python常用模块
Posted not_enough
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python常用模块相关的知识,希望对你有一定的参考价值。
time模块
time.time() # 时间戳:1487130156.419527 time.strftime("%Y-%m-%d %X") #格式化的时间字符串:\'2017-02-15 11:40:53\' time.localtime() #本地时区的struct_time time.gmtime() #UTC时区的struct_time
时间戳 与 struct_time对象的相互转换
time.localtime(1473525444.037215) #时间戳到struct_time对象 time.mktime(time.localtime()) #struct_time对象到时间戳
时间字符串 与 struct_time对象的相互转换
time.strptime(\'2007-12-1 2-3-4\',\'%Y-%m-%d %H-%M-%S\') #字符串到struct_time对象 time.strftime("%Y-%m-%d %X", time.localtime()) #struct_time 到字符串
datetime模块
这个应该更强大的time模块
datetime.date 代表年月日,datetime.time代表时分秒,datetime.datetime代表年月日时分秒
时间加减
a = datetime.datetime.now()
datetime.datetime.now()-a > datetime.timedelta(days=30)
三者都具有差不多的函数。主要功能
datetime.datetime.fromtimestamp(time.time()) #1)时间戳到datetime.datetime对象 datetime.timedelta:datetime.datetime.now() + datetime.timedelta(hours=3) #2)时间加减对象,当前时间+3小时 datetime.datetime.now().replace(minute=3,hour=2). #3)时间替换
sys模块
sys.path.append sys.stdout sys.stderr sys.stdin 三流 sys.modules[__name__] 获得本模块
random模块
random.random() #(0,1)----float 大于0且小于1之间的小数 random.randint(1,3) #[1,3] 大于等于1且小于等于3之间的整数 random.randrange(1,3) #[1,3) 大于等于1且小于3之间的整数 random.choice([1,\'23\',[4,5]])#1或者23或者[4,5] random.sample([1,\'23\',[4,5]],2)#列表元素任意2个组合 random.uniform(1,3) #大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌"
os模块
os模块是与操作系统交互的一个接口 os.urandom(32) #获得32字节的随机数,字节类型 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.makedirs(\'dirname1/dirname2\') #可生成多层递归目录 os.removedirs(\'dirname1\') # 若目录为空,则删除,并递归到下一级目录,如若也为空,则删除,依此类推 os.mkdir(\'dirname\') # 生成单级目录;相当于shell中mkdir dirname os.rmdir(\'dirname\') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir(\'dirname\') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove(‘filepath’) # 删除一个文件 os.rename("oldname","newname") # 重命名文件/目录 os.stat(\'path/filename\') # 获取文件/目录信息 os.name #输出字符串指示当前使用平台。win->\'nt\'; Linux->\'posix\' os.system("bash command") # 运行shell命令,直接显示 os.path.abspath(path) # 返回path规范化的绝对路径 os.path.split(path) # 将path分割成目录和文件名二元组返回 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) # 返回path最后的文件名。若path以/或\\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) # 如果path是绝对路径,返回True os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) #返回path的大小 注意:os.path.getsize() 和 f.seek(0,2) f.tell() 和os.stat(path).st_size 的结果相同
os.walk(\'dir_path\') # 详细用法。os.walk()常用于获取非执行目录的绝对路径,os.path.abspath(),只是将文件名加上当前目录路径
如何获得一个路径下面所有的文件路径:
import os path = r\'C:\\Users\\Administrator\\Desktop\\file\' for dirpath,dirnames,filenames in os.walk(path): for filename in filenames: print(os.path.join(dirpath,filename))
optparse模块
比sys.argv更好的参数处理
