在Hadoop上用Python实现WordCount
Posted one-smile
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在Hadoop上用Python实现WordCount相关的知识,希望对你有一定的参考价值。
在hadoop上用Python实现WordCount
一、简单说明
本例中我们用Python写一个简单的运行在Hadoop上的MapReduce程序,即WordCount(读取文本文件并统计单词的词频)。这里我们将要输入的单词文本input.txt和Python脚本放到/home/data/python/WordCount目录下。
cd /home/data/python/WordCount
vi input.txt
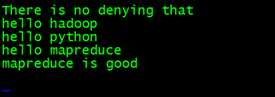
输入:
There is no denying that
hello python
hello mapreduce
mapreduce is good
二、编写Map代码
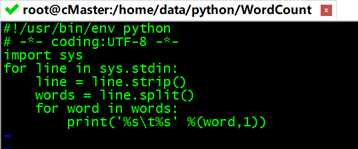
这里我们创建一个mapper.py脚本,从标准输入(stdin)读取数据,默认以空格分隔单词,然后按行输出单词机器词频到标准输出(stdout),整个Map处理过程不会统计每个单词出现的总次数,而是直接输出“word 1”,以便作为Reduce的输入进行统计,确保该文件是可执行的(chmod +x /home/data/python//WordCount/mapper.py)。
cd /home/data/python//WordCount
vi mapper.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
#输入为标准输入stdin
for line in sys.stdin:
#删除开头和结尾的空格
line = line.strip()
#以默认空格分隔行单词到words列表
words = line.split()
for word in words:
#输出所有单词,格式为“单词,1”以便作为Reduce的输入
print(‘%s %s‘ %(word,1))
#截图如下:
三、编写Reduce代码
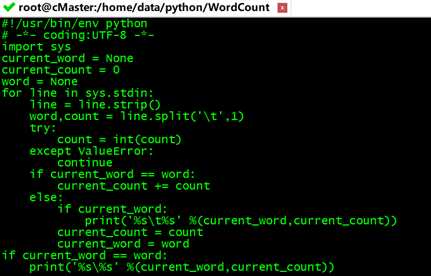
这里我们创建一个reducer.py脚本,从标准输入(stdin)读取mapper.py的结果,然后统计每个单词出现的总次数并输出到标准输出(stdout),
确保该文件是可执行的(chmod +x /home/data/python//WordCount/reducer.py)
cd /home/data/python//WordCount
vi reducer.py
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
current_word = None
current_count = 0
word = None
#获取标准输入,即mapper.py的输出
for line in sys.stdin:
#删除开头和结尾的空格
line = line.strip()
#解析mapper.py输出作为程序的输入,以tab作为分隔符
word,count = line.split(‘ ‘,1)
#转换count从字符型为整型
try:
count = int(count)
except ValueError:
#count不是数据时,忽略此行
continue
#要求mapper.py的输出做排序操作,以便对连接的word做判断,hadoop会自动排序
if current_word == word:
current_count += count
else:
if current_word:
#输出当前word统计结果到标准输出
print(‘%s %s‘ %(current_word,current_count))
current_count = count
current_word = word
#输出最后一个word统计
if current_word == word
print(‘%s\\%s‘ %(current_word,current_count))
#截图如下:
四、本地测试代码
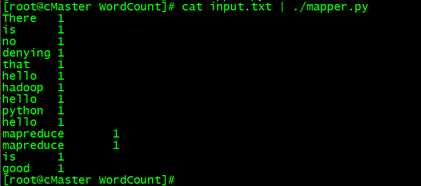
我们可以在Hadoop平台运行之前在本地测试,校验mapper.py与reducer.py运行的结果是否正确。注意:测试reducer.py时需要对mapper.py的输出做排序(sort)操作,不过,Hadoop环境会自动实现排序。
#在本地运行mapper.py:
cd /home/data/python/WordCount/
#记得执行: chmod +x /home/data/python//WordCount/mapper.py
cat input.txt | ./mapper.py
#在本地运行reducer.py
#记得执行:chmod +x /home/data/python//WordCount/reducer.py
cat input.txt | ./mapper.py | sort -k1,1 | ./reducer.py
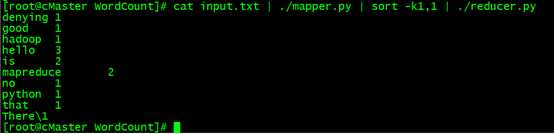
五、在Hadoop平台上运行代码
在hadoop运行代码,前提是已经搭建好hadoop集群
1、创建目录并上传文件
首先在HDFS上创建文本文件存储目录,这里我创建为:/WordCound
hdfs dfs -mkdir /WordCound
#将本地文件input.txt上传到hdfs的/WordCount上。
hadoop fs -put /home/data/python/WordCount/input.txt /WordCount
hadoop fs -ls /WordCount #查看在hdfs中/data/WordCount目录下的内容
2、执行MapReduce程序
为了简化我们执行Hadoop MapReduce的命令,我们可以将Hadoop的hadoop-streaming-3.0.0.jar加入到系统环境变量/etc/profile中,在/etc/profile文件中添加如下配置:
首先在配置里导入hadoop-streaming-3.0.0.jar
vi /etc/profile
HADOOP_STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.0.0.jar
export HADOOP_STREAM
source /etc/profile #刷新配置
#执行以下命令:
hadoop jar $HADOOP_STREAM -file /home/data/python/WordCount/mapper.py -mapper ./mapper.py -file /home/data/python/WordCount/reducer.py -reducer ./reducer.py -input /WordCount -output /output/word1
得到:
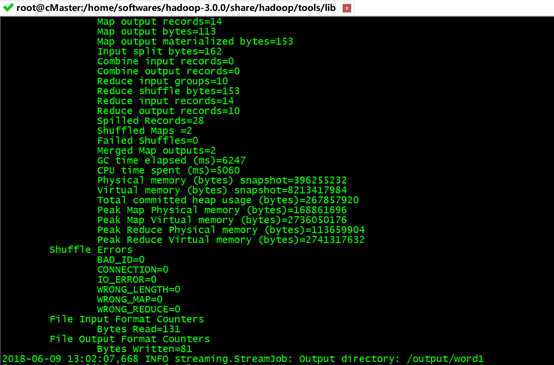
然后,输入以下命令查看结果:
hadoop fs -ls /output/word1
hadoop fs -cat /output/word1/part-00000 #查看分析结果
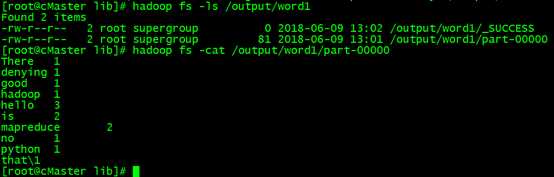
可以发现,结果与之前测试的时候是一致的,那么恭喜你,大功告成!
以上是关于在Hadoop上用Python实现WordCount的主要内容,如果未能解决你的问题,请参考以下文章