1、掌握time、random库的常用用法。
2、了解collection库,掌握Counter、namedtuple、deque函数的含义和用法。
3、了解itertools库,掌握enumarate、zip、product等函数的含义和用法。
Python自身提供了比较丰富的生态,拿来即用,可极大的提高开发效率。
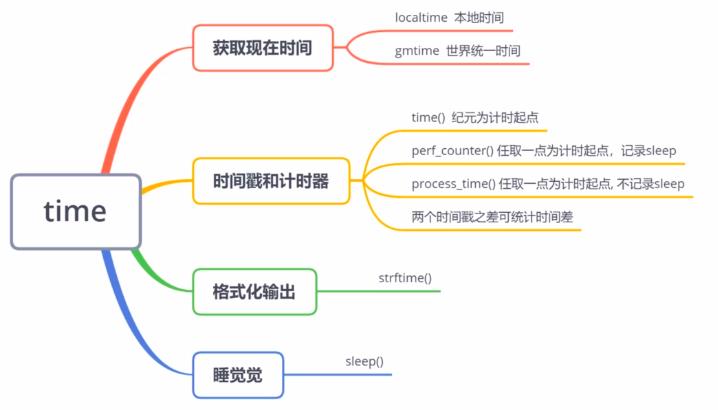
一、time库
Python处理时间的标准库
1、获取现在时间
- time.localtime():本地时间
- time.gmtime():UTC世界统一时间
北京时间比世界统一时间早8个小时
import time
t_local = time.localtime()
t_UTC = time.gmtime()
print("t_local: ", t_local) # 本地时间
print("t_UTC: ", t_UTC) # UTC统一时间
print(time.ctime()) # 返回本地时间的字符串
"""
t_local: time.struct_time(tm_year=2020, tm_mon=2, tm_mday=8, tm_hour=12, tm_min=9, tm_sec=9, tm_wday=5, tm_yday=39, tm_isdst=0)
t_UTC: time.struct_time(tm_year=2020, tm_mon=2, tm_mday=8, tm_hour=4, tm_min=9, tm_sec=9, tm_wday=5, tm_yday=39, tm_isdst=0)
Sat Feb 8 12:09:09 2020
"""
2、时间戳与计时器
- time.time():返回自纪元以来的秒数,记录sleep
- time.perf_counter():随意选取一个时间点,记录现在时间到该时间点的间隔秒数,记录sleep
- time.process_time():随意选取一个时间点,记录现在时间到该时间点的间隔秒数,不记录sleep
3、格式化
time.strftime:自定义格式化输出
import time
t_local = time.localtime()
print(time.strftime("%Y-%m-%d %H:%m:%S", t_local))
"""
2020-02-08 12:16:51
"""
4、休眠
time.sleep(m):休眠m秒
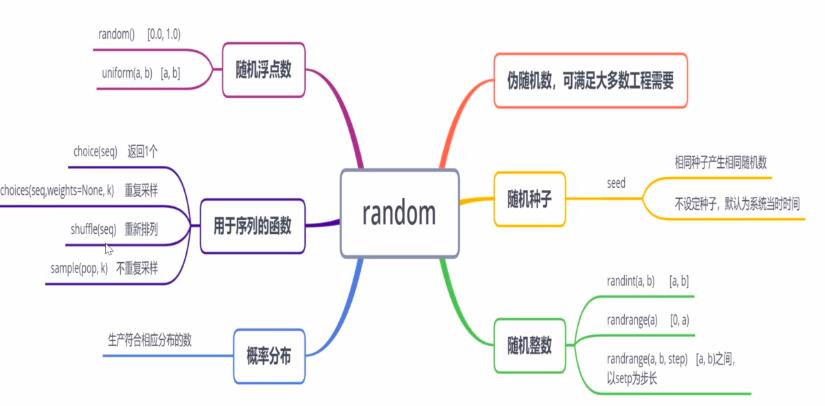
二、random库
随机数在计算机应用中十分常见,Python通过random库提供各种伪随机数,基本可以用于除加密解密算法外的大多数工程应用
1、随机种子——seed(a=None)
- 相同种子会产生相同的随机数
- 如果不设置随机种子,以系统当前时间为默认值
2、产生随机整数
- (1) randlint(a, b):产生[a, b]之间的随机整数
- (2) randrange(a):产生[0, a)之间的随机整数
- (3) randrange(a, b, step):产生[a,b)之间以step为步长的随机整数
3、产生随机浮点数
- (1) random():产生[0.0, 1.0]之间的随机浮点数
- (2) uniform(a, b):产生[a, b]之间的随机浮点数
from random import *
numbers = [uniform(2.1, 3.5) for i in range(10)]
print(numbers)
"""
[2.1929577529017896, 2.1924724048023942, 2.774429454086627,
2.8437011579509877, 2.124246843787783, 3.28800355840583,
2.1034517877154464, 2.1154575533581137, 2.1230887166888635, 3.209706038847072]
"""
4、序列用函数
- choice(seq)——从序列类型中随机返回一个元素
