Niagara是啥意思
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Niagara是啥意思相关的知识,希望对你有一定的参考价值。
Niagara 是Tridium公司所研发的设计用于解决设备连接应用的软件框架平台技术。Niagara是一种应用框架,或者说是软件框架,特别设计用于应对智能设备所带来的各种挑战,包括设备连接到企业级的应用,支持互联网的产品和基于互联网自动化系统的开发。 参考技术A Niagara
[英][naɪ'æɡərə][美][naɪ'æɡərə]
n.尼亚加拉河(在加拿大和美国间)急流,洪水;
例句:
1.
The family also visited philadelphia, boston and niagara falls.
他们全家还去了费城、波士顿和尼亚加拉瀑布。
2.
Today the backwater has turned into niagara falls.
在今天,那过去的一潭死水已蜕变为尼亚加拉瀑布。本回答被提问者和网友采纳 参考技术B niagara [英]naɪ'æɡərə
[美]naɪ'æɡərə
n. 尼亚加拉河(在加拿大和美国间)急流,洪水
[例句]The family also visited philadelphia , boston and niagara falls.
他们全家还去了费城、波士顿和尼亚加拉瀑布。
[ue4] Niagara的Indirect Draw
| [本文大纲] 概念引入 数据概述 Indirect Draw Buffer Instance Count Buffer FreeIDList Buffer 粒子的更新 粒子的排序和剔除 粒子的绘制 整体流程 |
概念引入
Niagara是完全使用GPU驱动的粒子系统,包括了Mesh粒子、Sprite粒子和Ribbon粒子。
简单来说,它将调用图形API提供的IndirectDraw接口进行间接绘制。之所以称为间接绘制,是因为数据并不是直接由CPU显式传递给GPU的,而是间接引用了GPU构造的数据。我们可以选择在计算着色器中完成粒子的发射和顶点相关数据的填充。
因此,Niagara GPU粒子实现的绝大部分逻辑,都是在准备Indirect Draw所需的缓冲区数据,如Indirect Draw Buffer,以及Instance Buffer,前者提供了间接绘制所需的数据,后者提供了粒子绘制本身所需的数据。理解了这一点,将有助于我们理解后续的逻辑。
本文将从Niagara系统涉及到的几个缓冲区开始介绍,并在此基础上,深入粒子更新、排序、剔除、绘制的流程,最终回顾粒子在整个管线的流程。
数据概述
在整个Niagara更新流程中,涉及到了较多Buffer数据,可以对以下数据有一个初步的了解:
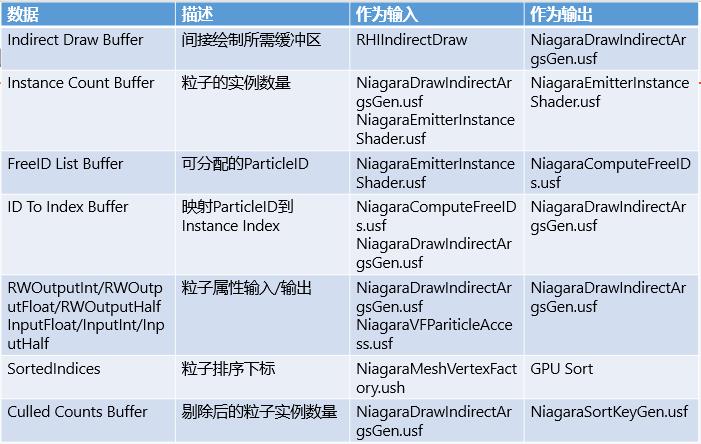
Indirect Draw Buffer
调用Indirect draw的图形绘制接口时,需要构造一个固定的IndirectArg缓冲区。这个缓冲区有固定的五位数据,是由图形API定义的必须填充的结构。每个结构对应着一次Indirect Draw的调用。
缓冲区结构
可以参考DirectX中间接参数缓冲结构的定义:

ue4使用了IndirectDraw的索引实例绘制模式,并且仅填充了每个实例的索引数量(IndexCountPerInstance)、实例的数量(InstanceCount)以及索引的起始位置(StartIndexLocation),后两位设置为0。
RWDrawIndirectArgs[ArgOffset + 0] = TaskInfos[InfoOffset + 1];
// NumIndicesPerInstance
RWDrawIndirectArgs[ArgOffset + 1] = InstanceCount;
RWDrawIndirectArgs[ArgOffset + 2] = TaskInfos[InfoOffset + 2];
// StartIndexLocation
RWDrawIndirectArgs[ArgOffset + 3] = 0;
// BaseVertexLocation
RWDrawIndirectArgs[ArgOffset + 4] = 0;
// StartInstanceLocation实例的数量从GPU Buffer中读取,而索引数量和索引位置则在CPU中完成填充。这里的索引语义和直接绘制的索引语义一致。比如对于Mesh粒子而言,它和模型本身有关,索引计数为模型三角面的数量*3。
IndexInfoPerSection[SectionIdx].Key = MeshLod.Sections[SectionIdx].NumTriangles * 3;
