优化数据呈现方式,分组双轴图是最佳选择
Posted xzj3900
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化数据呈现方式,分组双轴图是最佳选择相关的知识,希望对你有一定的参考价值。
- 简介
分组双轴图是一种数据可视化图表,指有多个(≥2)Y轴的数据图表,多为分组柱状图+折线图的结合,图表显示更为直观,可以很好地展示不同指标之间的关系,帮助用户更好地理解数据,做出更准确的决策。除了适合分析两个相差较大的数据,分组双轴图也适用于显示大类别如何细分为较小的类别,以及每部分与总量之间的关系。
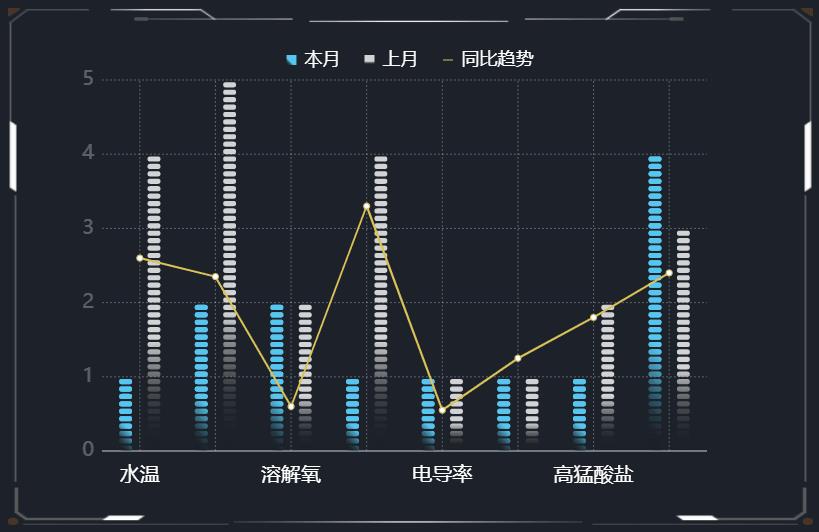
通过同时显示两个不同类型的指标(例如数量和百分比)来比较它们之间的关系。在分组双轴图中,数据被分成两个组,并分别在左右两个轴上显示。左侧轴通常用于表示数量或总数,右侧轴则通常用于表示百分比或比率。
适用场景
分组双轴图适用于需要比较不同类别或组别之间的趋势和变化情况的场景。通常用于比较两组或多组数据在同一时间或同一地点的变化情况,可以同时呈现不同的度量单位或指标,使得数据的比较更加直观和清晰。例如,可以用分组双轴图展示两个产品在同一时间段内的销售额和利润的变化情况,或者展示不同地区的人均收入和生活成本的趋势,适用于:
1.对比分析:分组双轴图适用于对比分析不同数据集之间的差异和相似之处。
2.趋势展示:分组双轴图可以展示数据的趋势变化,可以用于监测业务的发展和趋势。
3.多因素分析:分组双轴图可以同时展示两组或多组数据,可以方便地进行多因素分析。
优缺点
(1)分组双轴图的优点包括:
①可以同时展示多个数据系列,方便比较不同组别之间的数据差异。
②可以展示不同单位或量级的数据,避免数据之间的干扰。
③可以减少图表数量,节省空间,提高信息密度。
(2)分组双轴图的缺点包括:
①当数据分布差异较大时,容易造成一条轴线数据被另一条轴线的数据所掩盖,导致数据无法清晰呈现。
②当数据之间的差异不大时,分组双轴图的优势可能不如其他类型的图表明显。
