RocketMq Tag
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMq Tag相关的知识,希望对你有一定的参考价值。
参考技术A • 消息类型是否一致:如普通消息、事务消息、定时(延时)消息、顺序消息,不同的消息类型使用不同的 Topic,无法通过 Tag 进行区分。• 业务是否相关联:没有直接关联的消息,如淘宝交易消息,京东物流消息使用不同的 Topic 进行区分;而同样是天猫交易消息,电器类订单、女装类订单、化妆品类订单的消息可以用 Tag 进行区分。
• 消息优先级是否一致:如同样是物流消息,盒马必须小时内送达,天猫超市 24 小时内送达,淘宝物流则相对会慢一些,不同优先级的消息用不同的 Topic 进行区分。
• 消息量级是否相当:有些业务消息虽然量小但是实时性要求高,如果跟某些万亿量级的消息使用同一个 Topic,则有可能会因为过长的等待时间而“饿死”,此时需要将不同量级的消息进行拆分,使用不同的 Topic。
总的来说,针对消息分类,您可以选择创建多个 Topic,或者在同一个 Topic 下创建多个 Tag。但通常情况下,不同的 Topic 之间的消息没有必然的联系,而 Tag 则用来区分同一个 Topic 下相互关联的消息,例如全集和子集的关系、流程先后的关系。
通过合理的使用 Topic 和 Tag,可以让业务结构清晰,更可以提高效率。
RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的。RocketMQ这么做是在于其Producer端写入消息和Consumer端订阅消息采用分离存储的机制来实现的,Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构。其ConsumeQueue的存储结构如下,可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤正式基于这个字段值的。
Consumer端在订阅消息时除了指定Topic还可以指定TAG,如果一个消息有多个TAG,可以用||分隔。其中,Consumer端会将这个订阅请求构建成一个 SubscriptionData,发送一个Pull消息的请求给Broker端。Broker端从RocketMQ的文件存储层—Store读取数据之前,会用这些数据先构建一个MessageFilter,然后传给Store。Store从 ConsumeQueue读取到一条记录后,会用它记录的消息tag hash值去做过滤,由于在服务端只是根据hashcode进行判断,无法精确对tag原始字符串进行过滤,故在消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费。
我擦,RocketMQ的tag还有这个“坑”
RocketMQ提供了基于Tag的消息过滤机制,但在使用过程中有很多朋友或多或少会有一些疑问,我不经意在RocketMQ官方钉钉群,我记得有好多朋友都有问到如下问题:

今天我就与RocketMQ Tag几个值得关注的问题,和大家来做一个分享,看过后的朋友,如果觉得有帮助,期待你的点赞支持。
-
消费组订阅关系不一致为什么会到来消息丢失?
-
如果一个tag的消息数量很少,是否会显示很高的延迟?
1、消费组订阅关系不一致导致消息丢失
从消息消费的视角来看消费组是一个基本的物理隔离单位,每一个消费组拥有自己的消费位点、消费线程池等。
RocketMQ的初学者容易犯这样一个错误:消费组中的不同消费者,订阅同一个topic的不同的tag,这样会导致消息丢失(部分消息没有消费),在思考这个问题时,我们不妨先来看一张图:

简单阐述一下其核心关键点:
- 例如一个Topic共有4个队列。
- 消息发送者连续发送4条tagA的消息后,再连续发送4条tagb的消息,消息发送者端默认采取轮循的负载均衡机制,这样topic的每一个队列中都存在tagA、tabB两个tag的消息。
- 消费组dw_tag_test的IP为192.168.3.10的消费者订阅tagA,另外一个IP为192.168.3.11的消费者订阅tagB。
- 消费组内的消费者在进行消息消费之前,首先会进行队列负载,默认为平均分配,分配结果:
- 192.168.3.10 分配到q0、q1。
- 192.168.3.11 分配到q2、q3。
- 消费者然后向Broker发起消息拉取请求,192.168.3.10消费者会由于只订阅了tagA,这样存在q0、q1中的tagB的消息会被过滤,但被过滤的tagB并不会投递到另外一个订阅了tagB的消费者,造成这部分消息没有被投递,从而导致消息丢失。
- 同样192.168.3.11消费者会由于只订阅了tagB,这样存在q2、q3中的tagA的消息会被过滤,但被过滤的tagA并不会投递到另外一个订阅了tagA的消费者,造成这部分消息没有被投递,从而导致消息丢失。
2、如果一个tag的消息数量很少,是否会显示很高的延迟?