IndexInfoPerSection[SectionIdx].Value = MeshLod.Sections[SectionIdx].FirstIndex;这里的Key和Value分别对应了IndexCountPerInstance和StartIndexLocation。
执行逻辑
Indirect Draw Arg的填充通过计算着色器完成,相关的逻辑位于NiagaraDrawIndirectArgsGen.usf。
Indirect Draw任务在收集动态粒子图元的时候(AddMeshBatch)添加,收集动态粒子的同时会绑定Indirect Draw Buffer的位置,但此时这个缓冲区尚未初始化。
缓冲区的填充发生在Niagara Emitter CS的计算之后,因为它依赖于粒子更新的Instance Count;此外,由于粒子可能包含GPU剔除,这会影响Indirect Draw参数的生成结果,所以Buffer的填充也需要在粒子排序和剔除的流程之后。

填充Indirect Draw会和Instance Count的重置这两个任务,将会打包到同一个cs的不同线程中完成。
Instance Count Buffer
Indirect Draw Buffer依赖于Instance Count数据,这个数据和场景中的粒子存在关联,因此我们需要维护一个Instance Count Buffer。
Buffer的读写
在每个Niagara CS中以指定的偏移值向Instance Count Buffer写入当前Emitter的Instance Count;并在IndirectDraw参数生成的任务中将Instance Count Buffer作为输入,用于填充Indirect Draw Buffer。
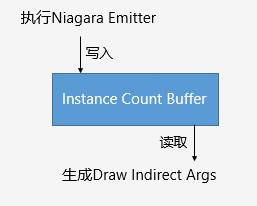
Instance Count有两处写入的位置:
① Emitter更新时写入对应的Instance Count;
② 移除Emitter或者重置Emitter时,将对应的Instance Count重置为0;
如上一节所提,Instance Count的写入发生在Niagara CS执行时,而重置发生在收集完MeshBatch以及粒子排序之后。
Buffer的扩充
由于粒子发射器在运行时会动态的增加删除,因此我们的Instance Count Buffer也是可变的。
为了避免频繁的扩充Buffer,我们在初始化的时候会分配一个相对大的缓冲区,即确保缓冲区为所需大小的特定倍数,且大小不得小于特定大小。
const int32 RecommendedInstanceCounts = FMath::Max(GNiagaraMinGPUInstanceCount,
(int32)(RequiredInstanceCounts * GNiagaraGPUCountBufferSlack));一旦Buffer超过了上限,我们就需要重新分配新的大小的Instance Count Buffer。我们将新的Buffer初始化为0,并将旧的数据拷贝到新的Buffer中。
ue4并没有实现缩小Buffer的逻辑,因此Instance Count Buffer的大小受限于场景中出现的最多粒子数。
Buffer的分配
每个Emitter对应了一个偏移值,用于索引当前emitter在Instance Count Buffer中的位置。
一般情况下,这个偏移值将在已分配的Buffer大小内,按顺序分配。
考虑到粒子是动态创建删除的,因此会有一些粒子被销毁,不再需要对应的Count计数。为了合理地利用这些碎片,ue4维护了FreeEntry数组,它存储了已被释放的空余Instance Count Buffer的偏移。
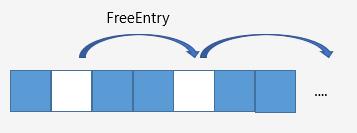
FreeIDList Buffer
和FreeID相关的有两个Buffer,包括FreeIDListSizesBuffer以及FreeIDList。
FreeIDListSizesBuffer记录了每组粒子的空闲数量;FreeIDList则收集了空闲的粒子ID。它将用于粒子更新时,分配对应的ParticleID。每组FreeIDList对应一个FreeIDListSize。
在每个发射器的最后一组粒子的计算完成后,会清除ID列表大小,并对其进行更新。以确保粒子模拟分配的位置尽可能的紧密排布。
在UpdateFreeIDBuffers中,我们更新这两个buffer。其中,对于RWFreeIDListSizes,每次调用会统计当前正在处理的列表的FreeID的大小;并把所有FreeID输出到RWFreeIDList中。
