是两个锁争抢(contend)锁的情况,如果我们将其扩展到N(N >= 3)个线程争抢锁,就会有N-1个线程自旋等待那个持有锁的线程释放锁,这样何尝不是对CPU资源的一种极大浪费呢?接下来,我们将讨论如何解决这个问题。
4.5.2 改进:使用yield()
上面,我们讲到了自旋会白白浪费CPU资源,那么我们能不能让操作系统给我们提供一种原语使得线程在自旋的时候放弃CPU,让别的线程运行呢?我们可以使用yield()(它的作用是暂时放弃当前线程对CPU的占用权,将它让给其它线程),使用yield()优化后的自旋锁代码如下:
void init()
flag = 0;
void lock()
while (TestAndSet(&flag, 1) == 1)
yield(); // 放弃亲爱的CPU,让别的线程使用!
void unlock()
flag = 0;
都说到yield()了,我们首先知道线程有几个重要状态即:Running、Ready以及Blocked,yield()这个系统调用只是让调用者(某个线程)从运行状态移动到就绪状态,从而让另一个线程运行。 因此,让出线程本质上是自行取消调度。
这个方法虽然解决了自旋浪费时间片的问题,但是会有上下文切换带来资源的浪费的问题。同时,也没解决线程会被饿死的情况。
4.5.3 改进:使用队列
现在,我们使用一个队列来跟踪哪些线程正在等待获取锁。 使用 Solaris系统提供的两个例程:park() 使调用线程进入睡眠状态,unpark(threadID) 唤醒由 threadID 指定的特定线程。 这两个例程可以串联使用来构建一个锁,如果当前线程试图获取已经被别的线程持有的锁,它会使当前线程进入睡眠状态,并在锁空闲时将其唤醒。 代码如下:
typedef struct lock_t
int flag;
//guard的作用是用来防止多个线程同时访问并修改共享变量的flag和queue。
int guard;
queue_t *q; // 队列
lock_t;
void lock_init(lock_t *m)
m->flag = 0;
m->guard = 0;
queue_init(m->q);
void lock(lock_t *m)
while (TestAndSet(&m->guard, 1) == 1)
; // 拿guard锁
if (m->flag == 0)
m->flag = 1; // 拿到锁
m->guard = 0;
else
queue_add(m->q, gettid());
m->guard = 0;
park();
void unlock(lock_t *m)
while (TestAndSet(&m->guard, 1) == 1)
; // 拿guard锁
if (queue_empty(m->q))
m->flag = 0; // 如果对列为空,则直接释放
else
unpark(queue_remove(m->q)); // 不为空,则从队列中把下一个线程移除
// 让下一个线程可以拿到guard锁
m->guard = 0;
让我们先看lock(),其中的TestAndSet里的对象从前面的flag变成了guard,我们首先来解释下为什么要这样做。guard在上述代码中的作用其实就是是用来防止多个线程同时访问并修改共享变量的flag和queue。guard变量在每次访问共享变量之前都会被TestAndSet函数设置为1,其他线程就无法再访问并修改共享变量,从而保证了变量的安全。在自旋结束后,如果当前flag锁没有被别的线程持有,则拿到锁,并将guard设置为0(为什么这样做呢?因为需要让没拿到锁的线程进入等待队列等待)。反之,如果锁被别的线程占有,则当前线程入队,将guard设置为0并调用park()方法进入休眠。
同样的,unlock()中也需要通过TestAndSet(guard, 1),然后判断当前等待队列是不是空,如果为空当前线程直接释放锁,如果不为空则把等待队列的队首移除并设置guard为0。
4.5.4 扩展:linux中的futex
futex 是 Linux 内核中的一个系统调用,用于实现用户空间线程之间的同步和互斥。它是 "fast userspace mutex" 的缩写,意为用户空间快速互斥锁。
futex 的基本思想是:将一个整型变量用作锁,通过系统调用提供的操作可以实现线程的等待和唤醒。在用户空间,使用 futex 函数可以进行对这个整型变量的操作,比如读取、赋值和等待唤醒等,而不需要进入内核空间。只有在必要时,futex 才会调用内核的锁机制。这种设计使得 futex 操作非常高效,可以快速地实现线程的同步和互斥。其使用代码如下:
void mutex_lock(int *mutex)
int v;
/* Bit 31 was clear, we got the mutex (the fastpath) */
if (atomic_bit_test_set(mutex, 31) == 0)
return;
atomic_increment(mutex);
while (1)
if (atomic_bit_test_set(mutex, 31) == 0)
atomic_decrement(mutex);
return;
/* We have to waitFirst make sure the futex value
we are monitoring is truly negative (locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait(mutex, v);
void mutex_unlock(int *mutex)
/* Adding 0x80000000 to counter results in 0 if and
only if there are not other interested threads */
if (atomic_add_zero(mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
futex_wake(mutex);
上面这段代码来自 nptl 库中的 lowlevellock.h(gnu libc 库的一部分)。
5. 总结
在这片文章中,我们首先讲了什么是线程,为什么要使用线程,接着我们讲了如何创建线程并且通过两个线程访问共享变量的例子引出了锁这一并发编程中的重要组成部分。在锁这一小节中,我们首先讲了什么是锁,如何使用c中的pthread_mutex_t以及说明锁的任务是什么,从而讲到了各种锁(自旋锁)的实现。通过发现并分析自旋锁存在的问题,提出了对自旋锁的各种改进方案。
这篇文章是我这一系列文章中的第一篇,下一篇文章我将会详细的讲解并发编程中的同步问题(包括条件变量、信号量)等等。
最后,感谢《Operating System: Three Easy Pieces》这本书以及我亲爱的绿导师,他的操作系统课讲得非常好,大家如果感兴趣可以前去观摩,谢谢大家。
Java并发编程学习:线程安全与锁优化
本文参考《深入理解java虚拟机第二版》
一。什么是线程安全?
