资深程序员带你玩转深度学习中的正则化技术(附Python代码)!
Posted python1234
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资深程序员带你玩转深度学习中的正则化技术(附Python代码)!相关的知识,希望对你有一定的参考价值。

目录
1. 什么是正则化?
2. 正则化如何减少过拟合?
3. 深度学习中的各种正则化技术:
L2和L1正则化
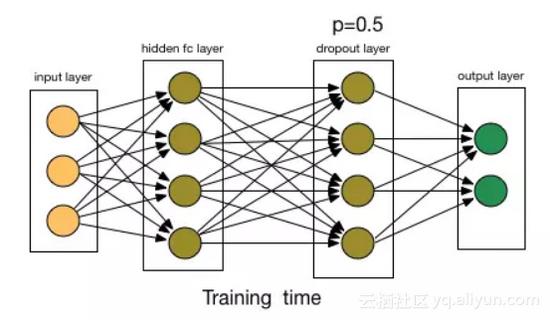
Dropout
数据增强(Data augmentation)
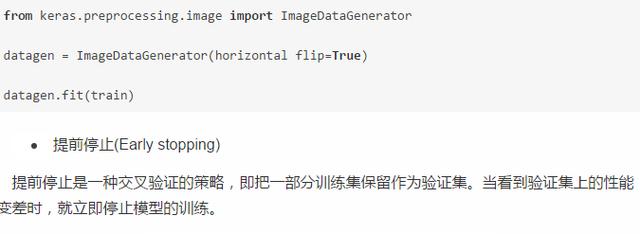
提前停止(Early stopping)
4. 案例:在MNIST数据集上使用Keras的案例研究
1. 什么是正则化?
在深入该主题之前,先来看看这几幅图:
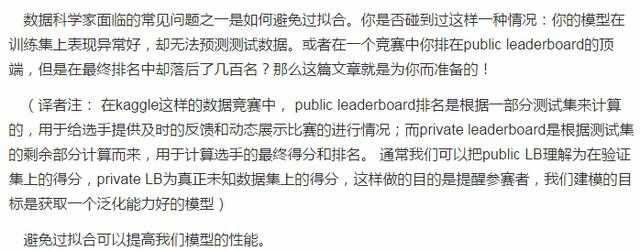
之前见过这幅图吗?从左到右看,我们的模型从训练集的噪音数据中学习了过多的细节,最终导致模型在未知数据上的性能不好。
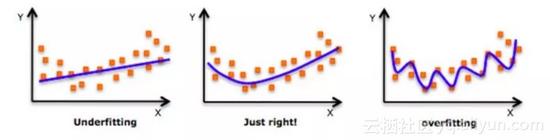
换句话说,从左向右,模型的复杂度在增加以至于训练误差减少,然而测试误差未必减少。如下图所示:

2. 正则化如何减少过拟合?
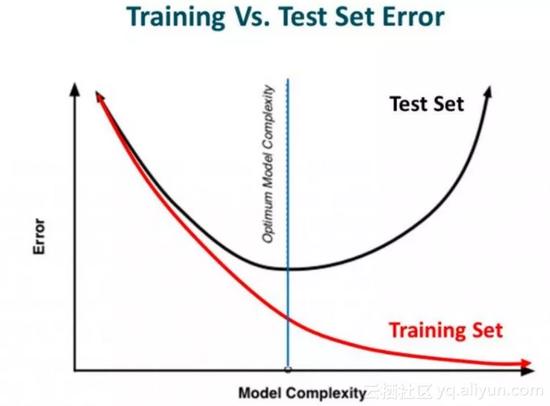
我们来看一个在训练数据上过拟合的神经网络,如下图所示:
如果你曾经学习过机器学习中的正则化,你会有一个概念,即正则化惩罚了系数。在深度学习中,它实际上惩罚了节点的权重矩阵。
假设我们的正则化系数很高,以至于某些权重矩阵近乎于0:
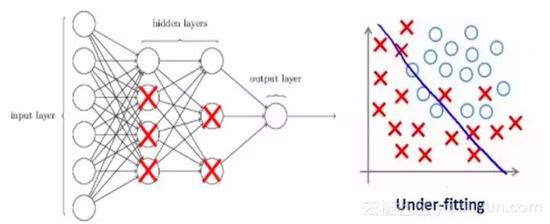
这会得到一个简单的线性网络,而且在训练数据集上轻微的欠拟合。
如此大的正则化系数并不是那么有用。我们需要对其进行优化从而得到一个拟合良好的模型,正如下图所示:


