python数据分析-数据处理
Posted 秋雨秋雨秋雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python数据分析-数据处理相关的知识,希望对你有一定的参考价值。
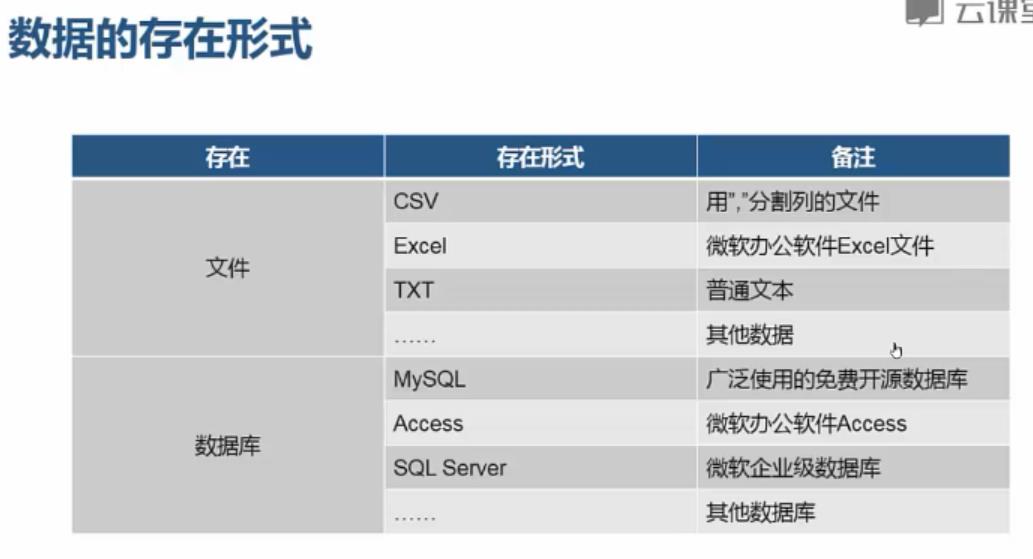
数据导入:
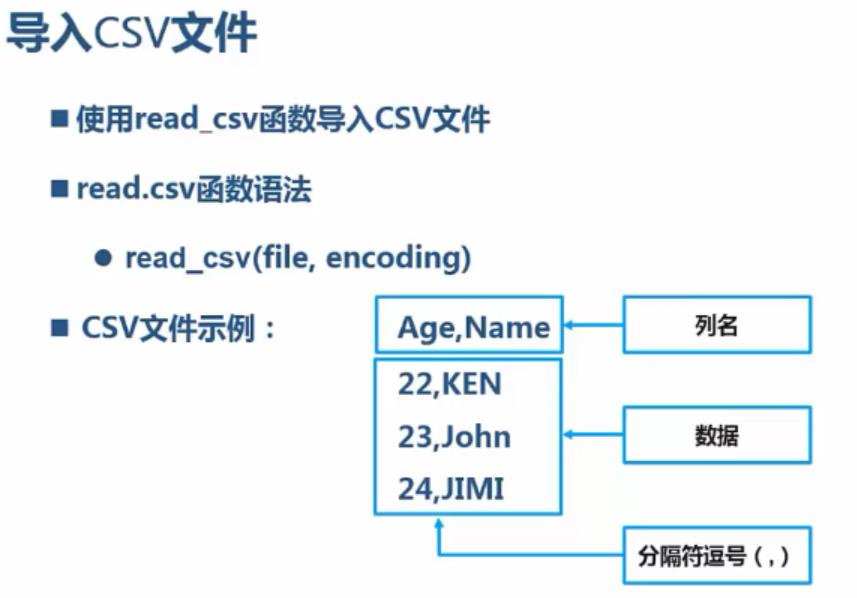

