Python基础
Posted 夕晖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础相关的知识,希望对你有一定的参考价值。
说明
本文翻译自斯坦福开放课程【编程范式】的系列课件,有删改。
本系列会持续更新,预计一周发布1到2篇。
如有意见/建议或是存在版权问题,欢迎园友指正。
转载无需通知本人,但请注明出处,谢谢!
速成课
你可以和Python解释器对话,你输入表达式,它返回计算结果。多做几次就产生了一个清晰的读取-求值-输出循环。
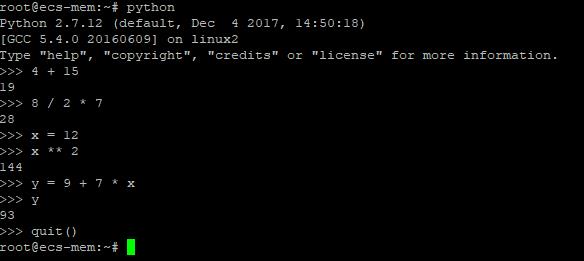
Python并不要求每个表达式都打印一个结果--赋值语句就不会在屏幕上打印任何东西。虽然不支持++和--操作,但是Python有一个内置方法**可以用来求冥。在命令行里输入python可以开启交互模式,试着聊会儿天,当你决定退出的时候按下Control-D。
布尔值
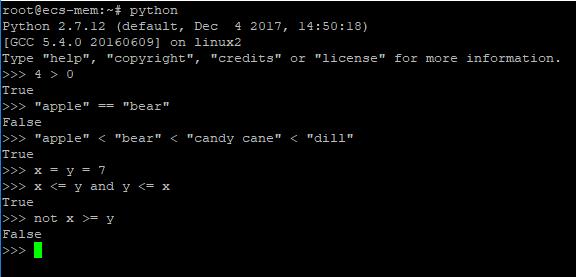
布尔常量包括True和False,6个关系操作符(>、 <、 ==、 !、 ||、 &&)能作用于所有基本单元,可以用表现力更强的字符not、or和and代替!,||,和&&。你也可把关系表达式连在一起,像min < mean < max这样的写法完全行的通。
整数
整数和你想的一样,较小的数占4个字节,超级大的数则以长整型的方式存在,没有内存限制。
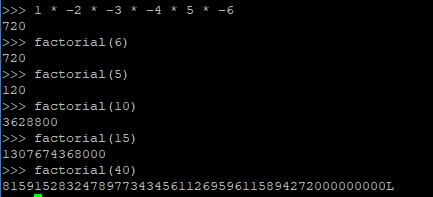
当数很大的时候,别忘了数字结尾有个L。(我自己定义了factorial函数,它并不是内置的,很快我们就知道怎样定义函数了。)
字符串
字符串的截取,连接和重复等操作都是支持的。
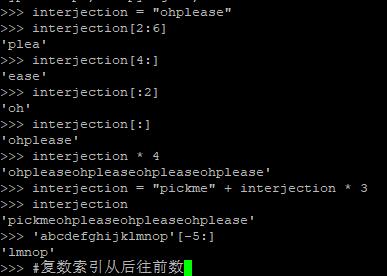
[start:stop]这种新奇的表达式就是切片。[2:6]表示截取子字符串:从位置2开始,到位置5结束。开始索引的默认值是0,结束索引的默认值是字符串长度。两个都不填则返回整个字符串。(Python不需要区分字符和字符串,使用字符时可以把它视作单字符字符串。)
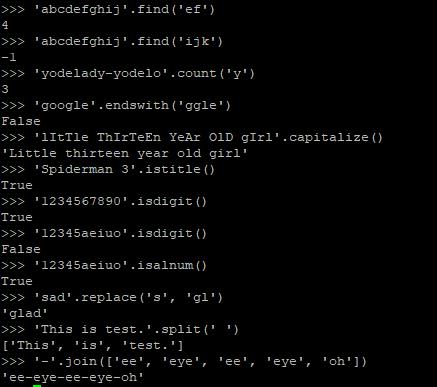
字符串确实是对象,并且有很多方法。你应该猜到这些方法借鉴了其他的面向对象语言。你会猜到一些像find、startswith、endswith,replace等等之类的方法,因为一个string类没有这些方法就太无力了。Python为string提供了一堆附加方法,令它在脚本和Web领域更有用--像capitalize、split、join、expandtabs,和encode等。这里给出一些例子:
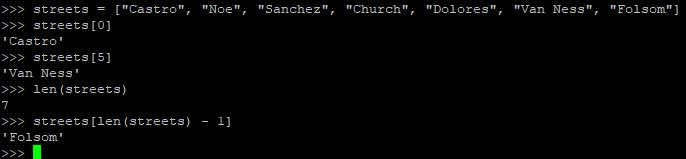
列表和元组
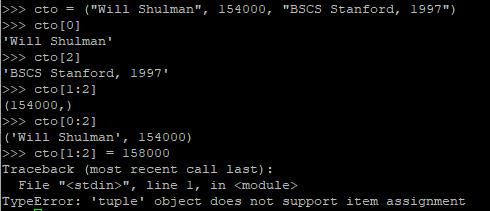
Python有两种有序容器:lists(可读可写)和tuples(不可变、只读)。列表用方括号括起来,元组用圆括号。下面给出一些例子。
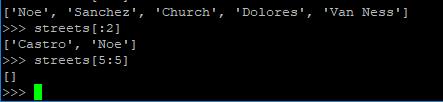
string的slicing操作也能用在列表上:
你可以用索引标记出一个列表区间,然后用一个新的列表片段替换掉原来的内容:
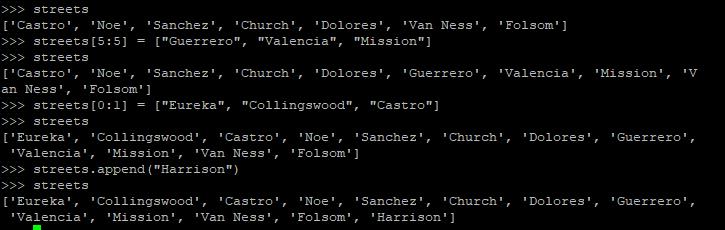
第一个例子中,5和6之间的空白区域应该被等号右侧的list常量替换掉。第二个例子中street[0:1],即子列表[\'Castro\'],应该被[\'Eureka\',\'Collingswood\',\'Castro\']覆盖掉。当然,有一个append方法也是很正常的。
注意:列表不要求所有数据都是一种类型。你可以用列表保存一条记录,只要你能搞清楚每个位置放置的数据表示什么含义。

列表有个更保守的兄弟叫元组,可以理解为把方括号换成圆括号的列表常量,基本上没法修改。元组支持切片,但不支持插入:
定义函数
下面是gatherDivisors函数。它包括了if判断,for循环迭代,更重要的是,它表明了代码块是靠着空格和缩进来划分的。
