python面向对象编程设计与开发
Posted 寻寻觅觅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python面向对象编程设计与开发相关的知识,希望对你有一定的参考价值。
一、什么是面向对象的程序设计
1、何为数据结构?
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合,如列表、字典。
2、何为编程?
编程是指程序员用特定的语法+数据结构+算法,组成的代码,告诉计算机如何执行任务的过程。
3、何为编程范式?
实现一个任务的方式有很多种,对这些不同的编程方式的特点进行归纳总结得出的编程方式类别即为编程范式。
大多数语言只支持一种编程方式,也有些支持多种的。
两种最重要的编程范式:面向过程编程和面向对象编程。
4、面向过程编程(Procedural programming)
面向过程编程的核心是“过程”,过程即指解决问题的步骤。
优点:将复杂的问题流程化,简单化。
缺点:可扩展性差,后期如果要更改某一程序功能是,可能存在“牵一发而动全身”,软件的维护难度会越来越高。
应用场景:适用于那些功能一旦实现就不会轻易更改的情况,如Linux内核,git,Apache HTTP Server等。
5、面向对象编程(Object Oriented Programming)
面向对象,核心就是“对象”二字,对象就是“特征”与“技能”的结合体。
优点:可扩展性强,易更改,易维护。
缺点:编程复杂度高
应用场景:应用于用户需求经常变化的场景,如互联网应用、企业内部应用、游戏等。
面向对象编程:就是利用“类”和“对象”来创建各种模型来实现对真实世界的描述,主要用于解决软件开发中可扩展性的问题。
6、面向对象三大特性:继承、多态、封装
二、类与对象
1、python中一切皆对象。
2、对象:指特征与技能的结合体。
3、类:指一系列对象相似的特征与技能的结合体,类就相当于一个模型。
4、站在不同的角度,得到的分类是不一样的。
5、类与对象的产生
在现实世界中:先有对象,后有类
在程序中:先定义类,后调用类来产生对象
与函数的使用是类似的:先定义函数,后调用函数,类也是一样的:在程序中需要先定义类,后调用类。不一样的是:调用函数会执行函数体代码,返回的是函数体执行的结果,而调用类会产生对象,返回的是对象。
6、如何定义类
在程序中,用class关键字定义一个类,类的特征用变量标识,即数据属性,类的技能用函数标识,即函数属性。
类在定义阶段就会被执行,会产生新的名称空间,用来存放类的变量名和函数名,可以通过“类名.__dict__”查看类的名称空间,返回的是一个字典。对于经典类来说,我们可以通过该字典操作类名称空间的名字,但新式类有限制。
7、如何使用类


class Person(object): """人类""" def __init__(self, name, age): self.name = name self.age = age def talk(self): print("hello, my name is %s, I\'m %s years old" % (p.name, p.age)) p = Person("jack", 22) print(p.name, p.age) # 查看对象属性 p.talk() # 注意这里调用并未传递参数 # 新增类属性 Person.country = "China" # 给类新增一个属性 # Person.__dict__[\'country\'] = "China" # 不支持这样新增 # 查看类属性 print(Person.__dict__["country"]) # 查看属性 print(Person.__dict__) # 查看所有属性 # 删除类属性 del Person.country # 删除属性 # Person.__dict__.pop("country") # 不支持这样删除 print(Person.__dict__) # 查看属性,发现country属性已不存在 """ 输出: jack 22 hello, my name is jack, I\'m 22 years old China {\'__module__\': \'__main__\', \'__doc__\': \'人类\', \'__init__\': <function Person.__init__ at 0x0000000001E48950>, \'talk\': <function Person.talk at 0x0000000001E489D8>, \'__dict__\': <attribute \'__dict__\' of \'Person\' objects>, \'__weakref__\': <attribute \'__weakref__\' of \'Person\' objects>, \'country\': \'China\'} {\'__module__\': \'__main__\', \'__doc__\': \'人类\', \'__init__\': <function Person.__init__ at 0x0000000001E48950>, \'talk\': <function Person.talk at 0x0000000001E489D8>, \'__dict__\': <attribute \'__dict__\' of \'Person\' objects>, \'__weakref__\': <attribute \'__weakref__\' of \'Person\' objects>}
类的两大用途:对属性的操作、实例化对象。
8、使用__init__方法定制对象独有的特征
__init__方法被称为构造方法或初始化方法。在对象实例化的时候就会自动调用该方法,实现对象的初始化操作,在__init__方法中不能有return返回值。
class LuffyStudent: school = "luffycity" def __init__(self, name, sex, age): # 使用构造方法初始化对象 self.name = name self.sex = sex self.age = age def learning(self, x): print("%s is learning %s" % (self.name, x)) stu1 = LuffyStudent("alex", "男", 22) stu2 = LuffyStudent("rain", "男", 23) stu3 = LuffyStudent("laura", "女", 22) print(LuffyStudent.__dict__)