op = optparse.OptionParser() op.add_option(\'-s\',\'--server\',dest=\'server\') op.add_option(\'-p\',\'--port\',dest=\'port\') options, args = op.parse_args() #传入完成,做解析
注意:options不是字典 option[\'server\']会报错,取值应该是options.server
外部传参例子:
python ftpserver.py -s 127.0.0.1 -p 8080
输出:
options: {\'server\':\'127.0.0.1\',\'port\':\'8080\'}
args :[] #没有定义绑定的信息。
shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(open(\'old.xml\',\'r\'), open(\'new.xml\', \'w\')) #将文件内容拷贝到另一个文件中: shutil.copyfile(\'f1.log\', \'f2.log\') #拷贝文件,目标文件无需存在 shutil.copymode(\'f1.log\', \'f2.log\') #拷贝权限。内容、组、用户均,不变目标文件必须存在 shutil.copystat(\'f1.log\', \'f2.log\') #拷贝状态的信息,包括:mode bits, atime, mtime, flag,s目标文件必须存在 shutil.copy(\'f1.log\', \'f2.log\') #拷贝文件和权限 shutil.copy2(\'f1.log\', \'f2.log\') #拷贝文件和状态信息 shutil.copytree(\'folder1\', \'folder2\', ignore=shutil.ignore_patterns(\'*.pyc\', \'tmp*\')) #递归的去拷贝文件夹:目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除 shutil.rmtree(\'folder1\'),#删除非空文件夹 shutil.move(\'folder1\', \'folder3\') # 递归的去移动文件,它类似mv命令,其实就是重命名 ret = shutil.make_archive("/tmp/data_bak", \'gztar\', root_dir=\'/data\') #创建压缩包并返回文件路径,例如:zip、tar: #将 /data下的文件打包放置 /tmp/目录 #pyhton中含有对解压操作的两个模块:zipfile,tarfile#
json模块、pickle模块
这两个类都序列化用
json强大在可以在任何语言的数据交换。不能传输类,只能传输基本类型
json.dumps(xx) #转化为json字符串、参数可以是字典、列表、元组、基本数据类型 json.loads(xx) #传入json字符串,还原为原来的数据,和eval不同的是,eval侧重于语句,eval(\'1+1\')可以执行,json则可以跨语言,
-----------------------------------------------------------------------------------------
json.dumps(books, default=lambda o: o.__dict__) . # 将对象转化为对象内部的字典,有递归效果
--------------------------------------------------------------------------------------------
#扩展json序列化引擎类,序列化datetime对象
class CJsonEncoder(json.JSONEncoder): def default(self, obj): #if isinstance(obj, datetime): #return obj.strftime(\'%Y-%m-%d %H:%M:%S\') if isinstance(obj, datetime.date): return obj.strftime(\'%Y-%m-%d %H:%M:%S\') else: return json.JSONEncoder.default(self, obj) import json import datetime a = datetime.datetime.now() print(a) b = json.dumps(a,cls=CJsonEncoder) print(b)
附:django序列化(专门用于序列化django的models对象)
from django.core import serializers ret = models.BookType.objects.all() data = serializers.serialize("json", ret)
pickle只能在python与python之间的交换,但什么都可以支持,类,函数啊,函数只传递地址,不传递函数体,没多大意义
注意: 使用pickle模块,打开文件时需要\'wb\')模式,因为pickle.dumps(xx)#转化为字节
shelve模块
也是序列化模块,操作为{key:{}}形式
import shelve f=shelve.open(r\'sheve.txt\') f[\'stu1_info\']={\'name\':\'egon\',\'age\':18,\'hobby\':[\'piao\',\'smoking\',\'drinking\']} f[\'stu2_info\']={\'name\':\'gangdan\',\'age\':53} f[\'school_info\']={\'website\':\'http://www.pypy.org\',\'city\':\'beijing\'} print(f[\'stu1_info\'][\'hobby\']) f.close()
hashlib模块
hashlib在3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值
扩展:hash算法特点
1.加密不可逆
2.只要传入的内容一样,得到的hash值必然一样
3,只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