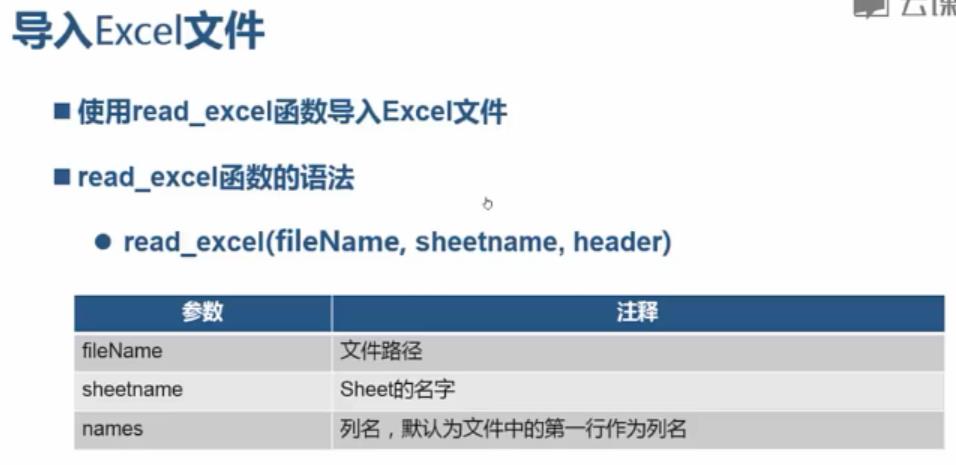


导入csv from pandas import read_csv; df = read_csv(\'D://PA//4.1//1.csv\') 导入文本,要转成UTF-8无BOM格式: from pandas import read_table; df = read_table(\'D://PA//4.1//2.txt\') 导入excle from pandas import read_excel; df = read_excel(\'C:/PA/4.1/3.xlsx\')
数据导出:
数据的导出:

from pandas import DataFrame; df = DataFrame({ \'age\': [21, 22, 23], \'name\': [\'KEN\', \'John\', \'JIMI\'] }); df.to_csv("c:/PA/4.1/df.csv"); #不导入序号 df.to_csv("c:/PA/4.1/df.csv", index=False);
重复值处理:
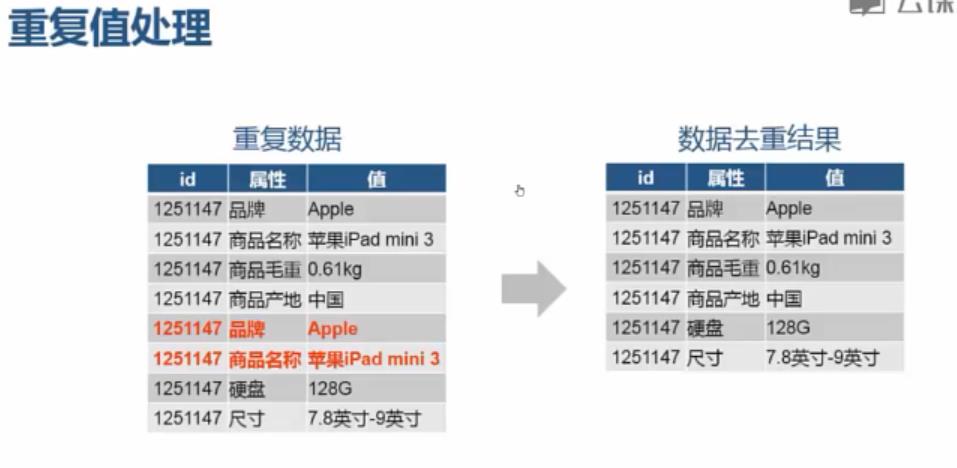

from pandas import read_csv; df = read_csv(\'C:/PA/4.1/data.csv\') newDF = df.drop_duplicates();
缺失值处理:


from pandas import read_csv; df = read_csv(\'C:/PA/4.4/data.csv\') newDF = df.dropna();
空格值处理:

from pandas import read_csv; df = read_csv(\'C:/PA/4.5/data.csv\') newDF = df["name"].str.strip(); df["name"]=newDF;
字段抽取:

astype(str) 转换成字符型数据,以便于处理。
from pandas import read_csv; df = read_csv(\'C:/PA/4.6/data.csv\') df["tel"]=df["tel"].astype(str); bands=df["tel"].str.slice(0,3); areas=df["tel"].str.slice(3,7); numbs=df["tel"].str.slice(7,11);
字段拆分:

from pandas import read_csv; df=read_csv("C:/PA/4.7/data.csv"); newDF=df["name"].str.split(" ",1,True); newDF.columns=["band","name"];
记录抽取:



import pandas; from pandas import read_csv; df=read_csv("C:/PA/4.8/data.csv",sep="|"); df[df.comments>1000]; df[df.comments.between(1000,10000)]; df[pandas.isnull(df.title)]; df[df.title.str.contains("台电",na=False)]; df[(df.comments>=1000)&(df.comments<=10000)]
随机抽样:

import numpy; from pandas import read_csv; df=read_csv("C:/PA/4.9/data.csv"); r=numpy.random.randint(0,10,3); df.loc[r,:];
记录合并 :
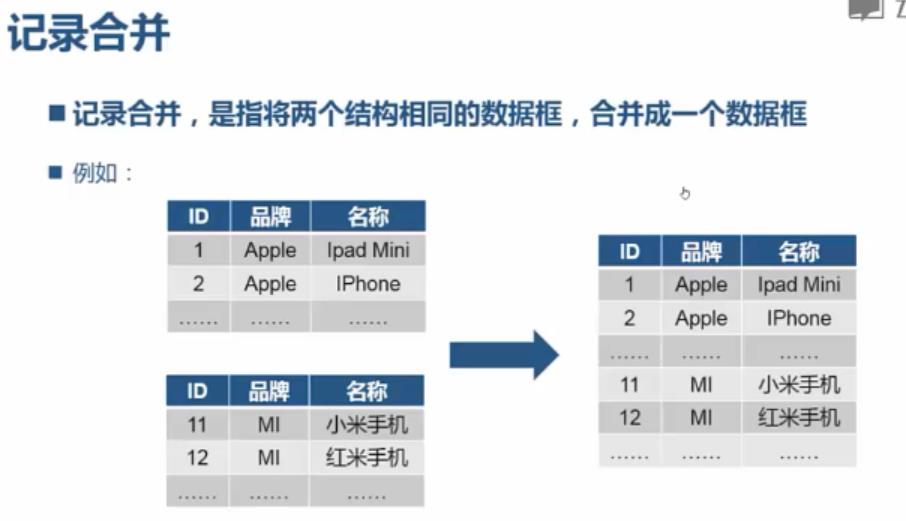

import pandas; from pandas import read_csv; df1=read_csv("C:/PA/4.10/data1.csv",sep="|"); df2=read_csv("C:/PA/4.10/data2.csv",sep="|"); df3=read_csv("C:/PA/4.10/data3.csv",sep="|"); df=pandas.concat([df1,df2,df3])
字段合并:
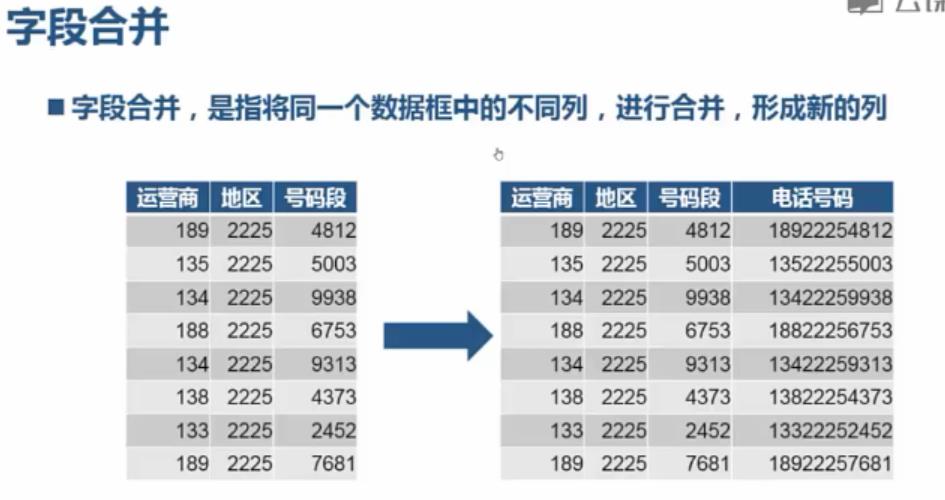

