python学习day07 高阶函数 装饰器 语法糖
Posted afly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python学习day07 高阶函数 装饰器 语法糖相关的知识,希望对你有一定的参考价值。
#############################高阶函数map########################## # #map()函数接收两个参数,一个是函数,一个是Iterable # #map将传入的函数依次作用到序列的每个元素, # # 并把结果作为新的Iterator返回。 # # 结果r是一个Iterator,Iterator是惰性序列, # # 因此通过list()函数让它把整个序列都计算出来并返回一个list def func(x): return x*x r = map(func,[1,2,3,4,5,6]) li = list(r) print(li,r) #[1, 4, 9, 16, 25, 36] <map object at 0x00000222A4118710> print(list(map(str, [1, 2, "3", "abc", 5, 6, 7, 8, 9]))) #list这里是使map出来的Iterator变成列表并返回一个列表,需要用变量接的,注意不能直接print(list) #[\'1\', \'2\', \'3\', \'abc\', \'5\', \'6\', \'7\', \'8\', \'9\']把列表中的数字转化成字符串
#将两个列表中对应位置的元素相加组成新的列表 l1 = [1,3,5,7,9] l2 = [2,4,6,8,10] ret1 = map(lambda x,y:x+y,l1,l2) print(list(ret1))
##################################高阶函数reduce######################## # reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数, # reduce把结果继续和序列的下一个元素做累积计算,其效果就是 # reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4) from functools import reduce def add(x, y): return x*10 + y ret = reduce(add, [1,3,5,7,9]) print(ret) #13579 变为整数 from functools import reduce DIGITS = {\'0\': 0, \'1\': 1, \'2\': 2, \'3\': 3, \'4\': 4, \'5\': 5, \'6\': 6, \'7\': 7, \'8\': 8, \'9\': 9} #常量使用大写字母 def str2int(s): def fn(x, y): return x * 10 + y def char2num(s): #挺有意思,char to(2) num,字符串转数字 return DIGITS[s] #字典中键对应的值 return reduce(fn, map(char2num, s)) #map把字符串转化成整型的Iterator,fn又把Iterator转化成一个整数 print(str2int("123456")) #123456 # lambda只是一个表达式,函数体比def简单很多。 # lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去 # lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。 # f = lambda x,y,z:x+y+z #冒号前边的是形参,后边的是返回值的表达式 # print(f(1,2,3)) # #6 # #如上面的例子使用lambda写的话 from functools import reduce DIGITS = {\'0\': 0, \'1\': 1, \'2\': 2, \'3\': 3, \'4\': 4, \'5\': 5, \'6\': 6, \'7\': 7, \'8\': 8, \'9\': 9} def char2num(s): return DIGITS[s] def str2int(s): return reduce(lambda x, y: x * 10 + y, map(char2num, s))
#####################filter()函数用于过滤序列################ # 和map()类似,filter()也接收一个函数和一个序列。 # 和map()不同的是,filter()把传入的函数依次作用于每个元素, # 然后根据返回值是True还是False决定保留还是丢弃该元素 def is_odd(n): return n % 2 == 1 print(list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))) #[1, 5, 9, 15]