9、对象属性的操作
class LuffyStudent: school = "luffycity" def __init__(self, name, sex, age): # 使用构造方法初始化对象 self.name = name self.sex = sex self.age = age def learning(self, x): print("%s is learning %s" % (self.name, x)) stu1 = LuffyStudent("alex", "男", 22) stu2 = LuffyStudent("rain", "男", 23) stu3 = LuffyStudent("laura", "女", 22) # print(LuffyStudent.__dict__) # 修改 stu1.name = "Alex" # 等同于:stu1.__dict__["name"] = "Alex" print(stu1.__dict__) # 删除 del stu1.age # 等同于:stu1.__dict__.pop("age") print(stu1.__dict__) # 新增 stu1.course = "python" # 等同于:stu1.__dict__["course"] = "python" print(stu1.__dict__) 输出: {\'name\': \'Alex\', \'sex\': \'男\', \'age\': 22} {\'name\': \'Alex\', \'sex\': \'男\'} {\'name\': \'Alex\', \'sex\': \'男\', \'course\': \'python\'}
10、类的属性查找与绑定方法
类有两种属性:数据属性和函数属性。
1、类的数据属性是所有对象共享的
2、类的函数属性在没有被任何装饰器修饰的情况下是绑定给对象用的,称为绑定到对象的方法,绑定到不同的对象就是不同的绑定方法,对象绑定方法时,会把对象本身当作第一个参数传入,即self==对象名。绑定到对象的方法的这种自动传值的特征,决定了在类中定义的函数都要默认写一个参数self,self可以是任意名字,但是约定俗成的写为self。
三、继承
继承指类与类之间的一种什么“是”什么的关系。用于解决代码重用的问题。继承是一种新建类的方式,新建的类可以继承一个或多个父类,父类可以称为基类或超类,新建的类称为子类或派生类。
1、python中类的继承分为:单继承和多继承
class ParentClass1: #定义父类 pass class ParentClass2: #定义父类 pass class SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass pass class SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass
2、查看继承:
>>> SubClass1.__bases__ #__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类 (<class \'__main__.ParentClass1\'>,) >>> SubClass2.__bases__ (<class \'__main__.ParentClass1\'>, <class \'__main__.ParentClass2\'>)
3、继承中的属性查找:
# 属性查找 class Foo: def f1(self): print("from Foo.f1") def f2(self): print("from Foo.f2") self.f1() # 相当于b.fi() class Bar(Foo): def f1(self): print("form Bar.f1") b = Bar() print(b.__dict__) b.f2() 输出: {} from Foo.f2 form Bar.f1
调用f2方法,发现对象b中没有该方法,再去b的类Bar中找,也没有,接着去Bar类的父类Foo中找,找到了,就打印“from Foo.f2”,在Foo中还有语句“self.f1()”,这时,程序会又在对象b中找名为f1的方法,发现没有,再去b的类Bar中找,找到了,就打印“form Bar.f1”
4、python中经典类与新式类
在python3中如果不指定继承哪个类,默认就会继承Object类,而继承了Object类的类就叫做新式类。
python2中如果不指定继承哪个类也不会默认去继承Object类,而没有继承Object类的类就叫做经典类。而显示的指定继承Object类的类才是新式类。
经典类和新式类的不同就在于属性查找的顺序不同,经典类是深度优先(先一条路走到底),即先找自己类内,如果没有就找右边第一个父类,没找到继续从这个父类的父类中找依次类推直到找到最上一级的父类也没找到再找右边第二个父类,然后再重复之前的过程,直到所有父类找一遍没找到就报错;而新式类是广度优先,先按父类顺序逐个查找,如果没找到,最后才会去找object类,如果没有找到指定属性就报错。可以通过“类名.mro()”或“类名.__mro__”查看新式类继承中的属性查找顺序。
# python2中分有新式类和经典类,py3中只有新式类 #py2中,经典类:没有继承object的类以及它的子类 class Foo: pass class Bar(Foo): pass
# 在py2中,新式类:继承object的类,以及它的子类都称之为新式类 class Foo(object): pass class Bar(Foo): pass
# 在py3中,新式类:默认都继承object class Foo: # 等同于class Foo(object): pass class Bar(Foo): pass
下面是我在别处找到的比较经典的能够很好的展现深度优先和广度优先查找的图:
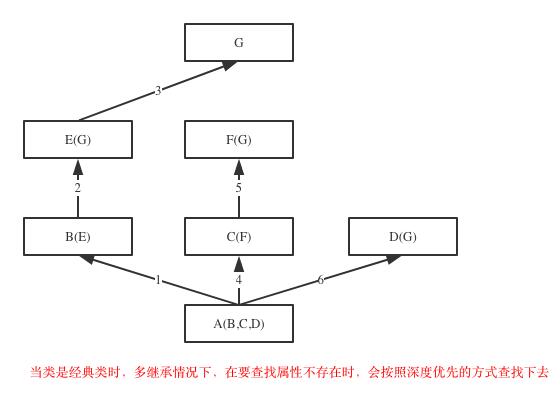
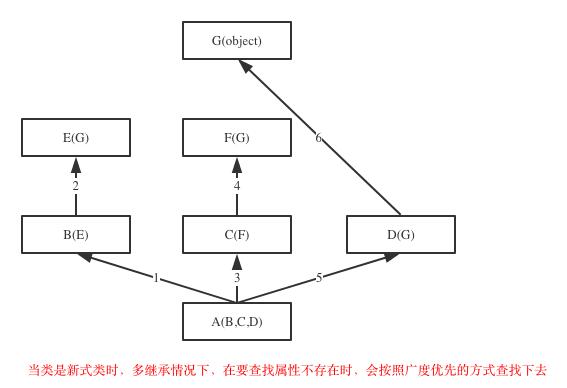