from pandas import read_csv; df = read_csv( "C:/PA/4.11/data.csv", sep=" ", names=[\'band\', \'area\', \'num\'] ); df = df.astype(str); tel = df[\'band\'] + df[\'area\'] + df[\'num\']
字段匹配:
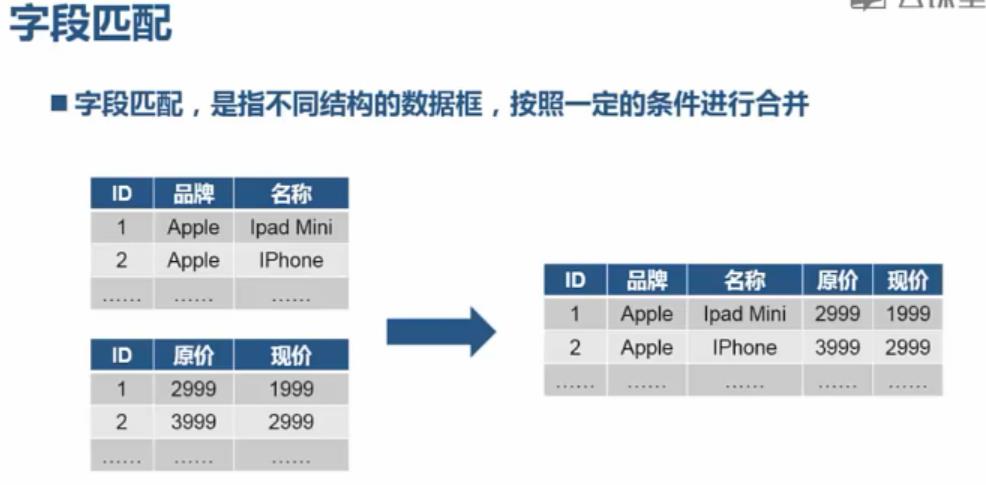

import pandas; from pandas import read_csv; item=read_csv( "C:/PA/4.12/data1.csv", sep="|", names=["id","comments","title"] ); prices=read_csv( "C:/PA/4.12/data1.csv", sep="|", names=["id","oldprice","newprice"] ) itemprices=pandas.merge( item, prices, left_on="id", right_on="id" );
简单计算:
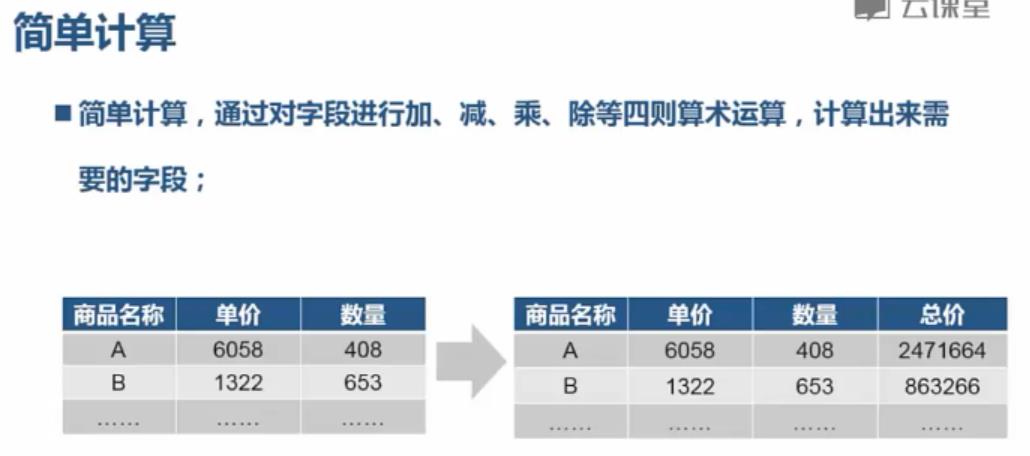
import pandas; from pandas import read_csv; df=read_csv("C:/PA/4.13/data.csv",sep="|"); result=df.price*df.num df["sum"]=result
数据标准化:

import pandas; from pandas import read_csv; df=read_csv("C:/PA/4.14/data.csv"); scale=(df.score-df.score.min())/(df.score.max()-df.score.min())
数据分组:
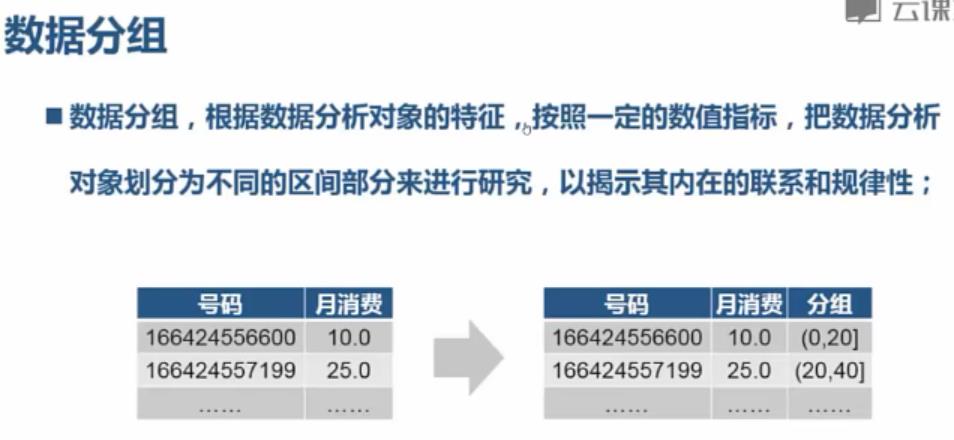