③分组双轴图的绘制过程较为复杂,需要较高的技术门槛和时间成本。
如何绘制分组双轴图
目前市场上有许多绘制分组双轴图的软件工具,如Excel、Power BI等,可根据实际需要选择合适的工具进行绘制,这里我选用的山海鲸可视化进行绘制。要使用山海鲸可视化绘制分组双轴图,可以按照以下步骤进行操作:
①登录山海鲸可视化平台,创建一个新项目。
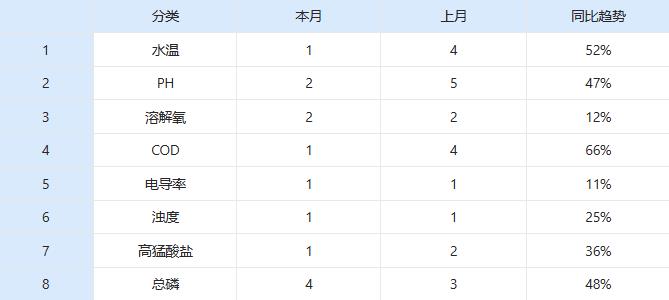
②在数据源页面导入需要绘制的数据,保证数据格式的正确性。
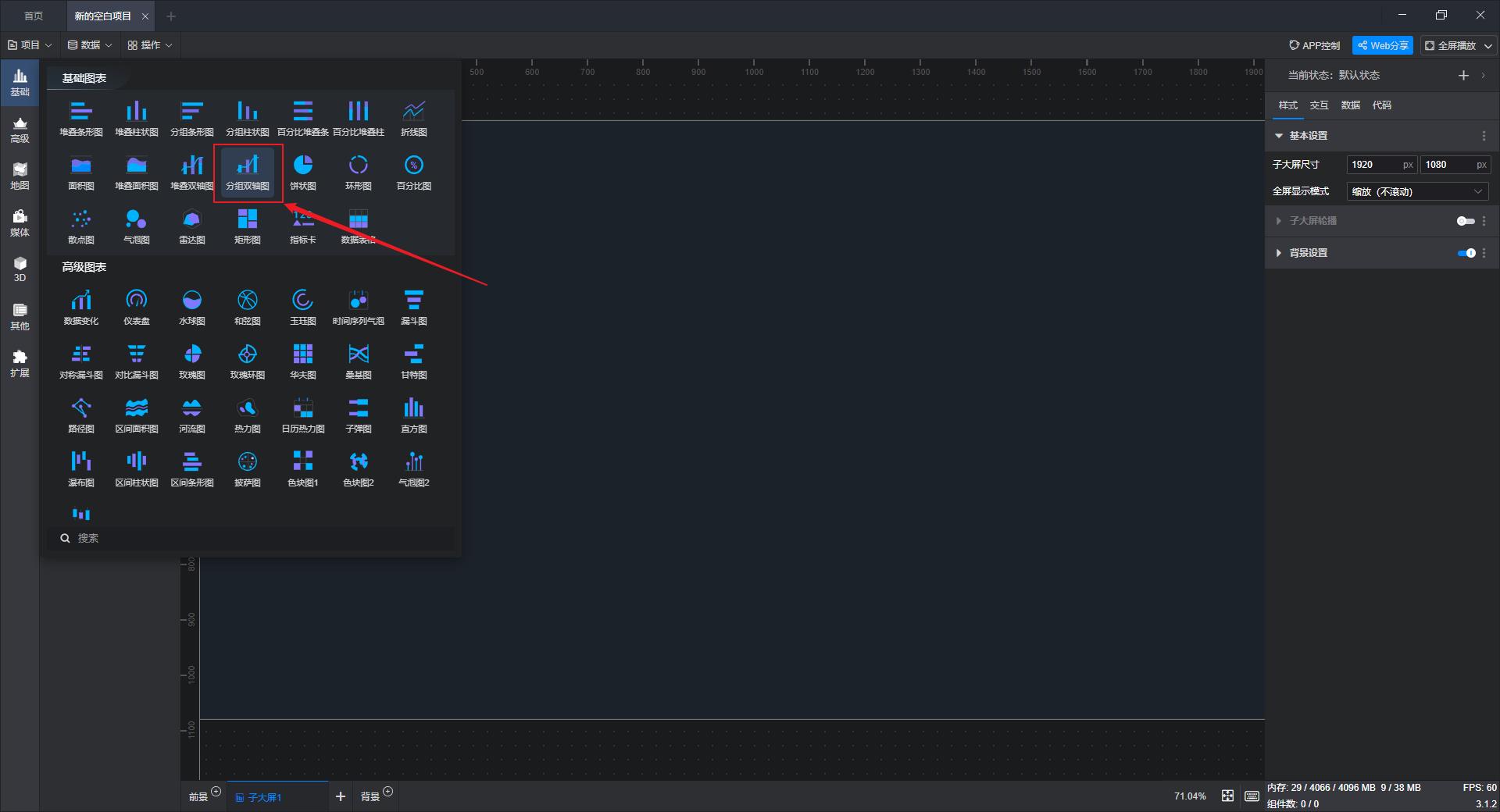
③在图表页面选择“分组双轴图”作为图表类型。
④根据数据源设置图表的数据、颜色、轴等属性,确保数据能够正确地呈现在图表中。
⑤根据需要对图表进行样式调整,包括字体大小、颜色、线条粗细等。
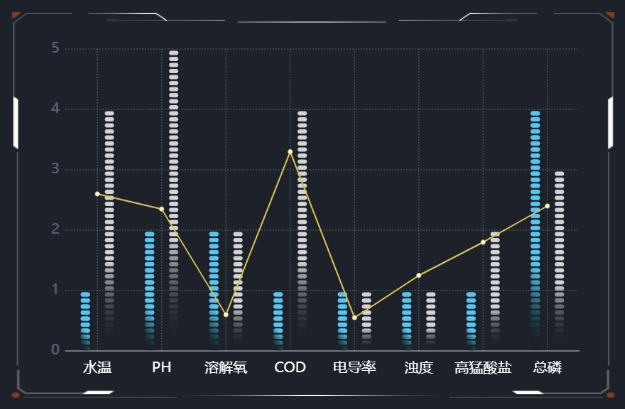
⑥确认图表设置无误后,点击“保存”即可。
需要注意的是,在设置分组双轴图时,要确保每个分组内的数据在横轴上都有对应的标签,这样才能正确地显示在图表中。此外,根据数据的特点,可以考虑使用不同的颜色、样式等来区分不同分组的数据,以便更好地传达信息。
使用山海鲸可视化绘制分组双轴图可以帮助用户更好地展现数据,从而更直观、清晰地表达数据的含义和趋势。
Django:为相同数据的多个视图提供服务的最佳方式是啥,最好为每个视图提供不同的呈现方式?
【中文标题】Django:为相同数据的多个视图提供服务的最佳方式是啥,最好为每个视图提供不同的呈现方式?【英文标题】:Django: What is the best way to serve several views of the same data, preferably rendered differently for each?Django:为相同数据的多个视图提供服务的最佳方式是什么,最好为每个视图提供不同的呈现方式? 【发布时间】:2011-05-27 15:36:42 【问题描述】:有可能吗?