# Function: gatherDivisors # --------------------------- # Accepts the specified number and produces # alist of all numbers that divide evenly # into it. def gatherDivisors(num): """Synthesizes a list of all the positive numbers that evenly divide into the specified num. """ divisors = [] for d in xrange(1, num/2 + 1): if(num % d == 0): divisors.append(d) return divisors
语法有些似曾相识。我们并没有忘记写分号(就算你把分号加进去,解释器也会忽视掉这个小错误)。你可能注意到这个实现的某些部分缩进了一次,两次,甚至三次。缩进(以一个制表符或四个空格符的形式存在)使得谁包括谁的层次关系清晰无比。你可能注意到def,for,和if声明后边加了冒号:表明这个声明可能会覆盖一大片代码块。
注意一下几点:
- #符号用来注释整行,我猜你已经看出来了。
- 没有任何变量--无论参数还是局部变量--是强类型的。Python有整数、浮点数,字符串等概念。但它不需要你知道这些数据类型会被存储在特殊的变量中。标识符可以是任意数据类型,也不被强制永远只是一种类型。比如一个data变量可以等于5,再等于“five”,然后再等于[5,"five",5,[5]],虽然做这种事情没什么好处,Python支持这个。
- 三重双引号内的字符串可以理解成允许换行的字符串常量,如若字符串常量是def后面第一个表达式,它会被认定为一种解释性文本--和注释不同,它被展示给使用者,告诉他函数是做什么的。
- for循环和其他语言不同。不同于用一个专门的整数计数,for循环通过一个迭代对象来实现重复。迭代子(也就是gatherDivisors函数中的d)绑定了迭代对象中的每个元素,直到所有元素都遍历了一遍。迭代对象有多种表现形式,list最为常见。我们也可以迭代字符串,或者sequences(实际上就是只读的列表),或者dictionaries(Python版的C++hash_map)。
模块化
当你处理一个规模大到需要把程序拆分的问题,你可能想把函数放在文件里--文件作为模块(有点像Java里的packages和C++里的libraries)来互相调用。
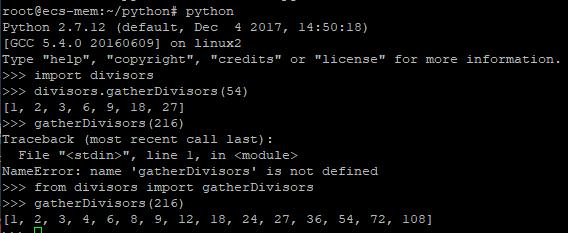
我们只要把之前的gatherDivisors函数写在一个叫divisors.py的文件里。然后在存放divisors.py的目录下边儿启动python,接着你可以导入divisors模块,你也可以导入模块内部的函数。看:
如果你想把你写的所有代码都设计成独立的脚本来运行--也就是一个独立的可解释程序--那么你可以把所有有意义的函数捆在一起放在一个单独的文件里,保存这个文件,然后把这个文做成可执行的东西(比如,chmod a+x narcissist.py)。
这里是一个简明的程序,打印出前15(调用者提供的数字)个水仙花数(如果你忘记水仙花数的定义,不妨谷歌一下):
#!/usr/bin/env python # encoding: utf-8 # 这是一个简单的打印脚本 # 前n个水仙花数, n从命令行传入 import sys def numDigits(num): """返回num的位数, 从0开始但是不包括0。""" if (num == 0):return 1 digitCount = 0 while(num > 0): digitCount += 1 num /= 10 return digitCount def isNarcissistic(num): """只有当num是水仙花数时才返回True。""" originalNum = num total = 0 exp = numDigits(num) while(num > 0): digit = num % 10 num /= 10 total += digit ** exp return total == originalNum def listNarcissisticNumbers(numNeeded): """查找并且打印出前\'numNeeded\'个水仙花数。""" numFound = 0 numToConsider = 0 print "这是前 %d 个水仙花数。" % numNeeded while(numFound < numNeeded): if (isNarcissistic(numToConsider)): numFound += 1 print numToConsider numToConsider += 1 print "Done!" def getNumberNeeded(): """解析命令行参数来决定打印几个水仙花数。""" numNeeded = 15 if len(sys.argv) > 1: try: numNeeded = int(sys.argv[1]) except: print "No-integral argument encountered... using default." return numNeeded listNarcissisticNumbers(getNumberNeeded())
上面的模块有五个表达式。前四个是def表达式--函数定义--作用是把函数的名字和一些代码绑定在一起。第五个表达式是函数调用,求值后会产生我们感兴趣的输出。它依赖于以下事实:前四个表达式先于它发生,所以当Python环境设法调用listNarcissisticNumbers的时候,listNarcissisticNumbers和getNumbersNeeded已经有了含义,并且可以通过代码跳转过去。
快速排序和列表推导
下面是一个熟悉的排序算法,说明了原位列表初始化技术。
# 说明了怎样使用列表切片、列表连接和列表推导来做一些有意义的事情。 # 这个版本的快速排序效率不是最好的,因为各级都需要执行两次而不是一次。 def quicksort(sequence): """快速排序的经典实现用到了列表推导,并且假定传统的关系操作有效。而这种特殊实现的主要缺陷是
需要排序两次而不是一次。""" if(len(sequence) == 0):return sequence front = quicksort([le for le in sequence[1:] if le <= sequence[0]]) back = quicksort([gt for gt in sequence[1:] if gt > sequence[0]]) return front + [sequence[0]] + back
>>> from quicksort import quicksort >>> quicksort([5, 3, 6, 1, 2, 9]) [1, 2, 3, 5, 6, 9] >>> quicksort([\'g\', \'b\', \'z\', \'k\', \'e\', \'a\', \'y\', \'s\']) [\'a\', \'b\', \'e\', \'g\', \'k\', \'s\', \'y\', \'z\']
[le for le in sequence[1:] if le <= sequence[0]],这个被传给第一个递归调用作为参数的东西,叫做列表推导。它只有一行,可以用一堆数据快速创建一个列表。列表推导可以包括任意个迭代,比如:
>>> [(x, y) for x in xrange(1, 3) for y in xrange(4, 8)] [(1, 4), (1, 5), (1, 6), (1, 7), (2, 4), (2, 5), (2, 6), (2, 7)] >>> [(x, y, z) for x in range(1, 5) ... for y in range(1, 5) ... for z in range(1, 6) if x < y <= z] [(1, 2, 2), (1, 2, 3), (1, 2, 4), (1, 2, 5), (1, 3, 3), (1, 3, 4), (1, 3, 5), (1, 4, 4), (1, 4, 5), (2, 3, 3), (2, 3, 4), (2, 3, 5), (2, 4, 4), (2, 4, 5), (3, 4, 4), (3, 4, 5)]
下面是一个更加严肃的脚本,有点像Unix系统下的find程序。当给出一个路径和一个文件名时,我们的find程序会在该路径下查找和该文件名同名的文件,并列出查找结果的完整路径。
