华为云GaussDB支撑华为MetaERP系统全面替换
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了华为云GaussDB支撑华为MetaERP系统全面替换相关的知识,希望对你有一定的参考价值。
摘要:目前MetaERP已经覆盖了华为公司100%的业务场景和80%的业务量。
本文分享自华为云社区《强渡大渡河!华为云GaussDB支撑华为MetaERP系统全面替换》,作者: 华为云头条。
近日,在“英雄强渡大渡河”MetaERP表彰会上,华为宣布实现自主可控的MetaERP研发,并完成对旧ERP系统的替换,目前MetaERP已经覆盖了华为公司100%的业务场景和80%的业务量。
这场攻坚战,是华为有史以来牵涉面最广、复杂性最高的项目。三年来,华为投入数千人,联合产业伙伴和生态伙伴攻坚克难,研发出面向未来的超大规模云原生的MetaERP,并成功完成对旧有ERP系统的替换。
史诗级攻坚战,堪比ERP界珠峰
华为董事、质量与流程IT部总裁陶景文在表彰会提道:“ERP作为华为企业经营最核心的系统,支撑了华为20多年的快速发展,支撑了每年数千亿产值的业务,支撑了全球170+国家业务高效经营,一旦出问题,相当于自身运行的神经系统出了问题,公司基本业务运转面临瘫痪风险,这道影响企业经营生存的‘大渡河’突然横亘在前,我们已经没有退路,‘强渡大渡河’成为唯一选择。”
作为全球数据库应用场景最复杂的ERP系统,华为集团老ERP系统存在灵活性差、对业务需求响应慢、不够智能等问题,具体可以用两个“超级”来形容,第一个超级是 “超级账本”,其主要具备三个特征:
- 数据海量
各类应用与ERP的逻辑集成点3950个、数据集成点高达27000个。ERP系统每天处理海量业务和数据,如销售订单行76万,应付开票行21万,会计分录行1500万。业务极度复杂,而且账本的业务量几乎是业界第一,对存储空间的要求非常高。
- 实时自动要求
ERP运行业务场景多达2000个,数据处理量高达160TB,千万级流量洪峰,实时要求高。而老ERP账本记账是非实时的,平均每10分钟记账一次,账单多了还要排队等待,严重影响了业务账单的实时性。
- 强一致性
承载250+会计核算场景,140+个核算模板,3000+核算规则, 实现海外100+子公司多准则适配,可以做到面向企业业务规则实现灵活编排,每次有国家会计准则做了变化不用IT改程序直接可以调整,对账本的准确性、灵活性和一致性要求极高。
第二个超级是“超级高铁”。因为信息断点太多,往常一个客户履行订单流程晚则两三个月长则半年,流效非常慢。而“超级高铁”的使命和责任就是把整个订单的履行流程实时动态跑起来,不再逢站就等,一等几个小时。
勇攀珠峰,华为云GaussDB通过终极考验
面对这场高难度的攻坚战,华为基于云原生、元数据多租、实时智能等新技术,打造面向未来的下一代企业核心商业系统,让企业运营更安全、更高效。华为云GaussDB作为智能数据底座,成功支撑华为集团新MetaERP系统实现全栈自主可控,支持业务需求快速响应、经营决策科学高效、应用数据安全可信。
▎按需弹性扩展,海量数据超高包容性
- 华为云GaussDB采用GTM-Lite技术,计算与存储可自由水平扩展,可以根据业务压力动态伸缩读节点,读吞吐量提升2倍,主/读节点间数据同步秒级时延;
- 容量可以从单库TB级扩展到PB级数据,让MetaERP系统的存储空间达到空前规模;
- 支持业务压力自动负载均衡,解决了传统数据库扩展性不足的问题,轻松应对MetaERP海量数据存储和并发访问压力,支撑超大规模业务。
▎先进存储引擎护航,性能稳定无抖动
频繁的查询业务必然需要系统在面对成倍并发量时性能依然稳定。华为集团采用华为云GaussDB,会计分录峰值处理3000万笔/天,从30分钟延时改进到实时处理。
- 华为云GaussDB的大并发线程池技术,不仅能提高系统响应速度,还能最大程度节省资源;
- 全新上线的Ustore存储引擎,将“有效数据”与“垃圾数据”分离存储,同时采用多版本索引技术,有效提升了存储空间的效率和性能,相比常规引擎,GaussDB性能抖动降低70%,整体性能提升10%以上。
▎高可用容灾部署,业务牢靠不掉线
华为云GaussDB提供同城AZ内、跨AZ、异地跨Region的两地三中心容灾方案和1000公里以上的城市级容灾能力,支持流式容灾,突破基于物理日志的并行复制技术,支撑MetaERP异地跨云部署。
- 在业务发生故障时保障数据安全性,当故障不可避免发生后,跨AZ切换时间短于1分钟,城市级故障实现分钟级恢复;
- 通过三副本数据强一致技术,安全守护每一笔存货交易的准确记录,SLA服务高达99.99%,交易成功率100%,真正达到了“数据零丢失、业务永在线”。