普通用法:
m=hashlib.md5() m.update(\'helloalvin\'.encode(\'utf8\')) #只能传入字节 m.hexdigest() #92a7e713c30abbb0319fa07da2a5c4af
注意:update内部有一个排他集合,会将所有分批传入的数据一起计算。所以如果要分开一个数据一个数据地加密,一定要重新初始化加密算法对象。
防止撞库,对加密算法中添加自定义key再来做加密:
hash = hashlib.sha256(\'898oaFs09f\'.encode(\'utf8\')) #添加自己的key,然后初始化 hash.update(\'alvin\'.encode(\'utf8\')) hash.hexdigest()#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
base64模块
双向可解的加密
base64.b64encode(\'123456\'.encode(\'utf8\')) #\'MTIzNDU2\' base64.b64decode(\'MTIzNDU2\'.encode(\'utf8\')) #\'123456\'
hmac
加入自定义秘钥生成唯一字节流
secret_key = b\'qazwsx123\' msg = os.urandom(32) h=hmac.new(secret_key,msg) #使用随机生成的msg对secret_key加密 digest=h.digest() #产生加密结果 hmac.compare_digest(digest,respone) #比较字节是否相等
configparser模块
操作配置文件。
配置文件的格式
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v1
config = configparser.ConfigParser() #1.必须操作,创建对象
取值:
config.read(\'a.cfg\') #像文件一样首先打开 res=config.sections() #查看所有的标题:[\'section1\', \'section2\'] options=config.options(\'section1\') #查看标题section1下所key=value的key组成的列表: val=config.get(\'section1\',\'user\') #取出指定section的指定键的值 #注意,get还有其他‘子类’函数,适用于取出特定类型,就是简化取出之后的类型转换步骤
写(改):
config.remove_section(\'section2\') #删除整个节section2 config.remove_option(\'section1\',\'k1\') #删除节下面的指定键值对 config.add_section(\'egon\') #添加一个标题: config.set(\'egon\',\'name\',\'egon\') #在标题egon下添加name=egon,age=18 config.write(open(\'a.cfg\',\'a+\')) #写入文件
判断
config.has_section(\'section1\') #判断有指定节 config.has_option(\'section1\',\'\') #判断节下面是否有
用处:
1)程序调试
2)了解软件程序运行情况,是否正常
3)软件程序运行故障分析与问题定位
4)还可以用来做用户行为分析,如:分析用户的操作行为、类型洗好、地域分布以及其它更多的信息,由此可以实现改进业务、提高商业利益。
功能有设置输出日志的等级、日志保存路径、日志文件回滚等;
相比print,其可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息;
日志级别
默认级别为warning,默认打印到终端,低于级别的日志不输出 CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10 NOTSET = 0 #不设置
配置
logging.basicConfig()函数中通过具体参数来更改logging模块默认行为。 #这是全局配置,针对所有logger有效 #并且这个配置比较低级, #常用两者之一,有stream参数就不能设置filename,反过来也是 logging.basicConfig(level=logging.DEBUG,stream=std.__stdout__) logging.basicConfig(level=10,filename=\'log.log\')
Formatter,Handler,Logger,Filter对象
logger:产生日志的对象 Filter:过滤日志的对象,一般不用 Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端 Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式 #1.logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出 logger=logging.getLogger(__file__) #2、Filter对象:不常用,略 #3、Handler对象:接收logger传来的日志,然后控制输出 h1=logging.FileHandler(\'t1.log\') #打印到文件 h3=logging.StreamHandler() #打印到终端 #4、Formatter对象:日志格式 formmater1=logging.Formatter(\'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s\',datefmt=\'%Y-%m-%d %H:%M:%S %p\',) formmater3=logging.Formatter(\'%(name)s %(message)s\',)
为Handler对象绑定格式
h1.setFormatter(formmater1)
h3.setFormatter(formmater3)
将Handler关联logger
logger.addHandler(h1)
logger.addHandler(h3)