####计算素数 #先构造一个从3开始的奇数序列 def _odd_iter(): n = 1 while True: n = n + 2 yield n #注意这是一个生成器,并且是一个无限序列。 #然后定义一个筛选函数: def _not_divisible(n): return lambda x: x % n > 0 # 最后,定义一个生成器,不断返回下一个素数: def primes(): yield 2 it = _odd_iter() # 初始序列 it = [3,5,7,9,11,13,15,17,……] while True: n = next(it) # 返回序列的第一个数 此时n=3 yield n it = filter(_not_divisible(n), it) # 构造新序列 _not_divisible(3) it中的每项作为x,筛选出x%3>0,这样就把3的倍数除去了,我在这个参数传递上花了很长时间才弄懂 # 这个生成器先返回第一个素数2,然后,利用filter()不断产生筛选后的新的序列。 # 由于primes()也是一个无限序列,所以调用时需要设置一个退出循环的条件: # 打印1000以内的素数: for n in primes(): if n < 1000: print(n) else: break
#####*******************sorted()排序***************#### #之前我们已经学过在列表中有sort方法 li = [1,5,3,8] li.sort() #[1, 3, 5, 8] 升序排列 li.sort(reverse=True) #[8, 5, 3, 1]降序排列 li.reverse() #[8, 3, 5, 1] 反向排序 ##sorted()函数是python内置的,也是用来排序的 sorted([36,5,-12,9,-21]) #[-21, -12, 5, 9, 36]升序 sorted([36,5,-12,9,-21],key=abs) #sorted()是高阶函数,可以接收一个key函数,这里的key=abs表示的是取绝对值,列表中的元素被abs函数作用后,再把原来的元素做升序排列 #[5, 9, -12, -21, 36] sorted([\'bob\', \'about\', \'Zoo\', \'Credit\'], key=str.lower) #str.lower函数使得列表中的字符串变为小写后(注意lower后面不要加括号),然后以首字母进行升序排列,同sort进行降序排列只要在后面加一个reverse=True就可以了 #[\'about\', \'bob\', \'Credit\', \'Zoo\'] ret = sorted([\'bob\', \'about\', \'Zoo\', \'Credit\'],key=str.lower,reverse=True ) #[\'Zoo\', \'Credit\', \'bob\', \'about\']
dic = {"a":3,"b":2,"c":1}
print(min(dic,key=lambda x:dic[x])) #对字典进行迭代时,迭代的元素是键,而不应当认为是键值对.如 for i in dic 这里的i代表的就是键.同样的字典作为可迭代对象作用于函数中,函数作用的也是字典的键
#c
print(sorted(dic,key=lambda x:dic[x]))
#[\'c\', \'b\', \'a\']
#以列表中元组的最后一个元素进行排序 students = [(\'john\', \'A\', 15), (\'jane\', \'B\', 12), (\'dave\', \'B\', 10)] print(sorted(students,key=lambda x:x[2])) # #[(\'dave\', \'B\', 10), (\'jane\', \'B\', 12), (\'john\', \'A\', 15)] #以列表中字典的值进行排序 students = [{\'john\': 15}, {\'jane\':12,}, {\'dave\':10,}] print(sorted(students,key=lambda x:x.copy().popitem()[1])) #因为字典中只有一个键值对,我们想通过字典而其键不同找到不同的值,可以考虑popitem(),popitem()随机删除字典中的一个键值对,并以元组的形式返回删除的键值对的键和值,因为字典中只有一个键值对所以通过popitem()再结合元组索引就可以找到字典的值,而我们要求字典不能改变所以通过copy()再复制一份 # [{\'dave\': 10}, {\'jane\': 12}, {\'john\': 15}]
students = [{\'john\': 15}, {\'jane\':12,}, {\'dave\':10,}]
print(sorted(students,key=lambda x:list(students[students.index[x]].values())[0])) #使用values也可以
#[{\'john\': 15}, {\'jane\': 12}, {\'dave\': 10}]
###*******************偏函数******************* import functools int2 = functools.partial(int,base=2) print(int2("101111")) # ==>int("101111",base=2),把字符串"101111"当做2进制,转化成10进制 #47 #创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数 int2 = functools.partial(int, base=2) ==> kw = { \'base\': 2 } # ==> int(\'10010\', **kw) max2 = functools.partial(max, 10) #10作为*args的一部分自动加到左边,也就是 max2(5, 6, 7) ==> args = (10, 5, 6, 7) # ==> max(*args)