▎打造迁移工具链,让切换高效可靠
为了保障“业务无感、数据不丢、报告准确”,MetaERP基于华为云数据复制服务DRS,35小时完成高度关联的3200亿行数据搬迁验证,利用周末时间完成ERP搬迁,不影响企业正常运转;同时通过并行验证将生产环境业务流量实时导入新系统,用真实场景验证,做到上线后“0”缺陷。
全新突破,业务效率倍数提升
经过三年紧锣密鼓的开发和测试验证,华为云GaussDB成功助力MetaERP系统迁移,整个过程高效、无感、安全。MetaERP系统覆盖了华为100%的业务场景和80%的业务量,经历了月结、季结和年结的考验,年报及时准确发布的同时,实现了零故障、零延时、零调账。
从最直观的表现来看,上线后的新ERP系统马力全开,各项性能和指标远远超过预期,相比原有系统得到显著提升。采购履行耗时从90分钟缩短到15秒,端到端订单履行耗时从23分钟缩短到9秒,在历史峰值5倍压力下性能依然稳定不下降。
实践证明,华为云GaussDB完全经受住了这场世界级的攻坚考验,也完全具备支撑如此大型一体机系统迁移上云的能力和经验。
面向未来,华为将继续围绕“极简架构、极高质量、极低成本、极优体验”的目标,在ERP、PLM等领域,和伙伴一起打造更加高效安全的企业核心商业系统。华为云GaussDB也将持续技术创新,用技术力量提升企业服务质量、效率、体验,保障企业业务永在线。
华为云GaussDB(for Influx)揭密:数据分级存储
本文分享自华为云社区《华为云GaussDB(for Influx)揭密第六期:数据分级存储》,作者:高斯Influx官方博客 。
“只存储这些数据一年就要花费200多万?”
面对老板的质疑,小王又重新讲解了一遍评估方案。为了支撑生产分析和系统运维,一个设备就需要几十个检测点数据,所有设备24小时不断采集数据,一天的数据量就会达到TB级,这些数据至少存储2年,再加上高可用的3副本,总的数据量会达到PB级。
小王又展示了当前云厂商存储价格和性能对比的调研结果:
| 磁盘类型 | SATA | NVME |
|---|---|---|
| 成本100G/月 | 9.9 | 100 |
| IOPS | 2200 | 50000 |
| 吞吐量 | 50M/s | 350M/s |
| 访问时延 | 5ms~10ms | 1ms |
不同存储其性能差异很大。例如NVME盘的吞吐量是SATA盘的7倍,IOPS超过了20倍,当然对应的成本也高出10倍左右。根据测试评估,低成本的存储性能无法满足大量数据的写入和实时业务的监控,只得使用性能高的SSD盘,因此导致存储的成本提高。
成本提高,老板自然不满意。那如何才能既满足性能需求,又能控制成本呢?小王想,“实际上,不是所有的数据处理都需要很高的性能,如果把价值高的数据放在高性能磁盘上满足业务需求,价值低的数据放在低成本磁盘上降低成本,这样不就既能满足需求,又能降低成本了么?”
不过,想法很美好,现实很残酷,要实现这个方案,小王面临着更多的难题:
(1)怎么在一套系统中既能使用高性能存储,又能使用低成本存储?
(2)怎么区分高价值数据?
(3)高价值数据变成低价值数据后怎么自动转储?
(4)当前业务改造量要尽量少。
1. GaussDB(for Influx)解决方案
企业的数字化转型,数据是基础。为了能实时掌握设备、系统状态,需要采集大量的数据并进行实时处理。这些数据都属于时序数据,带有明显的特点,如时间戳、更新少、数据源唯一等。除了数据本身的特点,在业务应用上还具有如下特点:
-
随着时间的推移,其被查询和分析的概率越来越低。
-
随着时间的推移,对数据分析的实时性要求越来越低。
-
随着时间的推移,数据的精度要求越来越低。
-
数据只保留一段时间,到期后会删除。
如何结合时序数据的特点,实现小王既满足业务性能,又控制成本的美好愿望呢?华为云GaussDB(for Influx)时序数据库的数据分级存储功能完美解决了困扰小王的问题。
1、华为云GaussDB(for Influx)依托云原生能力,实现了计算存储分离的分布式架构,其中存储基于华为分布式存储DFV和对象存储OBS,解决了在一套系统中既能使用高性能存储,又能使用低成本存储的问题,其具体架构如下图:
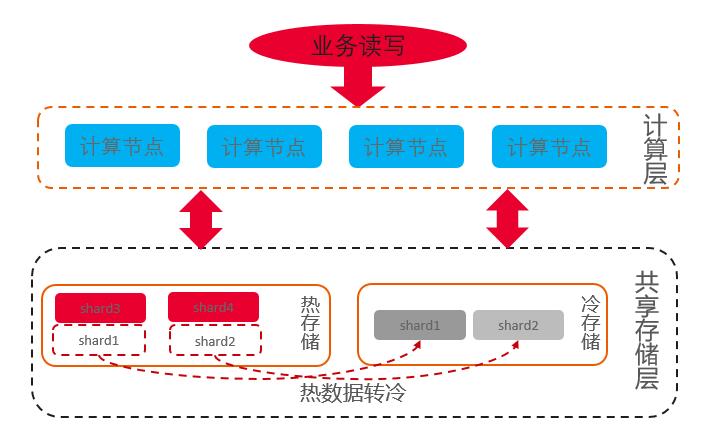
分布式DFV存储属于高性能存储,热数据放在DFV中确保业务性能要求;OBS存储属于低成本存储,冷数据存储在OBS中,降低客户成本。
2、提供了冷热数据自动分离的方案,用户在创建保留策略时,可以指定冷热数据的划分时间,系统根据用户的指定,自动将数据分为热数据和冷数据,解决了数据如何划分的问题。
3、随着时间的推移,热数据转冷,系统会自动将数据转储到冷存储上。