class A(object): def test(self): print(\'from A\') class B(A): def test(self): print(\'from B\') class C(A): def test(self): print(\'from C\') class D(B): def test(self): print(\'from D\') class E(C): def test(self): print(\'from E\') class F(D,E): # def test(self): # print(\'from F\') pass f1=F() f1.test() print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性 #新式类继承顺序:F->D->B->E->C->A #经典类继承顺序:F->D->B->A->E->C
5、在自类中调用父类的方法
1)指名道姓,即父类名.父类方法(),这种方式不依赖于继承
2)使用super(),这种方式依赖于继承的,并且即使没有直接继承关系,super仍然会按照mro继续往后查找
class A: def f1(self): # 根据C.mro()列表,首先在A中找到f1 print("from A") super().f1() # 当程序运行到这一步时,super会沿着C.mro()列表往下找f1 class B: def f1(self): # 然后在B中找到f1 print("from B") class C(A,B): pass print(C.mro()) c = C() c.f1() # 运行程序,发现打印了A,也打印了B,因为这是基于C类引发的寻找,super只会根据C.mro()中的列表顺序一个接一个往下找 输出: [<class \'__main__.C\'>, <class \'__main__.A\'>, <class \'__main__.B\'>, <class \'object\'>] from A from B
6、派生
子类可以给自己添加新的属性,或在自己这里重新定义父类的属性,而不会影响父类,一旦重新定义了自己的属性且与父类同名,那么调用该属性时,就会以自己重新定义的为准。
四、组合
软件重用的重要方式除了继承之外还有另外一种方式,即:组合
组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合
组合是一种什么“有”什么的关系,如教师有课程,学生有课程。
class People: """人类""" school = "luffy" def __init__(self, name, age, sex): self.name = name self.age = age self.sex = sex class Teacher(People): """教师类""" def __init__(self, name, age, sex, level, salary): super(Teacher, self).__init__(name, age, sex) self.level = level self.salary = salary def teach(self): print("%s is teaching" % self.name) class Student(People): """学生类""" def __init__(self, name, age, sex, class_time): super().__init__(name, age, sex) self.class_time = class_time def learn(self): print("%s is learning" % self.name) class Course: """课程类""" def __init__(self, course_name, course_price, course_period): self.course_name = course_name self.course_price = course_price self.course_period = course_period def course_info(self): print("课程名:%s 价格:%s 课时:%s" % (self.course_name, self.course_price, self.course_period)) python = Course("python", 10000, "3month") linux = Course("linux", 8000, "2month") teach1 = Teacher("alex", 38, "male", 10, 3000) teach2 = Teacher("egon", 28, "male", 20, 4000) teach1.course = python # 给老师添加课程属性 teach2.course = python print(teach1.__dict__) print(teach2.__dict__) print(teach1.course.course_name) # 查看老师所教的课程名 teach2.course.course_info() # 查看课程信息 stu1 = Student("rain", 14, "male", "8:30") stu1.course1 = python stu1.course2 = linux stu1.course1.course_info() # 查看课程信息 stu1.course2.course_info() stu1.courses = [] stu1.courses.append(python) stu1.courses.append(linux) print(stu1.