# !/usr/bin/env python # encoding: utf-8 # # 对Unix下find指令的简单模仿,在子树下搜索一个文件名,字树和文件名都是参数。 # 因为python是脚本语言,又对系统导航和正则表达式提供相当好的支持, # 所以python非常适合处理这种类型的任务 from sys import argv from os import listdir from os.path import isdir, exists, basename, join def listAllExactMatches(path, filename): """列出和给定文件名匹配的所有文件的递归函数""" if basename(path) == filename: print "%s" % path if not isdir(path): return dirlist = listdir(path) for file in dirlist: listAllExactMatches(join(path, file), filename) def parseAndListMatches(): """解析命令行,验证是否有三个参数,确保给定的路径确实存在, 最后在给定路径为根的文件树下检索文件""" if(len(argv) != 3): print "使用:查找 <文件路径> <文件名>" return directory = argv[1] if not exists(directory): print "给定的路径\\"%s\\"不存在。" % directory return if not isdir(directory): print "\\"%s\\" 存在, 但它不是一个路径。" % directory filename = argv[2] listAllExactMatches(directory, filename) parseAndListMatches()
下面是用find脚本查找到的find.py文件列表:
root@ecs-mem:~/python# python find.py ~ find.py /root/demo/find.py /root/python/find.py
from/import声明告诉你函数来自哪里。大部分函数是不言自明的,其他东西则取决于你对脚本运行机制的了解。
- basename返回了path的最后一部分:
- Users/jerry/code/rsg/random.c 会返回 random.c
- /usr/class/cs107/assignments/assn-1-rsg/Makefile 会返回 Makefile
- /usr 会返回 /usr
- join返回一个或多个路径的连接,这些路径使用操作系统的路径分隔符,如果其中有绝对路径,那么它之前的路径参数会被忽略:
- join(\'/usr/class/cs107\', \'bin\' , \'submit\') 返回 ‘/usr/class/cs107/bin/submit’
- join(\'/usr/ccs/\', \'/usr/bin\',\'ps\') 返回 ‘/usr/bin/ps’
- 从os和os.path模块引入的其他函数应该是不言自明的。
我为什么要用Python?因为有些事就应该让脚本语言来做,再加上对系统导航和正则匹配的支持,Python是完美的选择。
获取和解析XML
# !/usr/bin/env python # encoding: utf-8 from xml.dom import * from xml.dom.minidom import parse from urllib2 import urlopen from sys import argv # 整个程序说明了Python对XML的支持是极好的 # xml.dom.minidom模块提供了解析方法,知道怎样利用网络连接获取XML, # 在内存里构建一个树状文档 # xml.dom包定义了Document类和所有的帮助类 # document是树状的 def listAllWeathers(rssURL): """列出我国所有省会级行政区的天气情况""" conn = urlopen(rssURL) xmldoc = parse(conn) cities = xmldoc.getElementsByTagName("city") for city in cities: cityname = city.getAttribute("cityname") windState = city.getAttribute("windState") print("%s的天气情况是:%s" % (cityname.encode(\'utf-8\') , windState.encode(\'utf-8\'))) def getURL(): """如有没有目标URL,使用一个默认值""" defaultURL = "http://flash.weather.com.cn/wmaps/xml/china.xml" URL = defaultURL if len(argv) == 2: URL = argv[1] return URL listAllWeathers(getURL())
我为什么要用Python?