开篇有群友会存在这样一个担忧,其场景大概如下图所示:

消费者在消费offset=100的这条tag1消息后,后面连续出现1000W条非tag1的消息,这个消费组的积压会持续增加,直接到1000W吗?
要想明白这个问题,我们至少应该要重点去查看如下几个功能的源码:
- 消息拉取流程
- 位点提交机制
本文不准备全流程去分析这块的源码,如果大家对这块代码有兴趣,可以查阅笔者出版的《RocketMQ技术内幕》书籍。
本文将从以问题为导向,经过自己的思考,并找到关键源码加以求证,最后进行简单的示例代码进行验证。
遇到问题之前,我们可以先尝试思考一下,如果这个功能要我们实现,我们大概会怎么去思考?
要判断消费组在消费为offset=100的消息后,在接下来1000W条消息都会被过滤的情况下,如果我们希望位点能够提交,我们应该怎么设计?我觉得应该至少有如下几个关键点:
- 消息消息拉取时连续1000W条消息找不到合适的消息,服务端会如何处理
- 客户端拉取到消息与未拉取到消息两种情况如何提交位点
2.1 消息拉取流程中的关键设计
客户端向服务端拉取消息,连续1000W条消息都不符合条件,一次过滤查找这么多消息,肯定非常耗时,客户端也不能等待这么久,那服务端必须采取措施,必须触发一个停止查找的条件并向客户端返回NO_MESSAGE,客户端在消息查找时会等待多久呢?
核心关键点一:客户端在向服务端发起消息拉取请求时会设置超时时间,代码如下所示:
DefaultMQPushConsumerImpl#pullMessage
try
this.pullAPIWrapper.pullKernelImpl(
pullRequest.getMessageQueue(),
subExpression,
subscriptionData.getExpressionType(),
subscriptionData.getSubVersion(),
pullRequest.getNextOffset(),
this.defaultMQPushConsumer.getPullBatchSize(),
sysFlag,
commitOffsetValue,
BROKER_SUSPEND_MAX_TIME_MILLIS,
CONSUMER_TIMEOUT_MILLIS_WHEN_SUSPEND,
CommunicationMode.ASYNC,
pullCallback
);
catch (Exception e)
log.error("pullKernelImpl exception", e);
this.executePullRequestLater(pullRequest, pullTimeDelayMillsWhenException);
其中与超时时间相关的两个变量,其含义分别:
- long brokerSuspendMaxTimeMillis
在当前没有符合的消息时在Broker端允许挂起的时间,默认为15s,暂时不支持自定义。 - long timeoutMillis
消息拉取的超时时间,默认为30s,暂时不支持自定义。
即一次消息拉取最大的超时时间为30s。
核心关键点二:Broker端在处理消息拉取时设置了完备的退出条件,具体由DefaultMessageStore的getMessage方法事项,具体代码如下所述:
//部分代码截图
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset);
if (bufferConsumeQueue != null)
try
status = GetMessageStatus.NO_MATCHED_MESSAGE;
long nextPhyFileStartOffset = Long.MIN_VALUE;
long maxPhyOffsetPulling = 0;
int i = 0;
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
final boolean diskFallRecorded = this.messageStoreConfig.isDiskFallRecorded();
getResult = new GetMessageResult(maxMsgNums);
ConsumeQueueExt.CqExtUnit cqExtUnit = new ConsumeQueueExt.CqExtUnit();
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE)
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
long tagsCode = bufferConsumeQueue.getByteBuffer().getLong();
maxPhyOffsetPulling = offsetPy;
if (nextPhyFileStartOffset != Long.MIN_VALUE)
if (offsetPy < nextPhyFileStartOffset)
continue;
boolean isInDisk = checkInDiskByCommitOffset(offsetPy, maxOffsetPy);
if (this.isTheBatchFull(sizePy, maxMsgNums, getResult.getBufferTotalSize(), getResult.getMessageCount(),
isInDisk))
break;
核心要点:
- 首先客户端在发起时会传入一个本次期望拉取的消息数量,对应上述代码中的maxMsgNums,如果拉取到指定条数到消息(读者朋友们如体代码读者可以查阅isTheBatchFull方法),则正常退出。
- 另外一个非常关键的过滤条件,即一次消息拉取过程中,服务端最大扫描的索引字节数,即一次拉取扫描ConsumeQueue的字节数量,取16000与期望拉取条数乘以20,因为一个consumequeue条目占20个字节。
- 服务端还蕴含了一个长轮循机制,即如果扫描了指定的字节数,但一条消息都没查询到,会在broker端挂起一段时间,如果有新消息到来并符合过滤条件,则会唤醒,向客户端返回消息。
回到这个问题,如果服务端连续1000W条非tag1的消息,拉取请求不会一次性筛选,而是会返回,不至于让客户端超时。
从这里可以打消第一个顾虑:服务端在没有找到消息时不会傻傻等待不返回,接下来看是否会有积压的关键是看如何提交位点。
2.2 位点提交机制
2.2.1 客户端拉取到合适的消息位点提交机制
Pull线程从服务端拉取到结构后会将消息提交到消费组线程池,主要定义在DefaultMQPushConsumerImpl的PullTask类中,具体代码如下所示:
switch (pullResult.getPullStatus())
case FOUND:
long prevRequestOffset = pullRequest.getNextOffset();
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
long pullRT = System.currentTimeMillis() - beginTimestamp;