当我们找不到ParticleID对应的缓冲区下标时(RWIDToIndexTable),我们认为它是一个FreeID。因此UpdateFreeIDBuffer所做的是收集已有的信息并填充相应的Buffer。
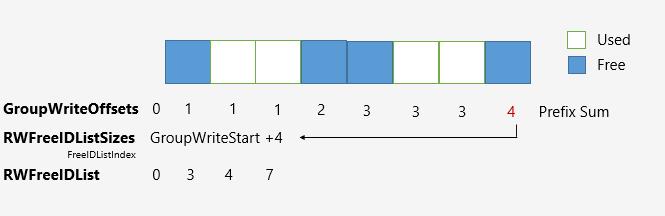
如上图,我们使用前缀和(GroupWritesOffsets)来辅助填充FreeIDList和FreeIDListSizes。
每个TickStage结束后的更新的FreeIDList将用于下一次为粒子分配空闲的ID。
粒子的更新
粒子更新的完整流程包含逻辑线程每帧准备需要更新的数据,以及渲染线程每帧处理数据,并提交到计算着色器进行每帧所需绘制数据的计算的过程。
更新任务收集
每帧需要更新的粒子的所有数据记录在NiagaraGPUSystemTick结构中。它将在游戏线程中创建,并传送到渲染线程。Niagara底层会每帧处理这些Niagara Tick的任务。
Niagara Tick的结构(FNiagaraGPUSystemTick)包含了每个粒子的状态量,缓冲区数据(DIInstanceData)。
所有的Tick任务在Niagara底层存储在Ticks_RT的数组内:
| BuildTickStagePasses | 遍历TickRT并初始化,分发到对应Stage |
| GiveSystemTick_RenderThread | 添加TickRT(逻辑线程发起) |
| InstanceDeallocated_RenderThread | 移除TickRT(逻辑线程发起) |
Niagara Tick的任务由逻辑线程申请和移除。Niagara底层每帧处理队列中的任务,并在每帧执行结束的时候移除所有Tick任务。
BuildTickStagePasses中,ue4遍历所有Tick,构造每个Tick的数据,并将其分发到对应Stage的Tick数组中。
所有Tick任务的处理在收集MeshBatch之前完成。
GPU更新逻辑
Niagara Emitter粒子的计算着色器是Niagara的核心逻辑。它所做的事情主要围绕着粒子数据的处理。这里的粒子数据包括动态数据,如粒子当前的生命、颜色、下标、位置、向量等;以及粒子的静态数据(常量数据),如重力区间、质量区间、大小区间等。
它会填充如下渲染所需的缓冲区:
RWOutputInt
RWOutputFloat
RWOutputHalf
RWInstanceCount
RWIDToIndexTable其中,RWOutputInt、RWOutputFloat、RWOutputHalf按照类型存储了粒子的动态属性数据,InstanceCount存储了每个粒子对应的实例数量,RWIDToIndexTable存储了ParticleId到Instance Buffer的偏移下标的映射关系。
Niagara每个发射器执行的着色器,是以NiagaraEmitterInstanceShader.usf为模板,根据图表内容动态生成的。着色器代码生成逻辑可见NiagaraHlslTranslator.cpp(Translate函数)。其中,NiagaraEmitterInstanceShader.usf主要定义了一些公共的方法,而自动生成的逻辑则主要和每个粒子发射器的私有逻辑相关。
我们dump一份生成的shader代码,可以发现Niagara Emitter CS的模块构成如下:
/*
* CS wrapper for our generated code; calls spawn and update functions on the corresponding instances in the buffer
*/
[numthreads(THREADGROUP_SIZE, 1, 1)]
void SimulateMainComputeCS(
uint3 DispatchThreadId : SV_DispatchThreadID,
uint3 GroupThreadId : SV_GroupThreadID)
GLinearThreadId = DispatchThreadId.x + (DispatchThreadId.y * DispatchThreadIdToLinear);
GDispatchThreadId = DispatchThreadId;
GGroupThreadId = GroupThreadId;
GCurrentPhase = -1;
GEmitterTickCounter = EmitterTickCounter;
GSimStart = SimStart;
GRandomSeedOffset = 0;
// The CPU code will set UpdateStartInstance to 0 and ReadInstanceCountOffset to -1 for stages.