语法糖对于计算机的运行并没有任何的好处,但是对于程序员的好处是很大的,方便我们写代码,所以称为糖
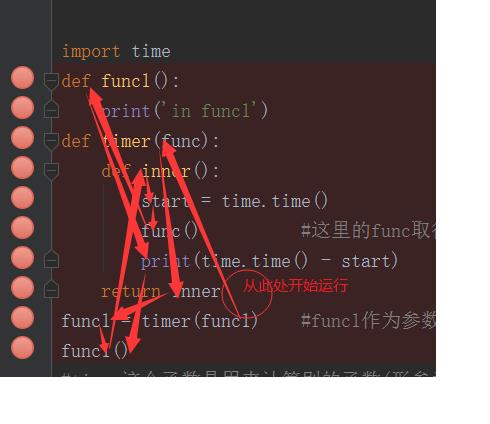
#******************************装饰器************************* # 装饰器本质上就是一个python函数,他可以让其他函数在不需要做任何代码变动的前提下,增加额外的功能,装饰器的返回值也是一个函数对象。 # 装饰器的应用场景:比如插入日志,性能测试,事务处理,缓存等等场景 import time def func1(): print(\'in func1\') def timer(func): def inner(): start = time.time() func() #这里的func取得是形参,形参给的是func1,所以这里执行的是func1() print(time.time() - start) return inner func1 = timer(func1) #func1作为参数传递到timer函数中,timer函数返回一个inner的返回值赋值给func1,func1()也即inner() func1() #timer这个函数是用来计算别的函数(形参为函数名)的运行时间
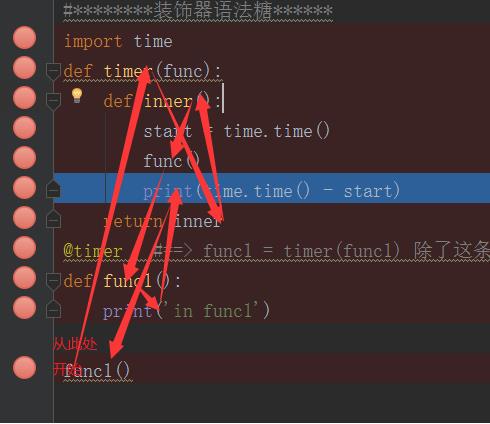
#********装饰器语法糖****** import time def timer(func): def inner(): start = time.time() func() print(time.time() - start) return inner @timer #==> func1 = timer(func1) 除了这条语句,其他的语句都一样,而@timer 就相当于 timer(func1)语句, #这个@timer语句相当于把timer函数和与它相邻的下一个函数以func1 = timer(func1)这样的形式关联起来 def func1(): print(\'in func1\') time.sleep(1) #延时1s def func2(): print(\'in func2\') time.sleep(2) #延时2s func1() func2() # in func1 # 1.0009326934814453 输出结果是1s多,很明显func1函数扩展了计时功能 # in func2
import time def timer(func): def inner(): start = time.time() func() print(time.time() - start) return inner @timer #==> func1 = timer(func1) 除了这条语句,其他的语句都一样,而@timer 就相当于 timer(func1)语句, #这个@timer语句相当于把timer函数和与它相邻的下一个函数以func1 = timer(func1)这样的形式关联起来 def func2(): print(\'in func2\') time.sleep(2) #延时2s def func1(): print(\'in func1\') time.sleep(1) #延时1s func1() func2() # in func1 # in func2 # 2.0009799003601074 #这次因为func2和timer相邻,所以fun2扩展了计时功能
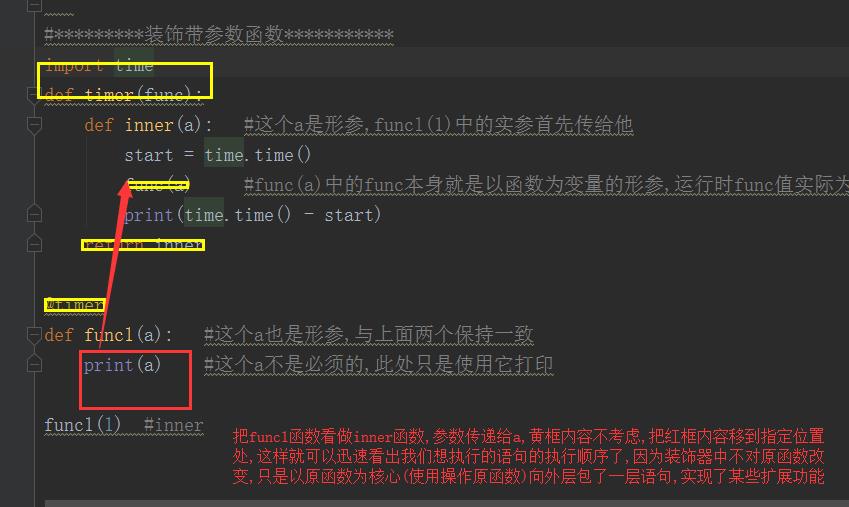
#*********装饰带参数函数*********** import time def timer(func): def inner(a): #这个a是形参,funcl(1)中的实参首先传给他 start = time.time() func(a) #func(a)中的func本身就是以函数为变量的形参,运行时func值实际为funcl,而a作为形参同时作为变量a的值与上面一致是1 print(time.time() - start) return inner @timer def func1(a): #这个a也是形参,与上面两个保持一致 print(a) #这个a不是必须的,此处只是使用它打印 func1(1) #inner
from functools import wraps def deco(func): @wraps(func) #加在最内层函数正上方,这个是必要的,不然会出错 def wrapper(*args,**kwargs): return func(*args,**kwargs) return wrapper @deco def index(): \'\'\'哈哈哈哈\'\'\' print(\'from index\') print(index.__doc__) #查看函数注释的方法 print(index.__name__) #查看函数名的方法
import time def func1(): \'\'\'注释1\'\'\' print(\'in func1\') def timer(func): def inner(): \'\'\'注释2\'\'\' start = time.time() func() print(time.time() - start) return inner func1 = timer(func1) print(func1.__name__) print(func1.__doc__) # in func1 # 0.0 # inner 不使用@wraps(func)这个东西时,会认为func1的名字的注释是inner的名字和注释 # 注释2