这里我借《Java Concurrency In Practice》里面的话:当多个线程访问一个对象,如果不考虑这些线程在运行时环境下的调度和交替执行,也不需要额外的同步,或者调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那么这个对象是线程安全的。
我的理解:多线程访问一个对象,任何情况下,都能保持正确行为,就是对象就是安全的。
我们可以将Java语言中各种操作共享的数据分为以下5类:不可变、 绝对线程安全、 相对线程安全、 线程兼容和线程对立。
1.不可变
不可变(Immutable)的对象一定是线程安全的,无论是对象的方法实现还是方法的调用者,都不需要再采取任何的线程安全保障措施。
Java语言中,如果共享数据是一个基本数据类型,那么只要在定义时使用final关键字修饰它就可以保证它是不可变的。 如果共享数据是一个对象,那就需要保证对象的行为不会对其状态产生任何影响才行,如果读者还没想明白这句话,不妨想一想java.lang.String类的对象,它是一个典型的不可变对象,我们调用它的substring()、
replace()和concat()这些方法都不会影响它原来的值,只会返回一个新构造的字符串对象。保证对象行为不影响自己状态的途径有很多种,其中最简单的就是把对象中带有状态的变量都声明为final,这样在构造函数结束之后,它就是不可变的
不可变的对象的,也就是被声明成fianl的对象,只要被正确构建出来,在不发现this逃逸的情况下,其外部状态永远不会改变,永远不会看到多个线程中处于不一致的状态。也就是说所有对象的共享变量都声明成final ,那么就是安全的。
2.绝对线程安全
绝对的线程安全完全满足Brian Goetz给出的线程安全的定义,这个定义其实是很严格的,一个类要达到“不管运行时环境如何,调用者都不需要任何额外的同步措施”
在Java API中标注自己是线程安全的类,大多数都不是绝对的线程安全。
如果说java.util.Vector是一个线程安全的容器,相信所有的Java程序员对此都不会有异议,因为它的add()、
get()和size()这类方法都是被synchronized修饰的,尽管这样效率很低,但确实是安全的。
但是,即使它所有的方法都被修饰成同步,也不意味着调用它的时候永远都不再需要同步手段了。如果一个线程要查找i位置的变量,结果另一个线程把他删除了,就会包异常。
抛出异常的原因:因为如果另一个线程恰好在错误的时间里删除了一个元素,导致序号i 已经不再可用的话,再用i 访问数组就会抛出一个 ArrayIndexOutOfBoundsException
如果要保证这段代码能够正确执行下去,修改后的代码为
// 对线程安全的容器 Vector的测试(修改后的代码)
public class ModifiedVectorTest {
private static Vector<Integer> vector = new Vector<>();
public static void main(String[] args) {
while(true) {
for (int i = 0; i < 100; i++) {
vector.add(i);
}
Thread removeThread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (vector) { // 添加同步块,this line
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
}
}
});
Thread printThread = new Thread(new Runnable() {
@Override
public void run() {
synchronized (vector) { // 添加同步块,this line
for (int i = 0; i < vector.size(); i++) {
System.out.println(vector.get(i));
}
}
}
});
removeThread.start();
printThread.start();
// 不要同时产生过多的线程,否则会导致os 假死
while(Thread.activeCount() > 20);
}
}
}
3.相对线程安全
相对的线程安全就是我们通常意义上所讲的线程安全,它需要保证对这个对象单独的操作是线程安全的,我们在调用的时候不需要做额外的保措施,但是对于一些特定顺序的连续调用,就可能需要在调用端使用额外的同步手段来保证调用的正确性。
在Java语言中,大部分的线程安全类都属于这种类型,例如Vector、
HashTable、Collections的synchronizedCollection()方法包装的集合等。
4.线程兼容
线程兼容是指对象本身并不是线程安全的,但是可以通过在调用端正确地使用同步手段来保证对象在并发环境中可以安全地使用,我们平常说一个类不是线程安全的,绝大多数时候指的是这一种情况。
Java API中大部分的类都是属于线程兼容的,如与前面的Vector和HashTable相对应的集合类ArrayList和HashMap等。
5.线程对立