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullRT(pullRequest.getConsumerGroup(),
pullRequest.getMessageQueue().getTopic(), pullRT);
long firstMsgOffset = Long.MAX_VALUE;
if (pullResult.getMsgFoundList() == null || pullResult.getMsgFoundList().isEmpty())
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
else
firstMsgOffset = pullResult.getMsgFoundList().get(0).getQueueOffset();
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullTPS(pullRequest.getConsumerGroup(),
pullRequest.getMessageQueue().getTopic(), pullResult.getMsgFoundList().size());
boolean dispatchToConsume = processQueue.putMessage(pullResult.getMsgFoundList());
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);
if (DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval() > 0)
DefaultMQPushConsumerImpl.this.executePullRequestLater(pullRequest,
DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval());
else
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
众所周知,RocketMQ是在消费成功后进行位点提交,代码在ConsumeMessageConcurrentlyService中,如下所示:

这里的核心要点:
- 消费端成功消息完消费后,会采用最小位点提交机制,确保消费不丢失。
- 最小位点提交机制,其实就是将拉取到的消息放入一个TreeMap中,然后消费线程成功消费一条消息后,将该消息从TreeMap中移除,再计算位点:
- 如果当前TreeMap中还有消息在处理,则返回TreeMap中的第一条消息(最小位点)
- 如果当前TreeMap中已没有消息处理,返回的位点为this.queueOffsetMax,queueOffsetMax的表示的是当前消费队列中拉取到的最大消费位点,因为此时拉取到的消息全部消费了。
- 最后调用updateoffset方法,更新本地的位点缓存(有定时持久机制)
2.2.2 客户端没有拉取到合适的消息位点提交机制
客户端如果没有拉取到合适的消息,例如全部被tag过滤了,在DefaultMqPushConsumerImpl的PullTask中定义了处理方式,具体如下所示:
case NO_NEW_MSG:
case NO_MATCHED_MSG:
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
DefaultMQPushConsumerImpl.this.correctTagsOffset(pullRequest);
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
break;
其关键代码在correctTasOffset中,具体代码请看:
private void correctTagsOffset(final PullRequest pullRequest)
if (0L == pullRequest.getProcessQueue().getMsgCount().get())
this.offsetStore.updateOffset(pullRequest.getMessageQueue(), pullRequest.getNextOffset(), true);
核心要点:如果此时处理队列中的消息为0时,则会将下一次拉取偏移量当成位点,而这个值在服务端进行消息查找时会向前驱动,代码在DefaultMessageStore的getMessage中:
if (diskFallRecorded)
long fallBehind = maxOffsetPy - maxPhyOffsetPulling;
brokerStatsManager.recordDiskFallBehindSize(group, topic, queueId, fallBehind);
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
long diff = maxOffsetPy - maxPhyOffsetPulling;
long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE
* (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
getResult.setSuggestPullingFromSlave(diff > memory);
finally
bufferConsumeQueue.release();
else
status = GetMessageStatus.OFFSET_FOUND_NULL;
nextBeginOffset = nextOffsetCorrection(offset, consumeQueue.rollNextFile(offset));
log.warn("consumer request topic: " + topic + "offset: " + offset + " minOffset: " + minOffset + " maxOffset: "
+ maxOffset + ", but access logic queue failed.");
else
status = GetMessageStatus.NO_MATCHED_LOGIC_QUEUE;
nextBeginOffset = nextOffsetCorrection(offset, 0);
if (GetMessageStatus.FOUND == status)
this.storeStatsService.getGetMessageTimesTotalFound().add(1);
else
this.storeStatsService.getGetMessageTimesTotalMiss().add(1);
long elapsedTime = this.getSystemClock().now() - beginTime;
this.storeStatsService.setGetMessageEntireTimeMax(elapsedTime);
// lazy init no data found.