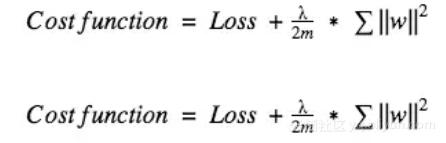
这里,lambda是正则参数。它是一个超参数用来优化得到更好的结果。L2正则化也叫权重衰减(weight decay ) ,因 为 它 强 制 权 重朝着 0 衰减(但不会 为 0)
在L1中,我 们 有:
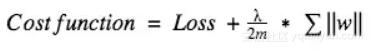
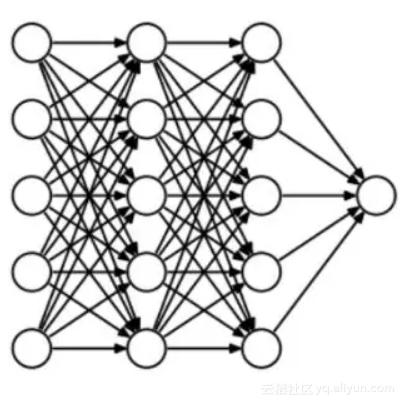
dropout做什么呢?每次迭代,随机选择一些节点,将它们连同相应的输入和输出一起删掉,如下图:
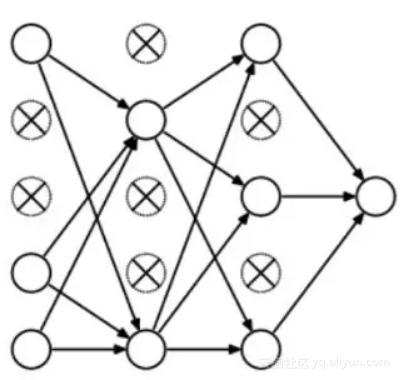
所以,每一轮迭代都有不同的节点集合,这也导致了不同的输出。它也可以被认为是一种机器学习中的集成技术(ensemble technique)。




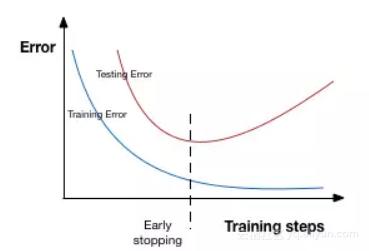

Patience表示在该数量的epochs内没有进一步的性能改进后,就停止训练。为了更好地理解,我们再看看上面的图。在虚线之后,每个epoch都会导致一个更高的验证集错误。因此,在虚线之后的5个epoch(因为我们设置patience等于5),由于没有进一步的改善,模型将停止训练。
注意:可能在5个epoch之后(这是一般情况下为patience设定的值)模型再次开始改进,并且验证集错误也开始减少。因此,在调整这个超参数的时候要格外小心。


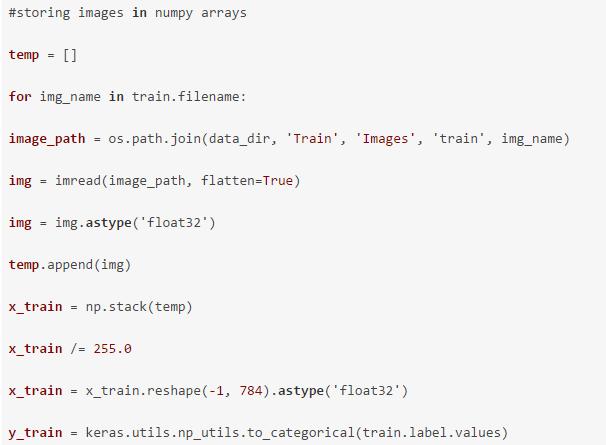
现在,加载数据。

现在拿一些图片来看看。



# import keras modulesfrom keras.models import Sequentialfrom keras.layers import Dense# define varsinput_num_units = 784hidden1_num_units = 500hidden2_num_units = 500hidden3_num_units = 500hidden4_num_units = 500hidden5_num_units = 500output_num_units = 10epochs = 10batch_size = 128model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=‘relu‘),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=‘relu‘),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=‘relu‘),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=‘relu‘),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=‘relu‘),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=‘softmax‘),])




