Python中的正则表达式
Posted fangtaoa的个人博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python中的正则表达式相关的知识,希望对你有一定的参考价值。
正则表达式是一种在一段文本中提取我们我们感兴趣的一小段字符串的技术。在Python中,正则表达式有很多地方都能用到,比如Flask、Django框架中配置路由、爬虫等地方。因此学会使用正则表达式式非常有必要的,那么接下来我们就开始学习正则表达式了。
一、如何使用re模块
Python中使用re模块来进行正则匹配。封装了许多语法糖。
在写匹配规则的时候,最好以r""开头,这样可以把"\\"字符做转义。
1、匹配单个字符
".":匹配任意1个字符,除了"\\n"以外
"[ ]":匹配"[ ]"中列举的字符
"\\d":匹配数字,即从0-9,相当于[0-9]
"\\D":与"\\d"相反,匹配非数字,相当于[^0-9]
"\\s":匹配空白字符,即空格、tab键,相当于[ |\\t]
"\\S":与"\\s"相反,匹配非空白
"\\w":匹配单词字符,即a-z、A-Z、0-9、_,相当于[a-zA-Z0-9_]
"\\W":匹配非单词字符
2、匹配多个字符
{m}:匹配前一个字符出现m次
{m, n}:匹配前一个字符出现从m到n次
"*":匹配前一个字符出现0次或无限次,即可有可无,相当于{0, }
"+":匹配前一个字符出现1次或无限次,必须有一次,相当于{1, }
"?":匹配前一个字符出现1次或0次,要么有1次,要么没有,相当于:{0, 1}
3、表示边界
"^":匹配字符串的开头,注意^用于"[]"中表示取反的作用
"$":匹配字符串的结尾,
"\\b":匹配一个单词的边界
"\\B":匹配非单词边界
4、匹配分组
"|":匹配左右任意一个表达式
"(ab)":将括号中的字符作为一个分组
"\\num":引用分组num匹配到的字符,匿名分组
(?P<name>):分组起别名,有名分组
(?P=name):引用别名为name分组匹配到的字符串
二、re中重要的方法
1.match(pattern, content):从头开始匹配,如果第一个字符不符合规则,那就返回。如果匹配成功,返回一个Match对象,有group()方法。
2.search(pattern, content):和match差不多,只是,如果第一个字符不符合规则的话,还需继续往下匹配,直到结束。
3.findall(pattern, content):从头匹配到尾,匹配成功的话,返回匹配的字符串组成的列表,否则返回空列表。
4.sub(pattern, new_str/fun, content):匹配并替换,第二个参数可以是函数,把从content匹配到的字符,当做函数的参数进行处理
5.split(pattern, content):根据匹配规则进行分割字符串,然后范湖一个列表
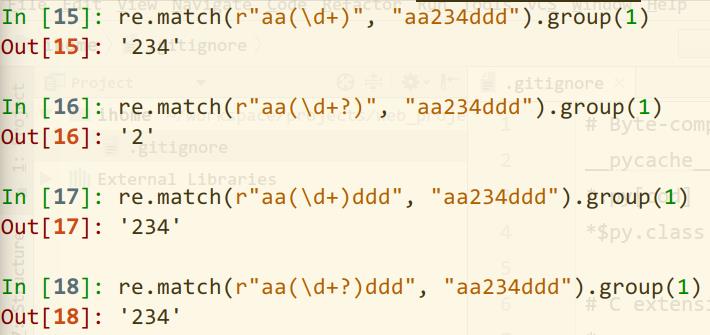
三、Python中的贪婪与非贪婪
在Python中,数量词(匹配多个字符的规则)默认是贪婪的,即总是匹配尽可能多的字符;而非贪婪则相反,总是尽量匹配少的字符。
在"*"、"?"、"+"、{m, n}等后面加上"?"可以使贪婪变为非贪婪。
注意,非贪婪是在满足匹配结果之后,从结果中进行匹配尽量少的字符。
以上是关于Python中的正则表达式的主要内容,如果未能解决你的问题,请参考以下文章