设置等级
logger.setLevel(10) logger.debug(\'debug\') logger.info(\'info\') logger.warning(\'warning\') logger.error(\'error\') logger.critical(\'critical\')
自定义的logger类,用于辅助其他类(self.logger=PluginLogger())
import logging
import os
from conf import setting
class Log(object):
__instance = None
def __init__(self):
self.error_log_path = setting.ERROR_LOG_PATH
self.run_log_path = setting.RUN_LOG_PATH
self.error_log = None
self.run_log = None
self.__init_error_log()
self.__init_error_log()
def __new__(cls, *args, **kwargs):
if not cls.__instance:
cls.__instance = object.__new__(cls, *args, **kwargs)
return cls.__instance
def __check_path_exists(self, file_path):
if not os.path.exists(file_path):
raise Exception(\'%s not exists\' % file_path)
def __init_error_log(self):
self.__check_path_exists(self.error_log_path)
logger = logging.Logger(\'error_log\', logging.ERROR)
h = logging.FileHandler(self.error_log_path, \'a\', encoding=\'utf8\')
fmt = logging.Formatter(fmt="%(asctime)s - %(levelname)s : %(message)s")
h.setFormatter(fmt)
logger.addHandler(h)
self.error_log = logger
def __init_run_log(self):
self.__check_path_exists(self.run_log_path)
logger = logging.Logger(\'run_log\', logging.INFO)
h = logging.FileHandler(self.run_log_path, \'a\', encoding=\'utf8\')
fmt = logging.Formatter(fmt="%(asctime)s - %(levelname)s : %(message)s")
h.setFormatter(fmt)
logger.addHandler(h)
self.run_log = logger
def log(self, msg, status=True):
if status:
self.run_log.info(msg)
else:
self.error_log.error(msg)
logger = Log()
自定义配置
一般正规的开发,不会使用以上的对象进行配置。
logging标准模块支持三种配置方式: dictConfig,fileConfig,listen。其中,dictConfig是通过一个字典进行配置Logger,Handler,Filter,Formatter;fileConfig则是通过一个文件进行配置;而listen则监听一个网络端口,通过接收网络数据来进行配置。
了解logger的继承,用于filter对象
logger1=logging.getLogger(\'abc\') logger2=logging.getLogger(\'abc.freedom\') logger3=logging.getLogger(\'abc.freedom.child2\')
通过父名.子名继承,名字自定义,继承后,父logger输出时,子对象也会输出一份相同的,但子对象也可以自己另外输出。
django的配置说明
\'file\': { \'level\': \'INFO\', \'class\': \'logging.handlers.TimedRotatingFileHandler\', # 用时间切割 \'when\': "D", #D 表示天 \'interval\': 1, #1 表示每1天,每天切割一次日志文件 "backupCount": 3, \'formatter\': \'default\', \'filename\': os.path.join(BASE_DIR, \'logs\', \'dbops.log\') },
re模块
正则表达式深入用法
1.sub将指定字母替换为大写,若使用lambda函数形式,记得传入的是匹配到的正则结构,要使用group提出
re.sub(r\'(a)\',lambda x:x.group(0).upper(),\'caca\')
2.使用|方式,要在()阔住,并且在阔号最前面加入?:
re.findall(\'compan(?:y|ies)\',\'Too many companies have gone bankrupt, and the next one is my company\')
3.正则函数一般有一个参数flags可以传入正则标志,例如忽略大小写,还有正则默认不匹配换行符,标志设置为re.S就适用于有换行的字 符串,注意的是换行符无需在正则里写出来
4.re.split,普通的字符串split只能按照一个传入的字符串匹配,但这个可按照多个
re.split(\'[ab]\',\'abcd\') #[\'\', \'\', \'cd\'],先按\'a\'分割得到\'\'和\'bcd\',再对\'\'和\'bcd\'分别按\'b\'分割 re.split(\'[ab]\',\'acaccccbzzzafreedom\') [\'\', \'c\', \'cccc\', \'zzz\', \'freedom\']