注意这里lambda的值等于0.0001. 太棒了!我们获得了一个比之前NN模型更好的准确率。
现在尝试一下L1正则化。
## l1model = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=‘relu‘,kernel_regularizer=regularizers.l1(0.0001)),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=‘relu‘,kernel_regularizer=regularizers.l1(0.0001)),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=‘relu‘,kernel_regularizer=regularizers.l1(0.0001)),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=‘relu‘,kernel_regularizer=regularizers.l1(0.0001)),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=‘relu‘,kernel_regularizer=regularizers.l1(0.0001)),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=‘softmax‘),])model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_dat
这次并没有显示出任何的改善。我们再来试试dropout技术。
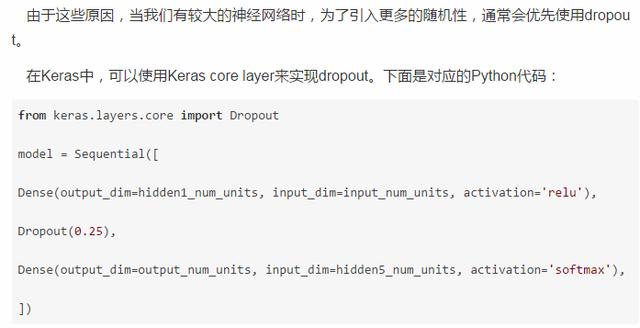
## dropoutfrom keras.layers.core import Dropoutmodel = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=‘softmax‘),])model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
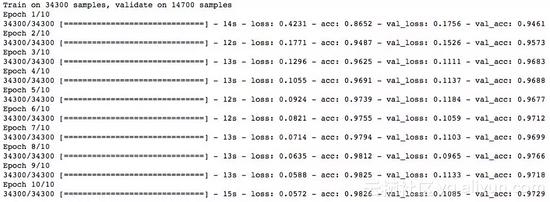
效果不错!dropout也在简单NN模型上给出了一些改善。
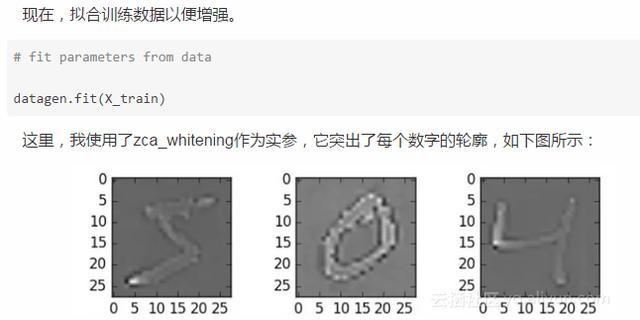
现在,我们试试数据增强。
from keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator(zca_whitening=True)# loading datatrain = pd.read_csv(os.path.join(data_dir, ‘Train‘, ‘train.csv‘))temp = []for img_name in train.filename:image_path = os.path.join(data_dir, ‘Train‘, ‘Images‘, ‘train‘, img_name)img = imread(image_path, flatten=True)img = img.astype(‘float32‘)temp.append(img)x_train = np.stack(temp)X_train = x_train.reshape(x_train.shape[0], 1, 28, 28)X_train = X_train.astype(‘float32‘)
## splittingy_train = keras.utils.np_utils.to_categorical(train.label.values)split_size = int(x_train.shape[0]*0.7)x_train, x_test = X_train[:split_size], X_train[split_size:]y_train, y_test = y_train[:split_size], y_train[split_size:]## reshapingx_train=np.reshape(x_train,(x_train.shape[0],-1))/255x_test=np.reshape(x_test,(x_test.shape[0],-1))/255## structure using dropoutfrom keras.layers.core import Dropoutmodel = Sequential([Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=‘relu‘),Dropout(0.25),Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=‘softmax‘),])model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

哇!我们在准确率得分上有了一个飞跃。并且好消息是它每次都奏效。我们只需要根据数据集中的图像来选择一个合适的实参。
现在,试一下最后一种技术——提前停止。
from keras.callbacks import EarlyStoppingmodel.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test), callbacks = [EarlyStopping(monitor=‘val_acc‘, patience=2)])

可以看到我们的模型在仅仅5轮迭代后就停止了,因为验证集准确率不再提高了。当我们使用更大值的epochs来运行它时,它会给出好的结果。你可以说它是一种优化epoch值的技术。
结语
我希望现在你已经理解了正则化以及在深度学习模型中实现正则化的不同技术。 无论你处理任何深度学习任务,我都强烈建议你使用正则化。它将帮助你开阔视野并更好的理解这个主题。


欢迎关注我的博客或者公众号,咱么一起学习:https://home.cnblogs.com/u/Python1234/ Python学习交流
欢迎加入我的千人交流学习答疑群:125240963
以上是关于资深程序员带你玩转深度学习中的正则化技术(附Python代码)!的主要内容,如果未能解决你的问题,请参考以下文章