#******************装饰器的固定格式************ def timer(func): def inner(*args,**kwargs): \'\'\'执行函数之前要做的\'\'\' re = func(*args,**kwargs) \'\'\'执行函数之后要做的\'\'\' return re return inner from functools import wraps def deco(func): @wraps(func) #加在最内层函数正上方 def wrapper(*args,**kwargs): return func(*args,**kwargs) return wrapper *****************带参数的装饰器,带上标志可以灵活的决定是否使用装饰器************** def outer(flag): def timer(func): def inner(*args,**kwargs): if flag: print(\'\'\'执行函数之前要做的\'\'\') re = func(*args,**kwargs) if flag: print(\'\'\'执行函数之后要做的\'\'\') return re return inner return timer @outer(False) def func(): print(111) func() #******************多个装饰器装饰一个函数*************** def wrapper1(func): def inner(): print(\'wrapper1 ,before func\') func() print(\'wrapper1 ,after func\') return inner def wrapper2(func): def inner(): print(\'wrapper2 ,before func\') func() print(\'wrapper2 ,after func\') return inner @wrapper2 @wrapper1 def f(): print(\'in f\') f()
##多个装饰器装饰一个函数详解
def wrapper1(fn): def inner(*args,**kwargs): print("我是wrapper1前面的") ret = fn(*args,**kwargs) print("我是wrapper1后面的") return ret return inner def wrapper2(fn): def inner(*args,**kwargs): print("我是wrapper2前面的") ret = fn(*args,**kwargs) print("我是wrapper2后面的") return ret return inner @wrapper1 # @wrapper1 可以看做是 wrapper2 = wrapper1(wrapper2) @wrapper2 # @wrapper2 可以看做是 func = wrapper2(func) 但却不能直接用这两个语句替换,应该使用func = wrapper1(wrapper2(func)) def func(): print("我是func") func() \'\'\' 我是wrapper1前面的 我是wrapper2前面的 我是func 我是wrapper2后面的 我是wrapper1后面的 \'\'\' def wrapper1(fn): def inner(*args,**kwargs): print("我是wrapper1前面的") ret = fn(*args,**kwargs) print("我是wrapper1后面的") return ret return inner def wrapper2(fn): def inner(*args,**kwargs): print("我是wrapper2前面的") ret = fn(*args,**kwargs) print("我是wrapper2后面的") return ret return inner def func(): print("我是func") func = wrapper1(wrapper2(func)) #即多个装饰器的实际语句是 func = wrapper1(wrapper2(wrapper3(...(wrapper100(func))))) func() \'\'\' 我是wrapper1前面的 我是wrapper2前面的 我是func 我是wrapper2后面的 我是wrapper1后面的 \'\'\'
#*****最全的固定格式 from functools import wraps def wrapper_out(flag): def wrapper(fn): @wraps(fn) def inner(*args,**kwargs): if flag: #flag为真执行装饰器 \'\'\'函数执行前语句\'\'\' ret = fn(*args,**kwargs) \'\'\'函数执行后语句\'\'\' return ret else: #flag为假不执行装饰器 ret = fn(*args, **kwargs) return ret return inner return wrapper @wrapper_out(True) def func(*args,**kwargs): print("我是func")
func()
print(func.__name__,func.__doc__)
# 我是func
# func None
以上是关于python学习day07 高阶函数 装饰器 语法糖的主要内容,如果未能解决你的问题,请参考以下文章