我的问题是,我的主页上有几列,所有这些列都需要显示使用不同过滤器的模型,以及不同的模型。我不想获取模型并在视图中对其进行过滤,然后将它们作为变量传递给包含所有“model1_filterAppliedA”、“model1_filterAppliedB”的主页。这似乎有点矫枉过正。我想要一个很好的方式来说“在此列中显示此模型的此过滤查询集”“在另一列中使用此过滤器显示此其他查询集”。
在 django 中实现这一目标的最佳方法是什么?
谢谢
编辑:
所以经过一段时间的实验;
选项 1:
我有一个看起来像这样的模板标签
@register.inclusion_tag('app/accordion_column.html', takes_context=True)
def accordion_by_filter(context, f):
user = context['request'].user
print "f: " + str(f)
filetered_mobjects = Modell.objects \
.filter(creator=user.userprofile) \
.filter(state=f) \
.order_by('-created')[0:10]
return 'mobjects': filetered_mobjects
然后从我的模板中调用它
% load mytags %
% accordion_by_filter 'A' %
并且手风琴_column.html 扩展了我的其他模板并且只是循环遍历mobjects。 现在,当我需要在 main_column 中显示所有 mobjects 但由 'B' 过滤时,我会做同样的事情,但用accordion_by_filter 'B' 调用它
所以对于索引视图,它具有手风琴列(左侧)main_column 和 right_sidebar。对于要应用的每个过滤器,将对数据库进行三个单独的命中。我认为这没问题,因为另一种选择是获取所有 mobjects 并在结果列表中过滤?