const uint InstanceID = UpdateStartInstance + GLinearThreadId;
if (ReadInstanceCountOffset == 0xFFFFFFFF)
GSpawnStartInstance = 0;
else
GSpawnStartInstance = RWInstanceCounts[ReadInstanceCountOffset]; // needed by ExecIndex()
bool bRunUpdateLogic, bRunSpawnLogic;
#if USE_SIMULATION_STAGES
int IterationInterfaceInstanceCount = SimulationStage_GetInstanceCount();
if (IterationInterfaceInstanceCount > 0)
bRunUpdateLogic = InstanceID < IterationInterfaceInstanceCount && GSimStart != 1;
bRunSpawnLogic = InstanceID < IterationInterfaceInstanceCount && GSimStart == 1;
else
#endif // USE_SIMULATION_STAGES
const int MaxInstances = GSpawnStartInstance + SpawnedInstances;
bRunUpdateLogic = InstanceID < GSpawnStartInstance && InstanceID < UpdateStartInstance + MaxInstances;
bRunSpawnLogic = InstanceID >= GSpawnStartInstance && InstanceID < UpdateStartInstance + MaxInstances;
const float RandomSeedInitialisation = NiagaraInternalNoise(InstanceID * 16384, 0 * 8196,
(bRunUpdateLogic ? 4096 : 0) + EmitterTickCounter); // initialise the random state seed
FSimulationContext Context = (FSimulationContext)0;
BRANCH
if (bRunUpdateLogic)
GCurrentPhase = GUpdatePhase;
SetupExecIndexForGPU();
InitConstants(Context);
LoadUpdateVariables(Context, InstanceID);
ReadDataSets(Context);
else if (bRunSpawnLogic)
GCurrentPhase = GSpawnPhase;
#if USE_SIMULATION_STAGES
// Only process the spawn info for particle-based stages.
// Stages with an iteration interface expect the exec index to simply be the thread index.
if (IterationInterfaceInstanceCount > 0)
SetupExecIndexForGPU();
else
#endif
SetupExecIndexAndSpawnInfoForGPU();
InitConstants(Context);
InitSpawnVariables(Context);
ReadDataSets(Context);
Context.MapSpawn.Particles.UniqueID = Engine_Emitter_TotalSpawnedParticles + ExecIndex();
ConditionalInterpolateParameters(Context);