import pandas; from pandas import read_csv; df = read_csv("C:\\\\PA\\\\4.15\\\\data.csv", sep=\'|\'); bins = [min(df.cost)-1, 20, 40, 60, 80, 100, max(df.cost)+1]; labels = [\'20以下\', \'20到40\', \'40到60\', \'60到80\', \'80到100\', \'100以上\']; pandas.cut(df.cost, bins) pandas.cut(df.cost, bins, right=False) pandas.cut(df.cost, bins, right=False, labels=labels)
日期转换:
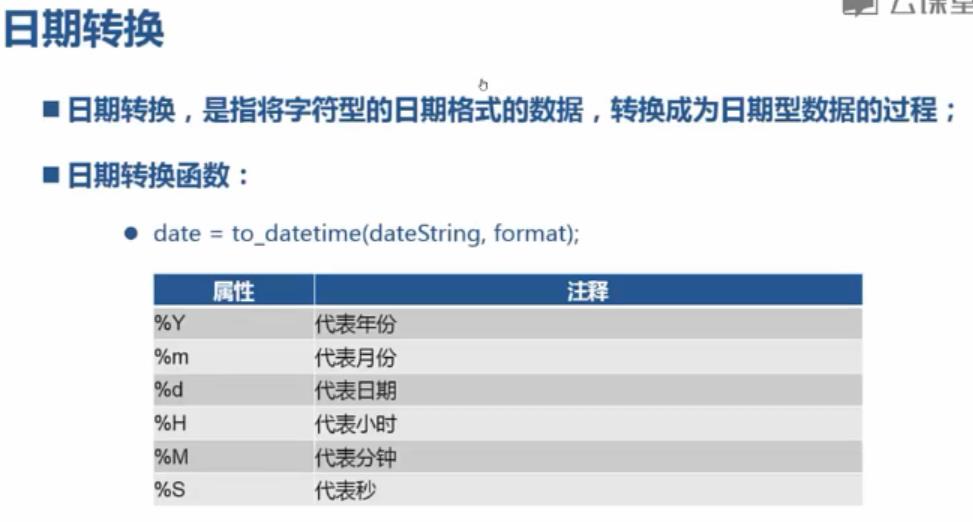
import pandas; from pandas import read_csv; from pandas import to_datetime; df = read_csv("C:\\\\PA\\\\4.16\\\\data.csv",encoding="utf-8"); df_dt=to_datetime(df.注册时间,format="%Y/%m/%d");
日期格式化:
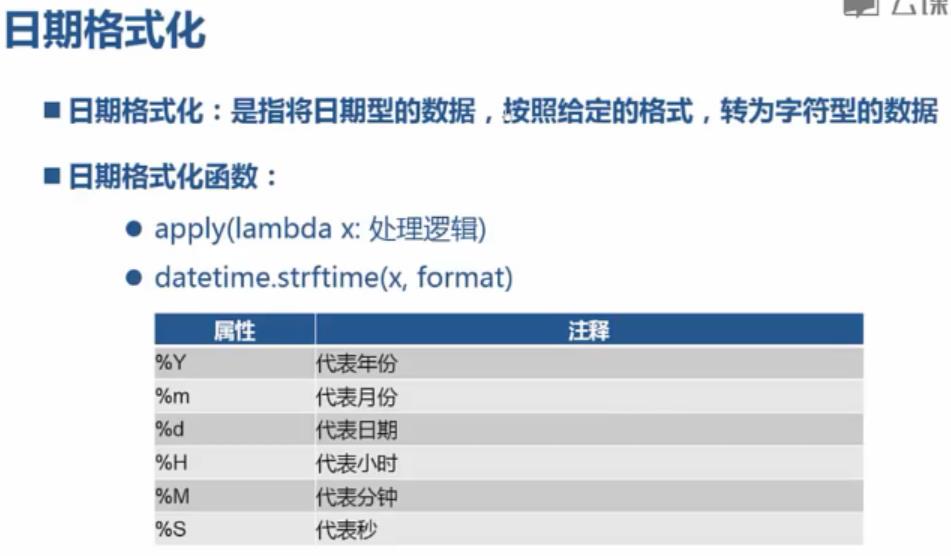
import pandas; from pandas import read_csv; from pandas import to_datetime; df = read_csv("C:\\\\PA\\\\4.16\\\\data.csv",encoding="utf-8"); df_dt=to_datetime(df.注册时间,format="%Y/%m/%d"); df_dt_str=df_dt.apply(lambda x:datatime.strftime(x,"%d-%m-%Y"))
日期抽取:
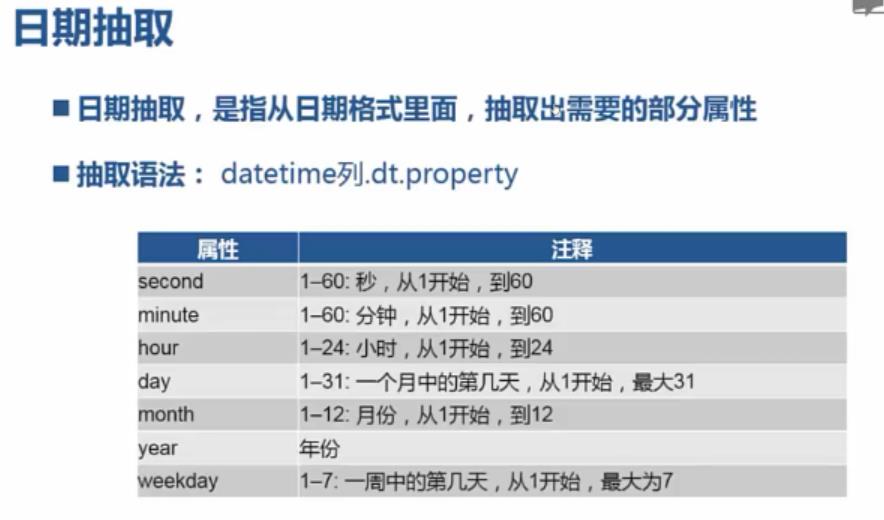
import pandas; from pandas import read_csv; from pandas import to_datetime; df = read_csv("C:\\\\PA\\\\4.18\\\\data.csv",encoding="utf-8"); df_dt=to_datetime(df.注册时间,format="%Y/%m/%d"); df_dt.dt.year; df_dt.dt.second; df_dt.dt.minute; df_dt.dt.hour; df_dt.dt.day; df_dt.dt.month; df_dt.dt.weekday;
以上是关于python数据分析-数据处理的主要内容,如果未能解决你的问题,请参考以下文章
在 Python 多处理进程中运行较慢的 OpenCV 代码片段
你如何在 python 中处理 graphql 查询和片段?
Android 逆向使用 Python 解析 ELF 文件 ( Capstone 反汇编 ELF 文件中的机器码数据 | 创建反汇编解析器实例对象 | 设置汇编解析器显示细节 )(代码片段