线程对立是指无论调用端是否采取了同步措施,都无法在多线程环境中并发使用的代码。 由于Java语言天生就具备多线程特性,线程对立这种排斥多线程的代码是很少出现的,而且通常都是有害的,应当尽量避免。
一个线程对立的例子是Thread类的suspend()和resume()方法,如果有两个线程同时持有一个线程对象,一个尝试去中断线程,另一个尝试去恢复线程,如果并发进行的话,无论调用时是否进行了同步,目标线程都是存在死锁风险的,如果suspend()中断的线程就是即将要执行resume()的那个线程,那就肯定要产生死锁了。
1.6.3)关于synchronized 和 ReentrantLock 性能的分析:
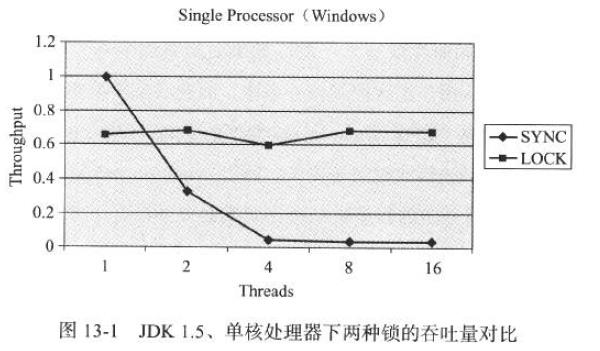
对上图的分析(Analysis):
A1)多线程环境下 synchronized的吞吐量下降得非常严重,而 ReentrantLock 则能基本保持在同一个比较稳定的水平上;与其说ReentrantLock性能好,还不如说 synchronized还有非常大的优化余地;
A2)虚拟机在未来的性能改进中肯定也会更加偏向于原生的 synchronized,所以还是提倡在 synchronized能实现需求的情况下,优先考虑使用 synchronized 来进行同步;
2.4)如何使用CAS 操作来避免阻塞同步,看个荔枝:(测试incrementAndGet 方法的原子性)

// Atomic 变量自增运算测试(incrementAndGet 方法的原子性)
public class AtomicTest {
public static AtomicInteger race = new AtomicInteger(0);
public static void increase() {
// 输出正确结果,一切都要归功于 incrementAndGet 方法的原子性
race.incrementAndGet();
}
public static final int THREADS_COUNT = 20;
public static void main(String[] args) throws Exception {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 10000; j++) {
increase();
}
}
});
threads[i].start();
}
while(Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(race);
}
/**
* incrementAndGet() 方法的JDK 源码
* Atomically increment by one the current value.
* @return the updated value
*/
public final int incrementAndGet() {
for(;;) {
int current = get();
int next = current + 1;
if(compareAndSet(current,next)) {
return next;
}
}
}
}
2.5)CAS操作(比较并交换操作)的ABA问题:如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就说它的值没有被其他线程改变过了吗? 如果在这段期间它的值曾经被改为了B,之后又改回了A,那CAS操作就会误认为它从来没有被改变过,这个漏洞称为 CAS操作的 ABA问题;
2.6)解决方法:J.U.C 包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的version 来保证CAS的正确性。不过目前来说这个类比较鸡肋, 大部分cases 下 ABA问题 不会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更高效;
public class LockEliminateTest {
// raw code
public String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}
// javac 转化后的字符串连接操作
public String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
}
对以上代码的分析(Analysis):
A1)对于 javac 转化后的字符串连接操作代码: 使用了同步,因为StringBuffer.append() 方法中都有一个同步块,锁就是sb对象。虚拟机观察变量sb,很快就会发现他的动态作用域被限制在 concatString() 方法内部;也就是所 sb 的所有引用都不会逃逸到方法之外;
A2)所以,虽然这里有锁,但是可以被安全地消除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了;
// javac 转化后的字符串连接操作
public String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}

以上是关于并发编程-线程与锁的主要内容,如果未能解决你的问题,请参考以下文章