SimulateMapSpawn(Context);
GCurrentPhase = GUpdatePhase;
TransferAttributes(Context);
if (bRunUpdateLogic || bRunSpawnLogic)
SimulateMapUpdate(Context);
WriteDataSets(Context);
StoreUpdateVariables(Context);
逻辑的入口为SimulateMainComputeCS,它主要包含了粒子的发射或更新的模拟以及最终数据的写入。
每个线程调用对应一个InstanceId,我们可以根据InstanceId与InstanceCount的大小对比来判断这是一个刚出生的粒子或是需要更新的粒子。也就是说,如果InstanceId效于InstanceCount,说明这个粒子已经在之前的阶段生成了。
对于刚出生的粒子,需要从FreeIDList中为粒子分配一个ParticleID。
无论是新生成的粒子,还是需要更新的粒子,一开始都会初始化常量数据和动态数据,区别在于,新生成的粒子的动态数据初始化为0,而需要更新的粒子的动态数据初始化为上一帧的数据。
此外,它们都会更新动态数据,每个数据的更新会调用对应函数,以粒子的生命更新为例,它以上一帧粒子的年龄加上时间间隔,得到当前帧粒子的年龄:
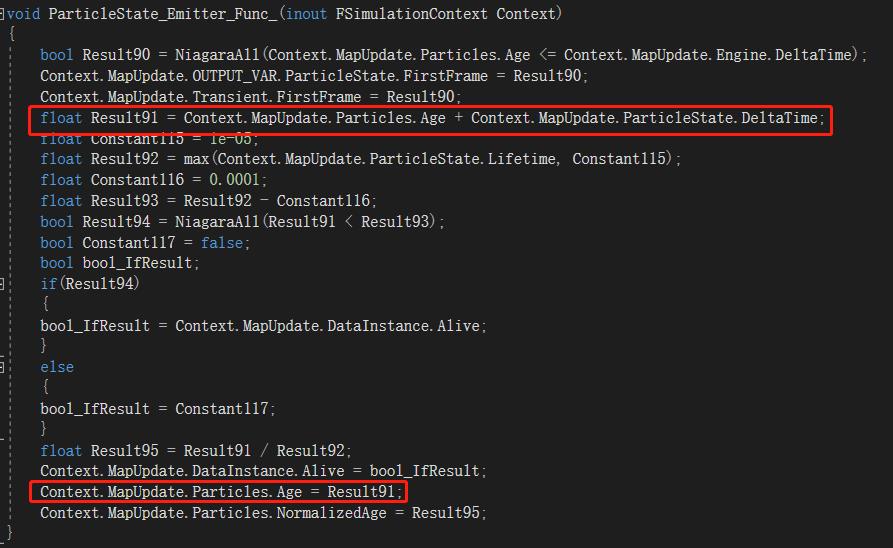
最终,需要将计算得到的数据存储下来。
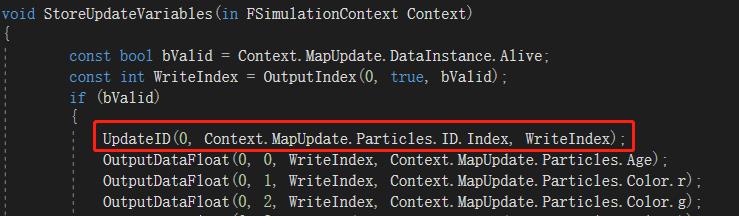
首先需要在Instance Buffer中存储的位置(UpdateID函数),此处如果已经分配了Index(如粒子处于更新阶段),就返回已有的Index,如果是新生成的未分配Index的粒子,则根据InstanceCount,在buffer的末尾分配新的下标。这里计算得到了存储下标后,会同时更新RWIDToIndexTable,把ParticleID映射到计算得到的下标。
根据数据类型,不同的数据写入不同的Buffer(float/int/half)。多个数据根据寄存器下标来按序写入RWOutputInt、RWOutputFloat、RWOutputHalf。
粒子排序和剔除
粒子的排序由FGPUSortManager类管理,其中,ue4默认的Cascade粒子系统和Niagara粒子系统共享了同一个FGPUSortManager实例。
粒子的排序主要是为了保证透明粒子的正确绘制。距离相机越远的粒子应该被优先绘制,因此需要依赖于粒子绘制顺序的计算。
任务添加
排序任务在每个粒子发射器执行AddMeshBatch时,如果需要排序时,加入任务列表。排序依赖的输入包括粒子更新计算得到的DataBuffer,InstanceCount数据以及InstanceCountOffset,CullOffset等。
根据不同的执行标记,排序系统维护了多个SortBatch,每个Batch执行自己内部的排序,并对应一个缓冲区,存储所有需要排序的粒子信息。
计算得到的SortedIndices会作为粒子绘制的输入。
任务执行 - 排序
在渲染之前,InitView结束后,我们执行粒子的排序。
我们会根据SortBatch的优先级依次执行每个批次的排序,包括生成排序的Key和执行排序。相关的逻辑位于NiagaraSortKeyGen.usf。
粒子的排序有多种形式:按照到相机的距离排序,按与相机的夹角排序,按自定义的增序降序。对于前两者而言,依据传入的相机位置和粒子进行计算;而对于后者而言,排序属性直接从粒子的InstanceBuffer中取得。
粒子生成Key的计算着色器会输出两个和排序相关的Buffer,分别是Particle Index Buffer和Key Buffer,分别对应排序的Value和排序的Key。
生成了排序Key后,将执行GPU排序。这里会调用ue4通用的GPU排序接口,输入排序的Key和Value,这需要多次CS计算完成。
任务执行 - GPU剔除
粒子的GPU剔除是可选的。如果开启了GPU剔除,排序和剔除会在同一个计算着色器中完成。
粒子的GPU剔除包含了:
① 视距剔除
② 可见性标记剔除
③ 裁切平面剔除(视锥体)