5.sub函数还有个count参数,指定替换多少次
re.sub(\'a\',\'A\',\'alex make love\',1) Alex make love
6.re.compile可以实现正则的重用,并且速度快于用字符串保存的正则
obj=re.compile(\'\\d{2}\') obj.search(\'abc123eeee\').group()) #12 obj.findall(\'abc123eeee\')) #[\'12\'],重用了obj
7.阔号后面配频率符,少用。因为各种re的函数的处理都不同
看这个例子:(\\d)+相当于(\\d)(\\d)(\\d)(\\d)...,是一系列分组
print(re.search(\'(\\d)+\',\'123\').group()) #group的作用是将所有组拼接到一起显示出来 print(re.findall(\'(\\d)+\',\'123\')) #findall结果是组内的结果,且是最后一个组的结果
8.group(0)是返回匹配到的全部,group(1)开始就是返回正则表达式阔号的值。默认group()便是group(0)
9.注意,match,从第一个字母查找,满足所编写的正则后便返回。
re.match(r\'ddd\',\'ddd32\') <_sre.SRE_Match object; span=(0, 3), match=\'ddd\'>
10.?:这个代表不捕获分组
比较(X)和(?:X),前者是捕获分组,后者不捕获,区别在于正则表达式匹配输入字符串之后所获得的匹配的(数)组当中没有(?:X)匹配的部分;
比如
注意:这个是javascript var m = "abcabc".match(/(?:a)(b)(c)/) 结果 ["abc", "b", "c"] var m = "abcabc".match(/(a)(b)(c)/) 结果 ["abc", "a", "b", "c"]
11.正则如果有冲突的话,前面加上\'\\\',而r前缀的作用是拟制\\n \\t之类的转义字符,与冲突字符无关
In [30]: re.match(r\'www\\.\',\'www.\') Out[30]: <_sre.SRE_Match object; span=(0, 4), match=\'www.\'>
12.正则的(?=rex),匹配指定正则的‘前面部分’的‘预扫描’
#预扫描就是先走一遍,找到?=中的正则,然后返回匹配的结果。剩下的正则,还是从‘预扫描’正则的前一个正则处理完的位置开始。
re.match(r\'(?=123|456)(?=123abc)(?=123abcfree)123abcfree\',\'123abcfree\') Out[98]: <_sre.SRE_Match object; span=(0, 10), match=\'123abcfree\'>
#预匹配经常用于这样的场景,例如:密码需要包含大小写字母,数字和下划线
re.match(r\'(?=.*[a-z])(?=.*[A-Z])(?=.*[0-9])(?=.*_).*\',\'fdfds2121_FSD\')
Out[111]: <_sre.SRE_Match object; span=(0, 13), match=\'fdfds2121_FSD\'>
uuid模块
用于生成唯一标志符
uuid1()——基于时间,由MAC地址、当前时间戳、随机数生成。可以保证全球范围内的唯一性
functools模块
Python装饰器(decorator)在实现的时候,被装饰后的函数其实已经是另外一个函数了(函数名等函数属性会发生改变),为了不影响,Python的functools包中提供了一个叫wraps的decorator来消除这样的副作用。写一个decorator的时候,最好在实现之前加上functools的wrap,它能保留原有函数的名称和docstring。
from functools import wraps def hello(fn): @wraps(fn) def wrapper(): print "hello, %s" % fn.__name__ fn() print "goodby, %s" % fn.__name__ return wrapper
subprocess模块
打开一个子进程执行shell
res=subprocess.Popen(\'dir\',shell=True,stdout=subprocess.PIPE) #shell=True意味着用shell命令形式执行第一参数\'dir\',stdout参数指定将结果放到管道里面。 res.stdout.read() #从管道中读出数据,数据为二进制
res=subprocess.getoutput(\'ver\') #直接获取cmd命令的返回值
常用做法:将输入流,输出流,错误流都定义到管道
res=subprocess.Popen(\'ls\',shell=True,stdout=subprocess.PIPE,stdin=subprocess.PIPE,stderr=subprocess.PIPE) # 注意,虽说是这么写,但是其实是不同的管道。
struct模块
数据打包为二进制bytes的模块
例如,用使用四个字节表示2007这个数字。常用于拼接网络传输的应用层协议头
注意的是,因为常用于网路传输,网络传输后不是解码,还是调用unpack取出
a=struct.pack(\'b\',-1) struct.unpack(\'b\',a) #返回的是元祖
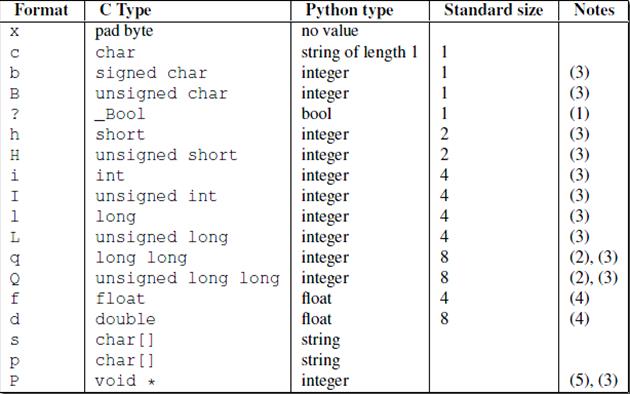
xlrd模块
不是内置模块,请pip install xlrd
操作excel文件,xlsx等
data = xlrd.open_workbook(\'demo.xls\') #打开excel
data.sheet_names() #查看文件中包含sheet的名称
#得到第一个工作表,或者通过索引顺序 或 工作表名称 table = data.sheets()[0] table = data.sheet_by_index(0) table = data.sheet_by_name(u\'Sheet1\')
#获取行数和列数 nrows = table.nrows ncols = table.ncols
#获取整行和整列的值(数组)