因为Python的库很现代化、复杂度也足够支撑当前的Web技术需求--像HTTP,XML,SOAP,SMTP,和FTP。作业4需要两个完整的.h和.c文件来管理URL和URL连接。Python只用urlopen就能对付它们。
字典(Dictionaries)
现在我们知道的足够多了,下面让我们探讨Python数据结构的圣杯:字典。
Python中的字典有点像哈希表,键是字符串,值可以是我们希望的任何东西。下面进入交互界面,用一个简单的字典实例来模拟我成长的家庭。
>>> primaryHome = {} >>> primaryHome["phone"] = "609-786-06xx" >>> primaryHome["house-type"] = "rancher" >>> primaryHome["address"] = {} >>> primaryHome["address"]["number"] = 2210 >>> primaryHome["address"]["street"] = "Hope Lane" >>> primaryHome["address"]["city"] = "Cinnaminson" >>> primaryHome["address"]["state"] = "New Jersey" >>> primaryHome["address"]["zip"] = "08077" >>> primaryHome["num-bedrooms"] = 3 >>> primaryHome["num-bathrooms"] = 1.5 >>> primaryHome {\'num-bathrooms\': 1.5, \'phone\': \'609-786-06xx\', \'num-bedrooms\': 3, \'house-type\': \'rancher\', \'address\': {\'city\': \'Cinnaminson\', \'state\': \'New Jersey\', \'street\': \'Hope Lane\', \'number\': 2210, \'zip\': \'08077\'}}
你可以把primaryHome看做一个挤满了一大堆属性的对象。像这样逐步的构建出一个字典还不算乏味,你也可以打出整个字典常量的文本来再次初始化一个字典:
>>> vacationHome = {\'phone\': \'717-581-44yy\', \'address\': {\'city\': \'Jim\\
... Thorpe\', \'state\': \'Pennsylvania\', \'number\': 146, \'street\':\'Fawn Drive\',
... \'zip\':\'18229\'}}
>>> vacationHome["address"]["city"]
\'JimThorpe\'
字典通常以程序化的方式建立而不是手动输入。在我们动手编程之前,我可以给你看下Python版的随机语句生成器是什么样子的,随机语句的组成元素以字典的形式写死在文件里:
# !/usr/bin/env python # encoding: utf-8 # 这个脚本能从写死的grammar中生成三个随机的句子。一般来说,grammar会被存放在数据文件里, # 但是说实话,它可能会被编码成序列化的字典,这样的话还要反序列化数据,感觉有点鸡肋。 import sys # 为了 sys .stdout from random import seed, choice grammar = {\'<start>\': [[\'The \', \'<object>\', \' \', \'<verb>\', \' tonight.\']], \'<object>\': [[\'waves\'], [\'big yellow flowers\'], [\'slugs\']], \'<verb>\': [[\'sigh