choice([\'win\', \'lose\', \'draw\'])
choice("python")
- choice(seq.weights = None,k)——对序列类型进行k次重复采样,可设置权重
from random import *
print(choices([\'win\', \'lose\', \'draw\'], [4, 4, 2], k=10))
"""
[\'draw\', \'lose\', \'lose\', \'win\', \'draw\',
\'draw\', \'lose\', \'lose\', \'win\', \'win\']
"""
- shuffle(seq)——将序列类型中元素随机排列,返回打乱后的序列
- sample(pop, k)——从pop类型中随机选取k个元素,以列表类型返回
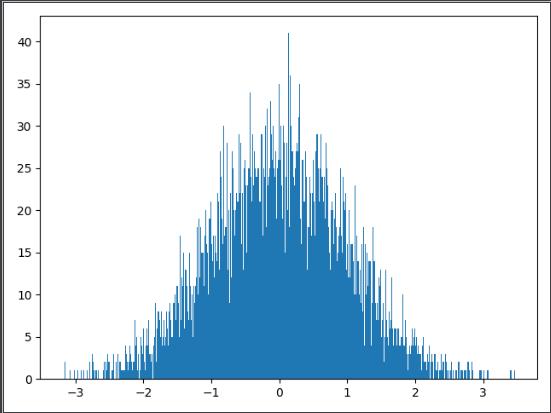
5、概率分布——以高斯分布为例
gauss(mean, std):生产一个符合高斯分布的随机数
import matplotlib.pyplot as plt
from random import *
res = [gauss(0, 1) for i in range(10000)]
plt.hist(res, bins=1000)
plt.show()
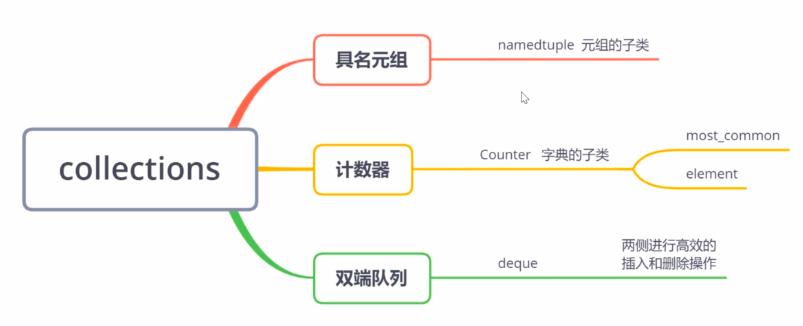
三、collections库——容器数据类型
1、namedtuple——具名元组
collections.namedtuple(typename, filed_name, *, rename=False, defaults=None, module=None)
- typename是元组名字,field_names是域名
import collections
Point = collections.namedtuple("Point", ["x", "y"])
p = Point(1, y=2) # Point(x=1, y=2)
# 可以调用属性
print(p.x)
print(p.y)
# 有元组的属性
print(p[0])
print(p[1])
x, y = p
print(x, y)
# 确实是元组的子类
print(isinstance(p, tuple)) # True
模拟扑克牌
2、Counter——计数器工具
- 是字典的一个子类 # isinstance(Counter(), dict) #True
from collections import Counter
s = "牛奶奶找刘奶奶买牛奶"
colors = [\'red\', \'blue\', \'red\', \'green\', \'blue\', \'blue\']
cat_str = Counter(s)
cat_color = Counter(colors)
print(cat_str)
print(cat_color)
"""
Counter({\'奶\': 5, \'牛\': 2, \'找\': 1, \'刘\': 1, \'买\': 1})
Counter({\'blue\': 3, \'red\': 2, \'green\': 1})
"""
- 最常见的统计——most_common(n):提供n个频率最高的元素和计算
```python
print(cat_color.most_common(2)) # [(\'blue\', 3), (\'red\', 2)]
- 元素展开——elements()
print(list(cat_str.elements()))
# [\'牛\', \'牛\', \'奶\', \'奶\', \'奶\', \'奶\', \'奶\', \'找\', \'刘\', \'买\']
- 其他的一些加减操作
c = Counter(a=3, b=1)
d = Counter(a=1, b=2)
print(c+d)
# Counter({\'a\': 4, \'b\': 3})
3、双向队列——deque
列表访问数据非常快速,插入和删除非常慢——通过移动元素位置来实现,特别是insert(0, v)和pop(0),在列表开始进行的插入和删除操作