if (getResult == null)
getResult = new GetMessageResult(0);
getResult.setStatus(status);
getResult.setNextBeginOffset(nextBeginOffset);
getResult.setMaxOffset(maxOffset);
getResult.setMinOffset(minOffset);
return getResult;
故从这里可以看到,就算消息全部过滤掉了,位点还是会向前驱动的,不会造成大量积压。
2.2.3 消息拉取时会附带一次位点提交
其实RocketMQ的位点提交,客户端提交位点时会先存储在本地缓存中,然后定时将位点信息一次性提交到Broker端,其实还存在另外一种较为隐式位点提交机制:
boolean commitOffsetEnable = false;
long commitOffsetValue = 0L;
if (MessageModel.CLUSTERING == this.defaultMQPushConsumer.getMessageModel())
commitOffsetValue = this.offsetStore.readOffset(pullRequest.getMessageQueue(), ReadOffsetType.READ_FROM_MEMORY);
if (commitOffsetValue > 0)
commitOffsetEnable = true;
String subExpression = null;
boolean classFilter = false;
SubscriptionData sd = this.rebalanceImpl.getSubscriptionInner().get(pullRequest.getMessageQueue().getTopic());
if (sd != null)
if (this.defaultMQPushConsumer.isPostSubscriptionWhenPull() && !sd.isClassFilterMode())
subExpression = sd.getSubString();
classFilter = sd.isClassFilterMode();
int sysFlag = PullSysFlag.buildSysFlag(
commitOffsetEnable, // commitOffset
true, // suspend
subExpression != null, // subscription
classFilter // class filter
);
try
this.pullAPIWrapper.pullKernelImpl(
pullRequest.getMessageQueue(),
subExpression,
subscriptionData.getExpressionType(),
subscriptionData.getSubVersion(),
pullRequest.getNextOffset(),
this.defaultMQPushConsumer.getPullBatchSize(),
sysFlag,
commitOffsetValue,
BROKER_SUSPEND_MAX_TIME_MILLIS,
CONSUMER_TIMEOUT_MILLIS_WHEN_SUSPEND,
CommunicationMode.ASYNC,
pullCallback
);
catch (Exception e)
即在消息拉取时,如果本地缓存中存在位点信息,会设置一个系统标记:FLAG_COMMIT_OFFSET,该标记在服务端会触发一次位点提交,具体代码如下:
boolean storeOffsetEnable = brokerAllowSuspend;
storeOffsetEnable = storeOffsetEnable && hasCommitOffsetFlag;