4、上述过程中只有在创建RP时需要指定冷热数据策略。对于业务侧是不感知的,避免业务的适配和改造。
2. GaussDB(for Influx)冷热存储的使用
GaussDB(for Influx)存储分级功能使用十分方便,在购买冷存储后,设置RP策略时指定冷存储的时间即可,系统会根据RP策略,自动将冷数据转储到低成本存储上。业务在访问冷数据时,系统会自动去冷存储上读取,整个过程业务是不感知的,对业务无影响。
2.1 购买冷存储
GaussDB(for Influx)支持一键购买冷存储空间,可以在购买实例时选择是否够买冷存储,选择“是”,可以根据业务需求选择冷存储的大小,具体如下图:

也可以在购买实例后,独立购买冷存储。进入实例详情页面,点击创建冷存储空间,如下图:

跳转到如下页面,按照业务需求进行存储空间大小选择:
冷存储空也支持在线扩容,扩容过程中不影响业务。
2.2 购买冷存储
在购买了冷存储空间后,就可以按照业务需求设置冷数据的规则,系统会根据规则,自动划分冷热数据,并将冷数据存储在冷存储空间上。可以通过创建RP来指定冷热数据规则,具体示例如下:
// 在db名为mydb上创建名为myrp的RP,显示指定WARM DURATION为6d,表示6天前的数据是冷数据。
create retention policy myrp on mydb duration 30d replication 1 warm duration 6d shard duration 3d
// 在db名为mydb上创建名为myrp的RP,没有指定WARM DURATION,表示没有冷数据。
create retention policy myrp on mydb duration 30d replication 1 shard duration 3d
// 创建名为mydb的db,并带有名为myrp的RP,显示指定WARM DURATION为3d,表示3天前的数据是冷数据。
create database mydb with duration 6d warm duration 3d name myrp
// 修改WARM DURATION为7d,表示7天前的数据是冷数据。
alter retention policy myrp on mydb warm duration 7d
规则设置完成后,系统会根据指定的规则,自动判断哪些数据属于冷数据,并自动将数据转储到冷存储上。
2.3 购买冷存储
冷数据规则设置好,插入数据一段时间后,系统会自动判断数据是否转为冷数据,如果已经成为冷数据,系统会自动将数据转储到冷存储上。可以通过show shards命令来查看数据的状态,如下图所示:
> show shards
name: hsdb
id database retention_policy shard_group start_time end_time expiry_time owners tier
-- -------- ---------------- ----------- ---------- -------- ----------- ------ ----
5 hsdb myrp 2 2019-08-12T00:00:00Z 2019-08-19T00:00:00Z 2019-08-19T00:00:00Z 4 cold
6 hsdb myrp 2 2019-08-12T00:00:00Z 2019-08-19T00:00:00Z 2019-08-19T00:00:00Z 5 moving
7 hsdb myrp 2 2019-08-12T00:00:00Z 2019-08-19T00:00:00Z 2019-08-19T00:00:00Z 6 warm
8 hsdb myrp 2 2019-08-12T00:00:00Z2019-08-19T00:00:00Z 2019-08-19T00:00:00Z 7
cold:表示数据为冷数据,已存储在冷存储中;
moving:表示数据为冷数据,该数据正在转储到冷存储中;
warm:表示数据为热数据。
3. 总结
在应用了GaussDB(for Influx)的冷热分级存储方案后,存储100T的数据量一年,按照1个月内的数据是热数据,其余是冷数据,其总体的存储成本从250万降至37.5万,可节省85%的存储成本。
GaussDB(for Influx)除了冷热分级存储功能外,在集群化、读写性能、压缩率、高可用方面也做了深度优化,能更好地满足时序应用的各种场景。
以上是关于华为云GaussDB支撑华为MetaERP系统全面替换的主要内容,如果未能解决你的问题,请参考以下文章
揭秘GaussDB(for Redis):全面对比Codis