双向列表可以方便的在队列两边搞笑、快速的增加和删除元素
from collections import deque
d = deque(\'cde\')
d.append("f") # 在右端添加
d.appendleft("g") # 在左端添加
print(d) # deque([\'g\', \'c\', \'d\', \'e\', \'f\'])
d.pop() # 右端删除
d.popleft() # 左端删除
print(d) # deque([\'c\', \'d\', \'e\'])
"""
Counter({\'奶\': 5, \'牛\': 2, \'找\': 1, \'刘\': 1, \'买\': 1})
Counter({\'blue\': 3, \'red\': 2, \'green\': 1})
"""
其他用法参照官网
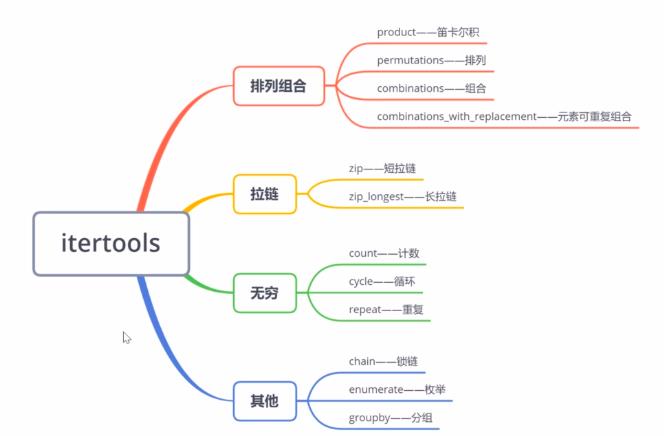
四、Itertools库——迭代器
1、排列组合迭代器
- (1)product——笛卡尔积
import itertools
for i in itertools.product(\'ABC\', \'01\'):
print(i)
for i in itertools.product(\'ABC\', repeat=3):
print(i)
"""
(\'A\', \'0\')
(\'A\', \'1\')
(\'B\', \'0\')
(\'B\', \'1\')
(\'C\', \'0\')
(\'C\', \'1\')
(\'A\', \'A\', \'A\')
(\'A\', \'A\', \'B\')
(\'A\', \'A\', \'C\')
(\'A\', \'B\', \'A\')
(\'A\', \'B\', \'B\')
(\'A\', \'B\', \'C\')
(\'A\', \'C\', \'A\')
(\'A\', \'C\', \'B\')
(\'A\', \'C\', \'C\')
(\'B\', \'A\', \'A\')
(\'B\', \'A\', \'B\')
(\'B\', \'A\', \'C\')
(\'B\', \'B\', \'A\')
(\'B\', \'B\', \'B\')
(\'B\', \'B\', \'C\')
(\'B\', \'C\', \'A\')
(\'B\', \'C\', \'B\')
(\'B\', \'C\', \'C\')
(\'C\', \'A\', \'A\')
(\'C\', \'A\', \'B\')
(\'C\', \'A\', \'C\')
(\'C\', \'B\', \'A\')
(\'C\', \'B\', \'B\')
(\'C\', \'B\', \'C\')
(\'C\', \'C\', \'A\')
(\'C\', \'C\', \'B\')
(\'C\', \'C\', \'C\')
"""
- (3)combinations——组合
- (4) combinations_with_replacement——元素可重复组合
- (2)permutations——排列
2、拉链
- (1)zip——短拉链:相同位置上的元素组合在一起
import itertools
for i in zip("ABC", "012", "xyz"):
print(i)
"""
(\'A\', \'0\', \'x\')
(\'B\', \'1\', \'y\')
(\'C\', \'2\', \'z\')
"""
# 长度不一致是,执行到最短的对象处就停止
for i in zip("ABC", "012345"):
print(i)
"""
(\'A\', \'0\')
(\'B\', \'1\')
(\'C\', \'2\')
"""
- (2) zip_longest——长拉链:长度不一时,执行到最长的对象处,就停止,缺省元素用None或指定字符代替
import itertools
for i in itertools.zip_longest("ABC", "012345"):
print(i)