如果检测到了GPU的剔除,则直接将粒子的SortKey设置为非法的最大值。也就说,粒子的剔除和排序都不涉及到Instance Buffer的重新排列。
由于粒子剔除后,对应的Instance Count会发生变化,因此完成剔除后需要额外填充Culled Particle Count来标记粒子实例数量,用于后续的Indirect Draw。
粒子绘制
粒子的绘制和常规Instance绘制的不同之处在于它是GPU驱动生成的,因此它的顶点缓冲区就不走常规的CPU传入流程,而是由计算着色器计算得到的,直接由GPU生成。
迄今为止,我们已经完成了所有用于绘制的准备数据,包括Instance Buffer, Indirect Args Buffer,SortIndices Buffer等,我们所有的努力都是为了来到这一步。接下来要做的事情就是,利用这些Buffer,决定哪些粒子要绘制,要绘制多少个粒子,以及粒子的位置、大小等。
首先我们在绘制的时候绑定InDirectArgsOffset和IndirectArgsBuffer数据,在绘制的使用走InDirect Draw的图形API接口:
if (IndirectArgsOffsets.IsValidIndex(SectionIndex))
BatchElement.NumPrimitives = 0;
BatchElement.IndirectArgsOffset = IndirectArgsOffsets[SectionIndex];
BatchElement.IndirectArgsBuffer = Batcher->GetGPUInstanceCounterManager().GetDrawIndirectBuffer().Buffer;
接下来所做的事情就是构造Indirect Draw Buffer。
最后,由于顶点缓冲区的是GPU生成的,顶点流和常规流程不一致,我们需要为粒子使用特殊的顶点工厂来控制粒子的绘制逻辑。这对于Indirect Draw的流程而言是必需的。顶点工厂所做的事情就是读取准备好的Instance Buffer等数据,并提供正确的位置、颜色等信息。
整体流程
目前我们已经对整个粒子的更新细节有了一定的了解,接下来我们关注一下Niagara的整体更新流程,以对Niagara的执行逻辑有更全局的认知。
粒子系统在整体的渲染器中的接口是FXSystem,它在渲染器初始化的注册相关的粒子系统。其中,旧的Cascade粒子系统会默认加载到FXSystemSet中,而Niagara粒子系统则是通过开放的回调(Delegate)接口动态注册的。
粒子不同阶段的更新逻辑通过FXSystem转发到Niagara层。
Niagara的更新流程分布在整个渲染流程的各个位置:
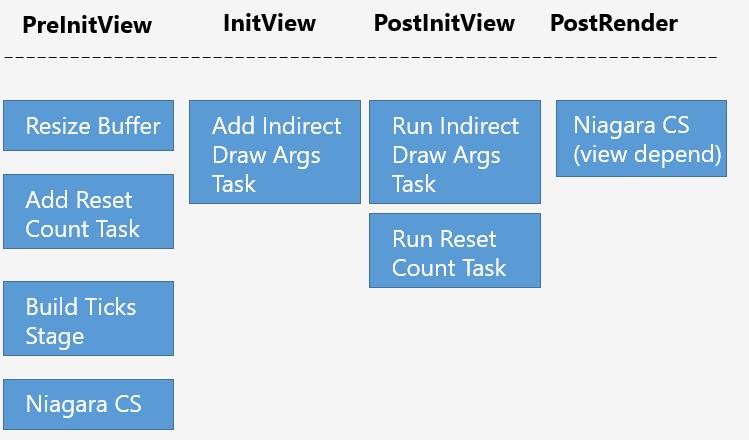
PreInitView阶段
在渲染前收集MeshBatch之前的阶段。
① 对于需要重置的Emitter,添加Instance Count Buffer重置的任务;
② 为Instance Count Buffer和Indirect Draw Args Buffer设置足够的大小;
③ 遍历Tick_RTs并构造,分发到对应的TicksPerStage;
④ 根据TicksPerStage读取PreInitView阶段的任务,并执行每个Emitter的计算着色器,写入Instance Count Buffer;
InitView阶段
收集精灵粒子和模型粒子等MeshBatch的阶段。在收集的时候,会同时执行:
① 添加填充Indirect Draw Args Buffer的任务;
② 绑定每个MeshBatch对应的Indirect Draw Args Buffer(尚未填充);
PostInitView阶段
① 执行粒子的排序;
② 执行生成Indirect Draw Args Buffer的任务;
③ 执行重置Instance Count Buffer的任务,并更新FreeEntry数组;
PostRender阶段
一些需要依赖渲染数据(View相关)的特殊粒子在这里执行,比如深度信息。这部分粒子数据准备完成后将在下一帧执行。
以上是关于Niagara是啥意思的主要内容,如果未能解决你的问题,请参考以下文章