storeOffsetEnable = storeOffsetEnable
&& this.brokerController.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE;
if (storeOffsetEnable)
this.brokerController.getConsumerOffsetManager().commitOffset(RemotingHelper.parseChannelRemoteAddr(channel),
requestHeader.getConsumerGroup(), requestHeader.getTopic(), requestHeader.getQueueId(), requestHeader.getCommitOffset());
return response;
2.2.4 总结与验证
综上述所述,使用TAG并不会因为对应tag数量比较少,从而造成大量积压的情况。
为了验证这个观点,我也做了一个简单的验证,具体方法是启动一个消息发送者,向指定topic发送tag B的消息,而消费者只订阅tag A,但消费者并不会出现消费积压,测试代码如下图所示:
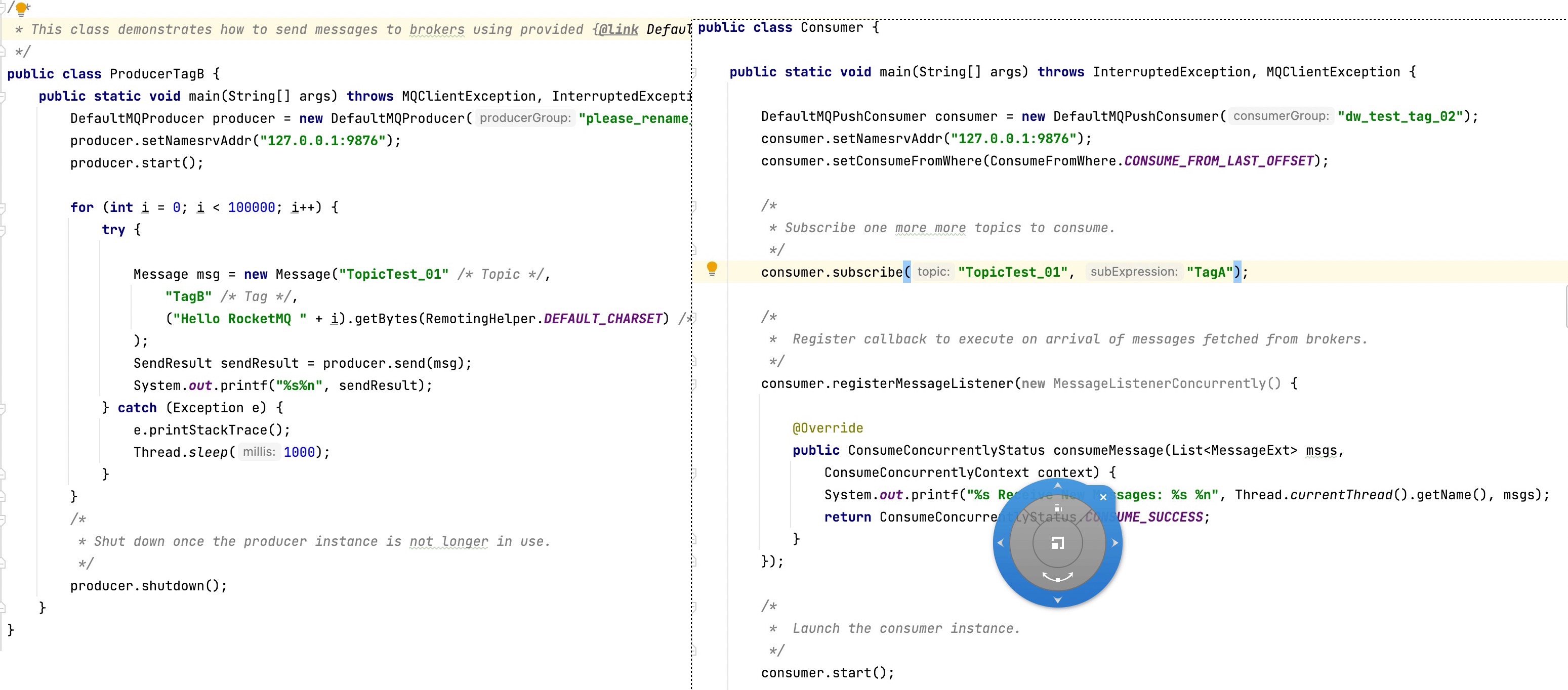
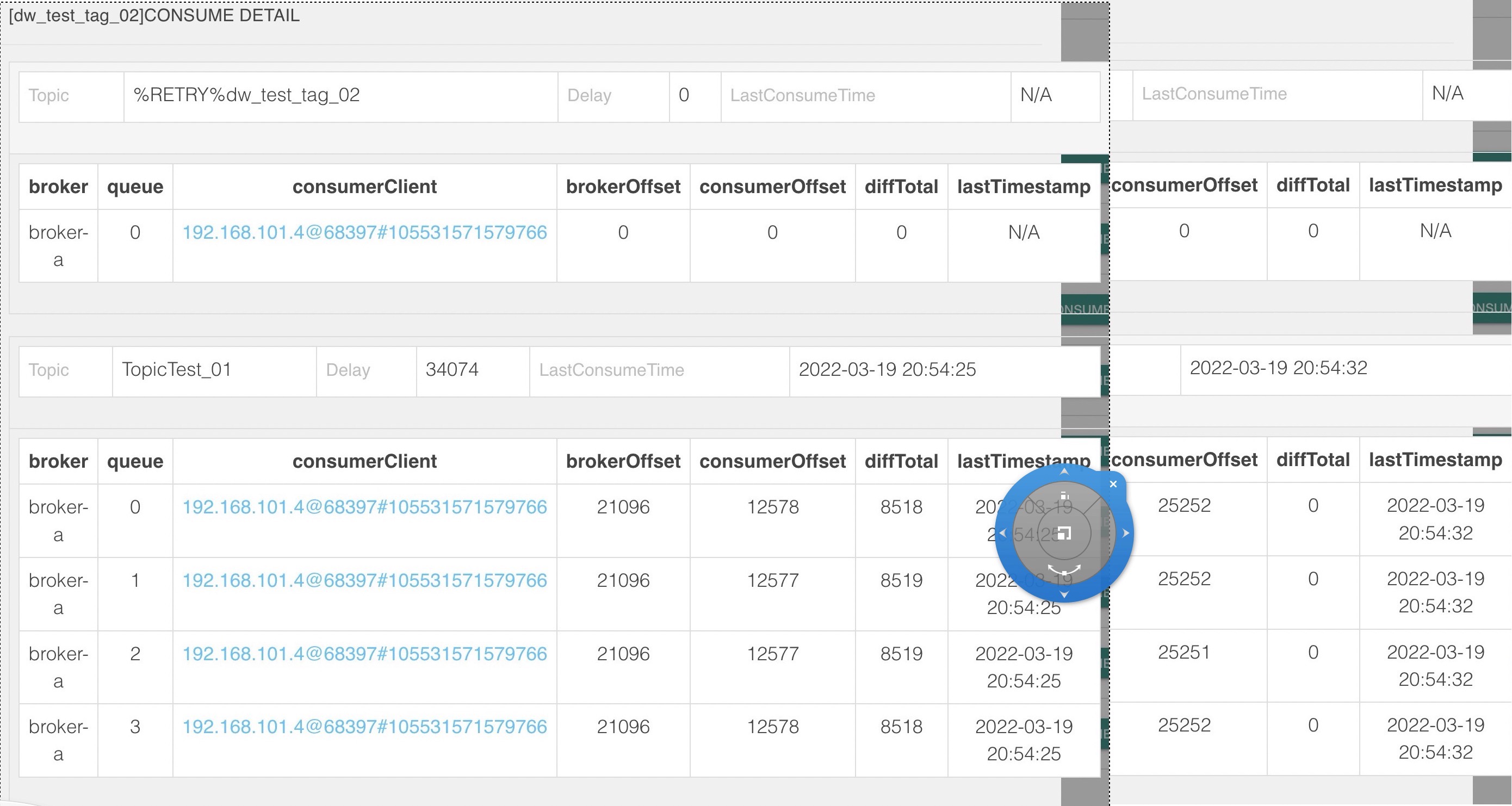
查看消费组积压情况如下图所示:
一键三连(关注、点赞、留言)是对我最大的鼓励。
各位技术朋友们,我是《RocketMQ技术内幕》一书作者,CSDN2020博客之星TOP2,热衷于中间件领域的技术分享,维护「中间件兴趣圈」公众号,旨在成体系剖析Java主流中间件,构建完备的分布式架构体系,欢迎大家大家关注我,回复「专栏」可获取15个专栏;回复「PDF」可获取海量学习资料,回复「加群」可以拉你入技术交流群,零距离与BAT大厂的大神交流。
以上是关于RocketMq Tag的主要内容,如果未能解决你的问题,请参考以下文章