"""
(\'A\', \'0\')
(\'B\', \'1\')
(\'C\', \'2\')
(None, \'3\')
(None, \'4\')
(None, \'5\')
"""
for i in itertools.zip_longest("ABC", "012345", fillvalue="?"):
print(i)
"""
(\'A\', \'0\')
(\'B\', \'1\')
(\'C\', \'2\')
(\'?\', \'3\')
(\'?\', \'4\')
(\'?\', \'5\')
"""
3、无穷迭代器
- (1) count(start=0, step=1)——计数:创建一个迭代器,从start值开始,返回均匀间隔的值
- (2) cycle(iterable)——循环:创建一个迭代器,返回iterable中所有元素,无限重复
- (3) repeat(object, times)——重复:创建一个迭代器,不断重复object,除非设定参数times,否则将无限重复
4、其他
- (1) chain(iterable)——锁链:把一组迭代对象串联起来,形成一个更大的迭代器
import itertools
for i in itertools.chain("ABC", "012"):
print(i)
"""
A
B
C
0
1
2
"""
- (2) enumerate(iterable, start=0)——枚举(Python内置):产生由两个元素组成的元组,结构是(index, item),其中index从start开始,item从iterable中取
import itertools
for i in enumerate("Python", start=1):
print(i)
"""
(1, \'P\')
(2, \'y\')
(3, \'t\')
(4, \'h\')
(5, \'o\')
(6, \'n\')
"""
- (3)groupby(iterable, key=None)——分组:创建一个迭代器,按照key指定的方式,返回iterable中连续的键和值。一般来说需要预先对数据进行排序,key为None默认把连续重复元素分组
```python
import itertools
animal = [\'duck\', \'eagle\', \'rat\', \'giraffe\', \'bear\', \'bat\', \'dolphin\', \'shark\', \'lion\']
# 按照长度进行排序
animal.sort(key=len)
print(animal)
"""
[\'rat\', \'bat\', \'duck\', \'bear\', \'lion\', \'eagle\', \'shark\', \'giraffe\', \'dolphin\']
"""
for key, group in itertools.groupby(animal, key=len):
print(key, list(group))
"""
3 [\'rat\', \'bat\']
4 [\'duck\', \'bear\', \'lion\']
5 [\'eagle\', \'shark\']
7 [\'giraffe\', \'dolphin\']
"""
# 按照首字母大小排序
animal.sort(key=lambda x: x[0])
print(animal)
"""
[\'bat\', \'bear\', \'duck\', \'dolphin\', \'eagle\', \'giraffe\', \'lion\', \'rat\', \'shark\']
"""
for key, group in itertools.groupby(animal, key=lambda x: x[0]):
print(key, list(group))
"""
b [\'bat\', \'bear\']
d [\'duck\', \'dolphin\']
e [\'eagle\']
g [\'giraffe\']
l [\'lion\']
r [\'rat\']
s [\'shark\']
"""