选项 2;过滤器,加载任何模板的视图应该获取所有或一些模型,并将其在变量中铲到模板中,然后通过模板过滤器像普通列表一样过滤。所以这应该是一次访问数据库但结果会更重,并且它的过滤将在模板过滤器中计算多次,而不是告诉数据库这样做。
过滤器:
@register.filter def state(mobjects_list, arg):
filtered = []
for p in mobjects_list:
if p.state == arg:
filtered.append(p)
return filtered
在视图返回我可以做的 mobjects 的任何模板中
for p in mobjects|state:'A'
....
哪个选项更可取,最快?
【问题讨论】:
【参考方案1】:听起来上下文处理器就是你想要的。基本上,您可以编写一个上下文处理器,为每个 RequestContext 添加一些上下文。上下文处理器可能看起来像这样(我通常将它们放在文件 project_directory/app_directory/context_processors.py 中):
from project.app.models import Book
def number_of_books(request):
return 'num_books': Book.objects.all().count()
然后,在项目的 settings.py 中,将此文件添加到 TEMPLATE_CONTEXT_PROCESSORS 元组中:
TEMPLATE_CONTEXT_PROCESSORS = ('app.context_processors.number_of_books', 'other', 'stuff')
最后,您必须让所有视图函数都使用 RequestContext 而不是普通的旧 Context。通用视图自动使用 RequestContext。如果您使用的是 render_to_response,则必须添加一个 context_instance kwarg(此示例中的“名称”只是已在此视图中作为上下文传递的局部变量):
from django.template import RequestContext
def my_view(request):
# ... some code, including assigning the 'name' variable to something ...
return render_to_response("app/template.html", 'name': name,
context_instance=RequestContext(request))
我最喜欢的确保我使用 RequestContext 的方法是使用 django-annoying 的 render_to 装饰器(方便的第三方集合):https://bitbucket.org/offline/django-annoying/wiki/Home
现在,每次渲染模板时,它都会拥有来自其自身视图的所有正常上下文变量以及来自上下文处理器的上下文变量。在我的示例中,您的书店网站可能在每一页的页眉中都有一行写着“现在提供 3,141,592 本书!”假设您有一个名为 base.html 的基本模板,所有其他模板都扩展了它,您可以这样完成它:
<div id="header">
<h1> Cool Online Bookstore </h1>
<p> Now offering num_books books! </p>
</div>
【讨论】:
所有上下文处理器每次在RequestContext被实例化时运行,无论是否需要变量。如果他们总是查询数据库,这很快就会变得非常昂贵。
我在过去的项目中考虑过这一点,但我从来没有真正遇到过由此产生的性能问题(并不是说我创建了任何高流量的网站)。例如,如果您需要一个带有大量来自数据库的最新信息的侧边栏,我不知道有更好或更便宜的方法来做到这一点。有没有更好的办法?显然,缓存会有所帮助,具体取决于您需要信息的最新程度。
有趣的方法 baddox。我正在研究更多使用模板标签,但问题是我必须有一种重复,应用每个过滤器的每个标签,或者我提供一个字符串来过滤一个标签,但是标签将具有“逻辑” - 在哪里输出这些东西,到什么 sn-p。它增加了我不喜欢的各种并发症。但是第一种方法有重复,我也不喜欢。这种方法有点开销。它应该只在某个时候呈现。可以用模板过滤器完成吗?
我没有创建模板标签或过滤器的经验(我只使用内置标签),但在我看来,模板不应该显式访问数据库,甚至不应该知道数据库事情的一面。上下文处理器确实存在每个RequestContext 实例化都会执行它们的问题,所以如果你想做繁重的数据库工作并且只在几页上显示它,它们可能不是要走的路。
基于类的视图可以帮助减少代码重复,但我对这些也缺乏经验。它们计划在 Django 1.3 中正式发布,这里已经有文档:docs.djangoproject.com/en/dev/topics/class-based-views以上是关于优化数据呈现方式,分组双轴图是最佳选择的主要内容,如果未能解决你的问题,请参考以下文章