__dict__) 输出: {\'name\': \'alex\', \'age\': 38, \'sex\': \'male\', \'level\': 10, \'salary\': 3000, \'course\': <__main__.Course object at 0x000000000251B518>} {\'name\': \'egon\', \'age\': 28, \'sex\': \'male\', \'level\': 20, \'salary\': 4000, \'course\': <__main__.Course object at 0x000000000251B518>} python 课程名:python 价格:10000 课时:3month 课程名:python 价格:10000 课时:3month 课程名:linux 价格:8000 课时:2month {\'name\': \'rain\', \'age\': 14, \'sex\': \'male\', \'class_time\': \'8:30\', \'course1\': <__main__.Course object at 0x000000000251B518>, \'course2\': <__main__.Course object at 0x000000000251B550>, \'courses\': [<__main__.Course object at 0x000000000251B518>, <__main__.Course object at 0x000000000251B550>]}
五、接口类与抽象类
接口类是用于规范子类的方法名定义用的,接口提取了一群类共同的函数,可以把接口当做一个函数的集合。继承接口类的子类可以不存在任何逻辑上的关系但是都需要实现某些共同的方法,为了让这些子类的方法名能够统一以便之后调用这些方法时不需要关注具体的对象就用接口类规范了这些方法的名字,子类一旦继承了接口类就必须实现接口类中定义的方法,否则在子类实例化的时候就会报错,而接口类本身则不需要实现去实现这些方法。
# 定义接口Interface类来模仿接口的概念 class Animal: # 接口类 all_type = "animal" # 接口名 def run(self): # 接口名,但不去实现它 pass def eat(self): # 接口名 pass class People(Animal): # 子类继承接口 def run(self): # 调用接口 print("people is walking") # 实现接口的功能 def eat(self): print("people is eating") class Pig(Animal): def run(self): print("pig is walking") def eat(self): print("pig is eating") class Dog(Animal): def run(self): print("dog is walking") def eat(self): print("dog is eating") poe1 = People() pig1 = Pig() dog1 = Dog() poe1.run() dog1.run() print(poe1.all_type)
上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,比如:在People类中,完全可以把run改为walk等方法名,也就是说,此时的父类对子类的调用方式,不具有约束力,
这就用到了抽象类:
# 如下代码,实现接口约束 import abc # 导入模块 class Animal(metaclass=abc.ABCMeta): # 这个Animal类只能被继承,不能被实例化 all_type = "animal" # 数据属性 @abc.abstractmethod # 装饰器 def run(self): # 定义抽象方法,无需实现功能 (函数属性) pass @abc.abstractmethod def eat(self): # 定义抽象方法,无需实现功能 pass class People(Animal): # 此时若在子类里面没有定义父类的run和eat方法,程序就会报错,父类相当于起到一个规范的作用 def run(self): # 子类必须定义run方法 pass # print("people is walking") def eat(self): # 子类必须定义eat方法 print("people is eating") class Pig(Animal): def run(self): print("pig is walking") def eat(self): print("pig is eating") class Dog(Animal): def run(self): print("dog is walking") def eat(self): print("dog is eating") poe1 = People() pig1 = Pig() dog1 = Dog() poe1.run() dog1.run() print(poe1.all_type) # 这样大家都是被归一化了,也就是一切皆文件的思想
抽象类的作用和接口类一样,只是继承它的子类一般存在一些逻辑上的关系。
抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化,
如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
抽象类与普通类的区别:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。
接口类与抽象类的区别:接口只强调函数属性的相似性。抽象类既包括函数属性又包括数据属性。
所以说,抽象类同时具备普通类和接口类的部分特性。
六、多态
1、多态指一类事物的多种形态,如动物类有:人、猫、狗。
2、多态性指在不考虑对象类型的情况下去使用对象,不同的对象可以调用相同的方法得到不同的结果。有点类似接口类的感觉。
3、多态性的好处:
1)增加程序灵活性
2)增加程序可扩展性
4、静态多态性:比如不管你是列表还是字符串还是数字都可以使用+和*。
5、动态多态性:调用方法
import abc # 导入模块 class Animal(metaclass=abc.ABCMeta): all_type = "animal" @abc.abstractmethod def run(self): pass @abc.abstractmethod def eat(self): pass class People(Animal): def run(self): print("people is walking